
在实际环境中测试
在生产环境中测试,无水印。
随时随地满足您的需求。
Python PDF库


在在线搜索和文档生成领域,有效性和效率至关重要。 要从网站中提取数据,并随后将其转换为专业水准的文档,就必须顺利整合强大的工具和框架。
Scrapy 和 IronPDF 这两个强大的库共同优化了在线数据的提取和动态 PDF 的创建。PDF 文件.
现在,开发人员可以毫不费力地浏览复杂的网络,并精确、快速地提取结构化数据,这要归功于 Python 中的 Scrapy,它是一个顶级的网络爬行和刮擦库。 凭借其强大的 XPath 和 CSS 选择器以及异步架构,它是任何复杂度的刮擦工作的理想选择。
相反,IronPDF for .NET 是一个功能强大的 .NET 库,支持以编程方式创建、编辑和操作 PDF 文档。 IronPDF 凭借其强大的 PDF 创建工具(包括 HTML 到 PDF 的转换和 PDF 编辑功能),为开发人员提供了制作动态、美观的 PDF 文档的完整解决方案。
本篇文章将带您了解如何顺利集成Scrapy Python我们将与 IronPdf 一起,向您展示这对动态组合如何改变网络搜刮和文档创建的方式。 我们将展示这两个库如何协同工作,以减轻复杂的工作并加快开发工作流程,从使用 Scrapy 从网络上刮取数据到使用 IronPDF 动态生成 PDF 报告。
当我们使用 IronPDF 充分利用 Scrapy 时,请来探索网络搜刮和文档生成的可能性。
Scrapy 采用异步架构,可以同时处理多个请求。 这样可以提高效率,加快网络搜索速度,尤其是在处理复杂网站或大量数据时。
Scrapy 具有强大的 Scrapy 抓取过程管理功能,如自动 URL 过滤、可配置的请求调度和集成的 robots.txt 指令处理。 开发人员可以调整抓取行为,以满足自己的需求,并保证遵守网站指南。
Scrapy 允许用户使用 XPath 和 CSS 选择器在 HTML 页面中导航和选取项目。 这种适应性使开发人员能够精确地针对网页上的特定元素或模式进行数据提取,从而使数据提取更加精确和可靠。
开发人员可以指定可重复使用的组件,以便在使用 Scrapy 的项目管道导出或存储刮擦数据之前对其进行处理。通过执行清理、验证、转换和重复数据删除等操作,开发人员可以保证提取数据的准确性和一致性。
Scrapy 中预装的一些中间件组件具有自动 cookie 处理、请求节流、用户代理轮换和代理轮换等功能。 这些中间件元素可简单配置和定制,以提高刮擦效率并解决典型问题。
通过创建自定义中间件、扩展和管道,开发人员可以进一步个性化和扩展 Scrapy 的功能,这得益于其模块化和可扩展的架构。 由于 Scrapy 具有很强的适应性,开发人员可以很容易地将 Scrapy 纳入他们当前的流程,并对其进行修改,以满足他们独特的刮擦需求。
运行以下命令,使用pip安装Scrapy:
pip install scrapy要定义您的蜘蛛,请创建一个新的 Python 文件(例如 example.py)在 spiders/ 目录下。 此处提供了一个从 URL 中提取信息的基本蜘蛛图例:
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
start_urls = ['xxxxxx.com']
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('span small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)要设置 Scrapy 项目参数,如用户代理、下载延迟和管道,请编辑 settings.py 文件。以下是如何更改用户代理并使管道发挥作用的示例:
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Set user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
# Configure pipelines
ITEM_PIPELINES = {
'myproject.pipelines.MyPipeline': 300,
}从 Scrapy 和 IronPDF 开始,需要将 Scrapy 强大的网络搜刮技能与 IronPDF 的动态 PDF 制作功能结合起来。 下面我将教你如何设置 Scrapy 项目,这样你就可以从网站中提取数据,并使用 IronPDF 创建包含数据的 PDF 文档。
IronPDFPDF.NET 是一个功能强大的 .NET 库,可使用 C#、VB.NET 和其他 .NET 语言以编程方式创建、编辑和更改 PDF 文档。 由于它为开发人员动态创建高质量 PDF 提供了广泛的功能集,因此成为许多程序的热门选择。
