
在实际环境中测试
在生产环境中测试,无水印。
随时随地满足您的需求。
Python PDF库


本文将使用IronPDF for Python通过Python代码从PDF文件中提取图像。
IronPDFfor Python 是一个先进且强大的库,为在 Python 中处理 PDF 文档带来了新的维度。 作为PDF任务的综合解决方案,IronPDF可实现将高级PDF功能无缝集成到应用程序中。
IronPDF提供了广泛的工具和API,用于执行以下任务:创建PDFs从头开始,转换将HTML转换为高质量PDF通过执行操作来管理PDF页面,例如合并, 分拆和编辑。 这些工具是用户友好且高效的。 凭借其用户友好的界面和详尽的文档,IronPDF为开发者开启了无限可能。
无论是创建专业报告和发票、自动化工作流程还是管理文档,IronPDF 提供了在文档管理和自动化领域中的宝贵资产,使其成为任何开发者在 Python 应用程序中利用 PDF 功能的必备工具。
安装IronPDF库以在Python中从PDF中提取图像。
编写 PdfDocument.FromFile 方法以使用本地磁盘的文件路径加载 PDF 文件。
应用 ExtractAllImages 方法从 PDF 文件中提取图像。
使用循环遍历PDF中找到的所有提取的图像。
在深入了解如何使用Python从PDF中获取图像之前,让我们先安装必要的先决条件:
Python 安装:确保你有一个Python在您的系统上安装了解释器。 从PDF获取图像的过程将需要Python 3.0或更新版本。 确保您具有兼容的Python安装。
pip 来安装它。 只需打开命令行界面并执行以下命令: :ProductInstall集成开发环境(IDE)虽然不是强制性的,但使用集成开发环境(IDE)可以大大提升您的开发体验。 IDE 提供诸如代码补全、调试和更简化的工作流程等功能。 一个非常受欢迎的Python开发IDE是PyCharm。 您可以从下载并安装PyCharmJetBrains 网站.
一旦这些先决条件到位,您就可以通过Python和IronPDF探索从PDF中检索图像的精彩世界的分步指南。
以下是在PyCharm中创建新Python项目的步骤。
要在 PyCharm 中启动一个新的 Python 项目,打开 PyCharm 应用程序并导航到顶部菜单。
单击文件,然后从下拉菜单中选择新建项目。
