
在实际环境中测试
在生产环境中测试,无水印。
随时随地满足您的需求。
Python PDF库


PDF 文件是最流行的数字文件格式之一。 这些工具因其在不同系统间的兼容性和保留复杂文档格式的能力而备受青睐。
在数据管理方面,将 PDF 文档转换为可编辑格式或提取文本进行分析是非常有价值的。 这一转换过程使企业和个人能够挖掘并利用静态文档中的数据。
Python 凭借其广泛的库生态系统,为处理 PDF 文件提供了一种易于使用且功能强大的方法。 无论是提取数据、转换 PDF 文件还是自动生成报告,Python 的简单性和丰富的工具使其成为 PDF 处理任务的首选语言。
IronPDF是一个全面的面向 Python 开发人员的 PDF 渲染库以方便与 PDF 文件进行交互。 它提供了一套强大的工具,允许在 Python 编程环境中创建、操作和转换 PDF 文档。
IronPDF 将 Python 脚本的易用性和 PDF 处理所需的文档管理功能连接起来,从而使开发人员能够将 PDF 功能直接集成到他们的应用程序中。
安装 IronPdf 之前,请确保您的系统满足以下要求:
如果您在 Windows 系统上运行 IronPDF,请使用 .NET Framework,因为 IronPDF 依靠 .NET 运行。
确认系统满足这些要求后,就可以使用 pip 安装 IronPDF 了。打开命令行或终端,运行以下命令:
pip install ironpdf
确保您使用的是最新版本的 IronPDF for Python 库。 此命令将下载并安装 IronPDF 库和所有 Python 环境中所需的依赖项。
from ironpdf import *该代码片段以导入语句开始,将 IronPDF 库中的所有必要组件导入您的 Python 脚本。 它对于访问 IronPDF 提供的允许您处理 PDF 文件的类和方法至关重要。
# Set a log path
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.AllLogger.EnableDebugging = True:此行启用 IronPDF 库中的调试功能。 在跟踪库的运行时,调试至关重要,尤其是在遇到故障排除问题时。
Logger.LogFilePath = "Custom.log ":在此,您可以指定日志文件的路径和名称。程序库会将所有调试信息写入 "Custom.log"。确保写入的目录存在且可写。
Logger.LoggingMode = Logger.LoggingModes.All:将日志记录模式设置为 All,即指示日志记录器记录所有事件,包括信息级日志、警告和错误。 这种全面的日志记录对于调试非常宝贵。
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")PdfDocument.FromFile("content.pdf"):该命令通过创建一个新的 PdfDocument 对象,将名为 "content.pdf "的 PDF 文件加载到 IronPDF 环境中。
现在,pdf 变量可以保存 PDF 文档,并允许您执行各种操作。
# Extract text from PDF document
all_text = pdf.ExtractAllText()
print(all_text)pdf.ExtractAllText():该方法在pdf对象上调用,该对象包含已加载的 PDF 文档。 它提取了文档中的所有文本内容。 然后将文本存储到变量 all_text 中。
打印(所有文本):此行将提取的文本打印到控制台。 这是一种验证文本提取过程是否正确的方法,并且可以立即看到输出结果。
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from specific page in the document
page_text = pdf.ExtractTextFromPage(1)PdfDocument.FromFile("content.pdf"):虽然之前已经加载过文档,但重复这一行是为了说明您需要一个 PDF 文件对象、(PDFDocument** 对象)从中提取文本。 您不需要再用连续脚本加载文档。
Pdf.ExtractTextFromPage(1):此方法可从指定的 PDF 文件页面中提取文本。 参数 1 表示应从第二页删除文本(因为页面索引从零开始).
提取的文本分配给 page_text. 您可以将其转换为文本文件(txt 文件)只需几行代码。
在实际操作中,如果您想查看从特定页面提取的文本,您可以包含这样的打印语句:
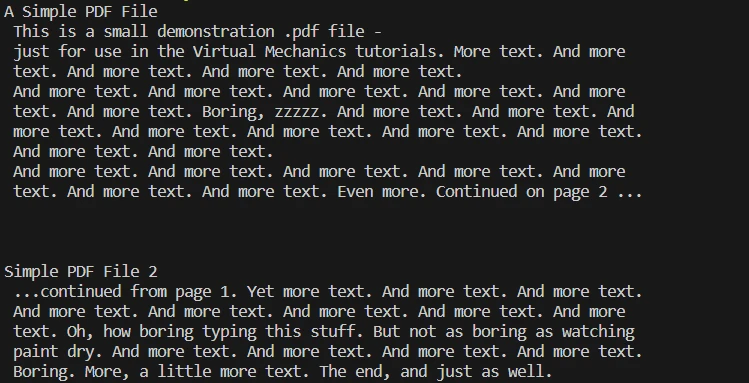
print(page_text)本教程为开发人员提供了将 PDF 文件内容转换为文本的清晰路径,无论您需要处理整个文档还是单个页面,都可以使用 Python 中的 IronPDF 库。
以下是完整的代码,您可以在您的代码中使用:
from ironpdf import *
License.LicenseKey = "License-Code"
# Set a log path
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load existing PDF document
pdf = PdfDocument.FromFile("sample.pdf")
# Extract text from PDF document
all_text = pdf.ExtractAllText()
print(all_text)IronPDF 不仅仅处理文本提取。 其主要功能之一是能够将 PDF 文件转换为其他格式,这对于在不同媒介中共享和展示信息尤为有用。
在物理文档方面,直接从 Python 管理 PDF 文件打印作业非常有价值。 IronPdf 提供了这种能力,只需几个命令就能简化从数字到实体的过程。
对于扫描的 PDF 文件,IronPDF 提供了提取文本的专门方法,由于内容的性质是图像而不是可选择的文本,这可能是一项具有挑战性的任务。 这将扩展该库的实用性,使其适用于更广泛的文档管理任务。
PDF 处理技术发展迅速,从简单的文本提取到复杂的数据处理和更具交互性的文档操作。 现在的重点正在转向自动化、人工智能和基于云的服务,从而实现更加动态和智能的文档处理解决方案。
IronPdf 可能会与时俱进,融入这些前沿技术,以保持相关性和稳健性。
IronPDF 简化了 PDF 到文本的转换过程,简化了工作流程,是开发人员和企业的宝贵资产。
IronPDF 能够无缝集成到 Python 环境中,能够从标准 PDF 和扫描 PDF 中提取强大的文本,并能高保真地保持原始文档的格式,因此脱颖而出。
该库的日志和调试功能可进一步帮助开发可靠的 PDF 操作应用程序。
将 PDF 转换为文本后,以下步骤涉及利用提取的数据。 这可能意味着将文本集成到数据库中、执行数据分析、将其输入报告工具或用于机器学习。
由于文本数据采用了更易于访问的格式,处理和使用这些信息的可能性大大增加,从而为获得新的见解和提高运营效率打开了大门。
IronPDF 提供一个30 天免费试用此外,译文还应让您能够在使用之前探索和评估其全部功能。 试用期是开发人员亲身体验 IronPDF 如何简化其 PDF 工作流程的绝佳机会。
无需信用卡
您的试用密钥应该在邮件中。![]() 试用表格已
试用表格已
成功提交。
如果没有,请联系
support@ironsoftware.com

免费开始
无需信用卡
在生产环境中测试,无水印。
随时随地满足您的需求。
获得30天的全功能产品。
几分钟内就能启动并运行。
在您的产品试用期间,全面访问我们的支持工程团队。






预约30分钟的个人演示。
无需合同,无需卡片信息,无需承诺。