PDF 生成: 使用 IronPDF,程序员可以创建新的 PDF 文档,或将现有的 HTML 元素(如标签、文本、图像和其他文件格式)转换为 PDF。 该功能对于动态创建报告、发票、收据和其他文档非常有用。
HTML 至 PDF 转换: IronPDF 可让开发人员轻松地将 HTML 文档(包括 JavaScript 和 CSS 中的样式)转换为 PDF 文件。 这使得从网页、动态生成的内容和 HTML 模板创建 PDF 成为可能。
Modification and Editing of PDF Documents: IronPDF 提供了一套全面的功能,用于修改和更改预先存在的 PDF 文档。 开发人员可以合并多个 PDF 文件、将它们分离成单独的文档、删除页面、添加书签、注释和水印等功能,从而根据自己的要求定制 PDF 文件。
确保计算机上安装了 Python 后,使用 pip 安装 IronPDF for Python。
pip install IronPdf要定义您的蜘蛛,请创建一个新的 Python 文件(例如 example.py)在您的Scrapy项目的spider目录中(我的项目/我的项目/爬虫). 从 Url .NET 中提取引号的基本蜘蛛的代码示例:
class QuotesSpider(scrapy.Spider):
name = 'quotes'
#web page link
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
quotes = []
for quote in response.css('div.quote'):
Title = quote.css('span.text::text').get()
content= quote.css('span small.author::text').get()
# Generate PDF document
renderer = ChromePdfRenderer()
pdf=renderer.RenderHtmlAsPdf(self.get_pdf_content(quotes))
pdf.SaveAs("quotes.pdf")
def get_pdf_content(self, quotes):
html_content = "<html><head><title>"+Title+"</title></head><body><h1>{}</h1><p>,"+Content+"!</p></body></html>"
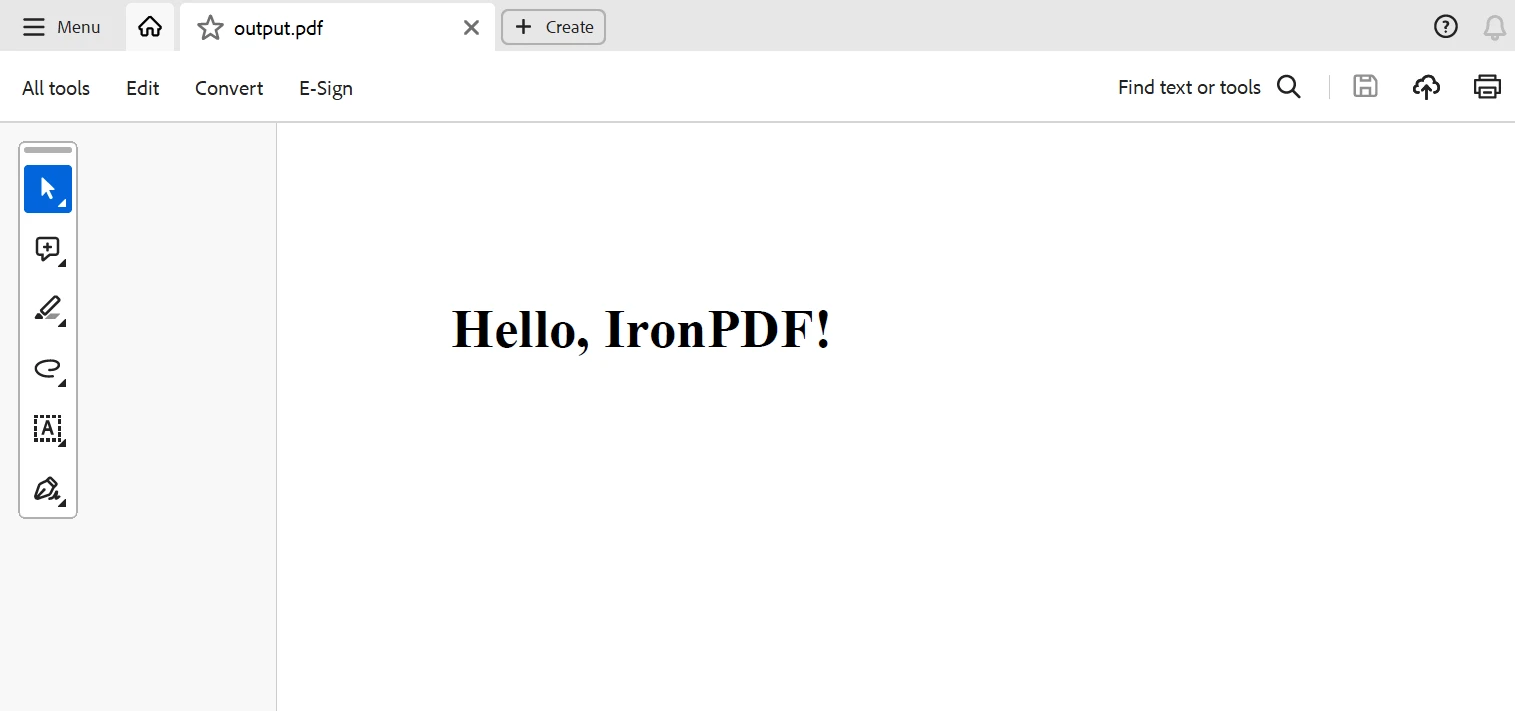
return html_content在上述带有IronPDF的Scrapy项目代码示例中,IronPDF被用来创建一个PDF 文档使用 Scrapy 提取的数据。
在这里,蜘蛛的解析方法从网页中收集引文,并使用 get_pdf_content函数为 PDF 文件创建 HTML 内容。随后,使用 IronPdf 将这些 HTML 资料渲染为 PDF 文档,并保存为 quotes.pdf。
总之,Scrapy 和 IronPDF 的结合为开发人员提供了一个强大的选择,可以自动进行网络搜刮活动并即时生成 PDF 文档。 IronPDF 灵活的 PDF 制作功能与 Scrapy 强大的网络抓取和刮擦功能相结合,可以顺利地从任何网页中收集结构化数据,并将提取的数据转化为专业品质的 PDF 报告、发票或文档。
通过使用 Scrapy Spider Python,开发人员可以有效地浏览错综复杂的互联网,从多种来源检索信息,并以系统的方式进行排列。 Scrapy 灵活的框架、异步架构以及对 XPath 和 CSS 选择器的支持,为其提供了管理各种网络搜刮活动所需的灵活性和可扩展性。
IronPdf 附带终身许可,捆绑购买时价格公道。 该套餐提供了极好的价值,仅需 $749。(一次性购买多个系统). 持有许可证的用户可全天候获得在线技术支持。 有关费用的详细信息,请访问网站. 访问此页面,了解有关 Iron Software 的更多信息产品.
无需信用卡
您的试用密钥应该在邮件中。![]() 试用表格已
试用表格已
成功提交。
如果没有,请联系
support@ironsoftware.com

免费开始
无需信用卡
在生产环境中测试,无水印。
随时随地满足您的需求。
获得30天的全功能产品。
几分钟内就能启动并运行。
在您的产品试用期间,全面访问我们的支持工程团队。






预约30分钟的个人演示。
无需合同,无需卡片信息,无需承诺。