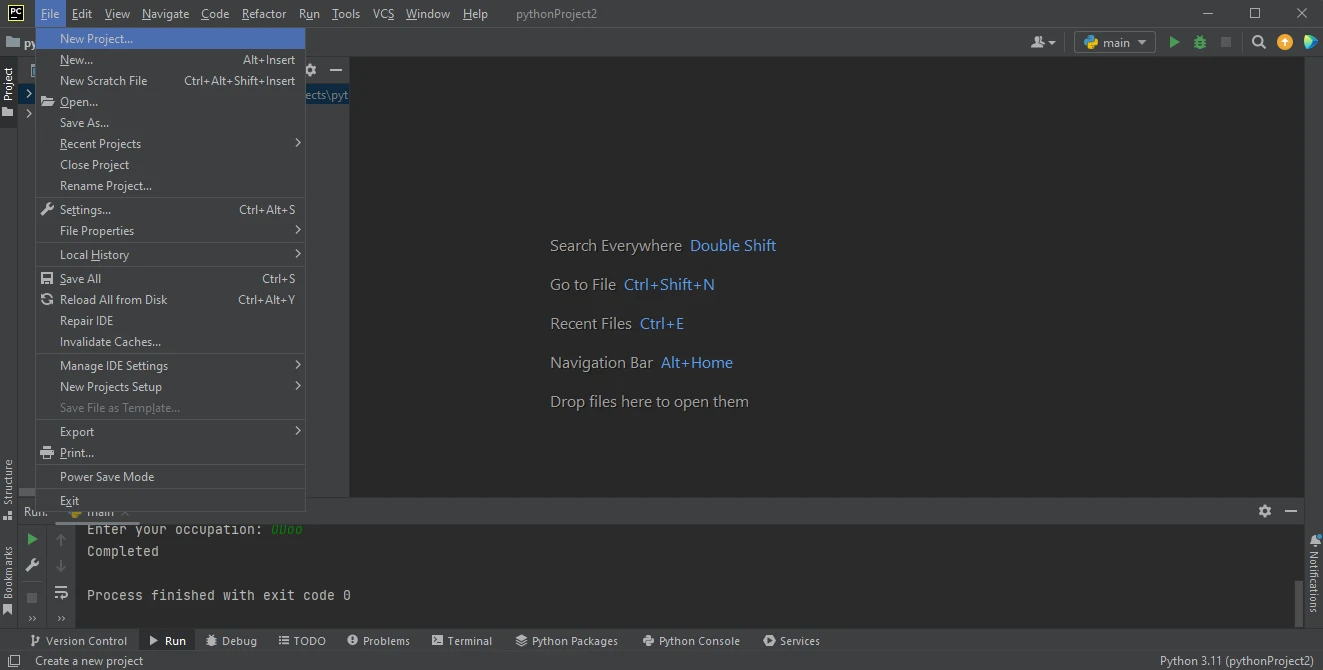
PyCharm IDE
单击新建项目后,名为创建项目的新窗口将出现。
在此窗口中,在顶部的Location字段中输入您的项目名称。选择环境; 如果您正在使用虚拟环境,请从提供的选项中选择。
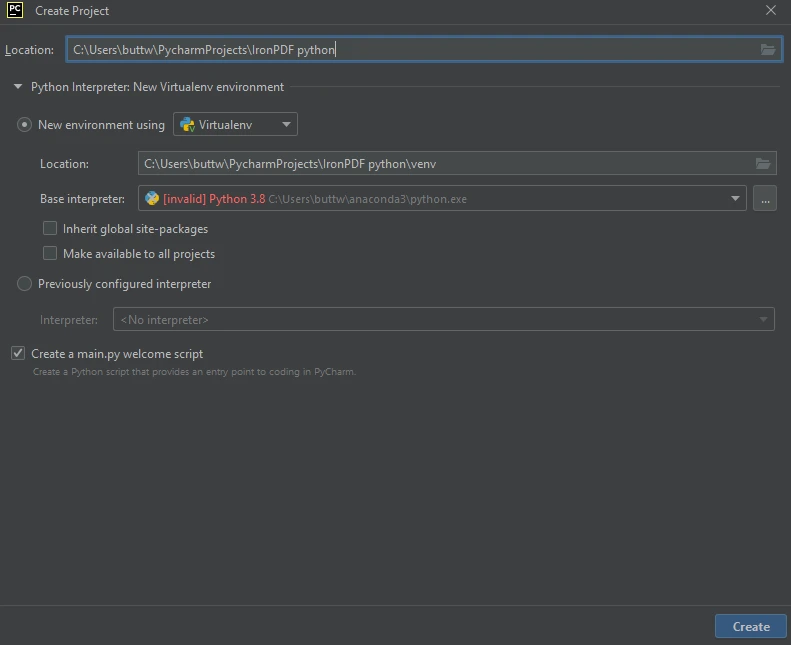
在 PyCharm 中创建一个新的 Python 项目
一旦选择了环境,点击 Create 按钮来创建你的 Python 项目。
您的 Python 项目现已创建并可以用于各种任务,例如提取图像。
要安装IronPDF,只需打开终端或单独的命令提示符,输入命令pip install ironpdf,然后按Enter键。 终端将显示以下输出。
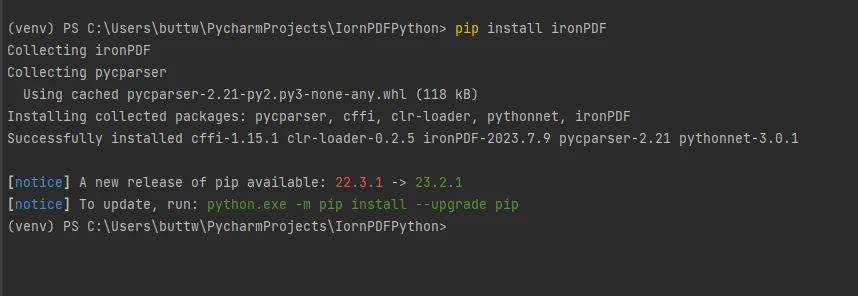
安装 IronPDF 包
IronPDF 为开发人员提供工具和 API,使他们能够无缝地浏览 PDF 并识别和提取嵌入的图像。 无论是用于分析还是集成,IronPDF 都通过 Python 的灵活性简化了提取过程。 这使得在处理PDF和基于图像的应用程序时显得尤为重要。只需几行代码,它就可以从PDF文件中提取所有图像,这非常简单。
请参阅以下代码,以使用Python编程语言从PDF中提取图像。
from ironpdf import *
# Open PDF file
pdf = PdfDocument.FromFile("FYP Thesis.pdf")
# Get all images found in PDF Document
all_images = pdf.ExtractAllImages()
# Save each image to the local disk image
for i, image in enumerate(all_images):
image.SaveAs(f"output_image_{i}.png")
此代码首先导入IronPDF库,然后仅使用文件路径通过`PdfDocument.FromFile`方法从本地加载PDF文件。
``` 然后它将访问 PDF 的每一页以将图像字节提取为 Image 对象。 这些来自PDF页面的图像对象然后使用`SaveAs`方法保存。 在上述代码中,用户根据图像索引和图像扩展名(PNG)分配一个动态图像名称。
比选择使用Python库更简单,像[PyMuPDF](https://pypi.org/project/PyMuPDF/)和[枕头](https://pypi.org/project/Pillow/)库,使用 `import fitz` 并通过 `ExtractImage` 提取图像。()`并使用`from PIL import Image`将字节转换为PIL图像实例,以保存磁盘上的图像文件。 IronPDF 通过仅需几行代码即可实现此功能。
## 步骤 4 将图像从 PDF 文件中保存下来。
图像从 PDF 文件的所有页面中提取并保存为 PNG 格式。 您还可以通过调整文件扩展名以匹配所需的图像文件格式,灵活地修改输出格式来保存可用的图像对象。
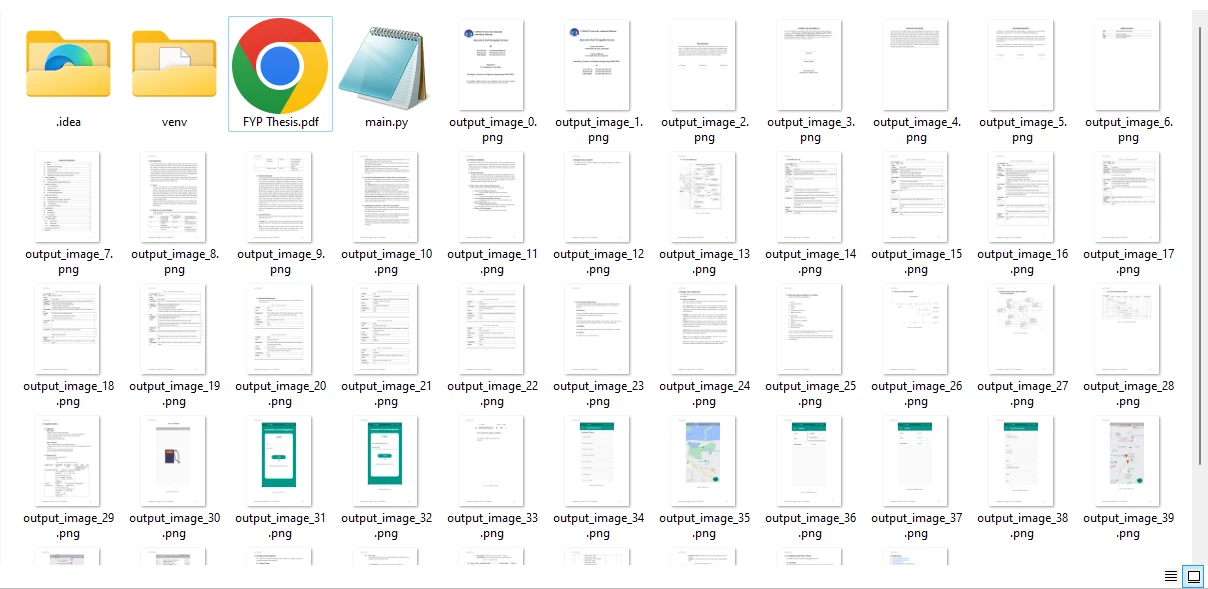
**从示例 PDF 文件提取的图像**
## 结论
Python与强大的[IronPDF](/python/),提供了一种多功能且高效的解决方案,用于从PDF文件中提取图像的任务。 利用 Python 的灵活性和 IronPDF 的功能,开发人员可以无缝地浏览 PDF 文档,定位其中的图像字节,并以所需的图像扩展名保存这些图像。 该过程包括从 PDF 中获取图像,生成的图像列表可以根据需要进一步处理和操作。 通过掌握使用Python从PDF中获取图像的艺术,开发人员可以提升他们的工作流程,实现文档管理自动化,并探索广泛的基于图像的应用程序,使其成为数字时代的一项宝贵技能。
要了解有关从 PDF 文件提取图像的更多功能,请访问以下网站[范例](/python/examples/extract-pdf-image/). 您可以探索其他操作,例如将PDF文件内容转换为图像的选项,完整教程在此提供。[如何 Python 文章](/python/how-to/python-pdf-to-image/).无需信用卡
您的试用密钥应该在邮件中。![]() 试用表格已
试用表格已
成功提交。
如果没有,请联系
support@ironsoftware.com

免费开始
无需信用卡
在生产环境中测试,无水印。
随时随地满足您的需求。
获得30天的全功能产品。
几分钟内就能启动并运行。
在您的产品试用期间,全面访问我们的支持工程团队。






预约30分钟的个人演示。
无需合同,无需卡片信息,无需承诺。

