
在实际环境中测试
在生产环境中测试,无水印。
随时随地满足您的需求。
Python PDF库


XGBoost代表极端梯度提升,是一种强大且准确的机器学习算法。 它主要应用于回归分析、分类和排序问题。 它涉及诸如调节之类的功能,帮助避免过拟合,并行性,以及缺失数据处理。
IronPDF 是一个用于创建、修改和阅读 PDF 文件的 Python 库。 它可以轻松地将HTML、图像或文本转换为PDF,并且还可以添加页眉、页脚和水印。 虽然主要关注在Python中的使用,但值得注意的是,可以借助诸如Python之类的互操作工具在这个编程语言中实现NET工具。
XGBoost 和 IronPDF 的结合提供了更广泛的应用。 通过IronPDF,预测结果可以与创建交互式PDF文档结合起来。 这种组合在生成精确的公司文件和数据以及从应用预测模型中获得的结果方面特别有帮助。
XGBoost 是一个基于集成学习的强大且高效灵活的 Python 机器学习库。 XGBoost 是陈天奇实施的一种梯度提升算法,包含附加优化。 在许多应用领域中,该方法的有效性已被证明,可以解决相应的任务,如分类、回归、排序任务等。XGBoost 具有几个独特的特征:缺失值的不存在对它来说不是问题; 有机会利用 L1 和 L2 范数来对抗过拟合;
训练是并行进行的,这显著加快了训练过程。 XGBoost中的剪枝也是深度优先的,这有助于管理模型容量。 其功能之一是超参数的交叉验证和用于评估模型性能的内置函数。 该库可以与Python环境中构建的其他数据科学工具很好地交互,例如NumPy、SciPy和scikit-learn,使其能够集成到已确认的环境中。 尽管如此,由于其速度、简单性和高性能,XGBoost 已成为许多数据分析师、机器学习专家和有抱负的神经网络数据科学家的“武器库”中的重要工具。
XGBoost以其众多功能而闻名,这些功能使其在各种机器学习任务和机器学习算法中具有优势,并且使其更易于实现。 以下是XGBoost在Python中的主要功能。 以下是 XGBoost 在 Python 中的关键功能:
正则化:
应用 L1 和 L2 正则化技术来减少过拟合并提高模型的性能。
并行处理:
预训练模型在训练过程中使用所有 CPU 核心,从而大幅度提升模型的训练效果。
处理缺失数据:
一种算法,当模型经过训练时,会自动决定处理缺失值的最佳方式。
树剪枝:
在树剪枝中,通过使用参数“max_depth”实现树的深度优先遍历,这有助于减少过拟合。
内置交叉验证:
它包括用于模型评估和超参数优化的内置交叉验证方法,因为它原生支持并执行交叉验证,实现起来更简单。
可扩展性:
它经过优化以实现可扩展性; 因此,它可以分析大数据并适当地处理特征空间数据。
支持多种语言:
XGBoost 最初是在 Python 中开发的; 然而,为了扩大其范围,它还支持R、Julia和Java。
分布式计算:
该软件包被设计为可分发的,这意味着它可以在多台计算机上执行以处理大量数据。
自定义目标和评估函数:
它使用户能够根据其特定需求设置目标函数和性能测量。 此外,它支持二元和多类别分类。
功能重要性:
它有助于识别各种功能的价值,可以帮助选择给定数据集的功能,并提供多个模型的解释。
稀疏感知
它在稀疏数据格式下表现良好,这在处理包含许多NULL值或零的数据时非常有用。
与其他库的集成:
它与数据科学库(如NumPy、SciPy和sci-kit-learn)的短期流行形成互补,这些库易于集成到数据科学工作流程中。
在 Python 中,创建和配置 XGBoost 模型涉及多个过程:数据收集和预处理过程、模型的创建、模型的管理以及模型的评估。 以下是一个详细指南,将帮助您入门:
安装 XGBoost
首先,检查系统中是否有 Xgboost 包。 您可以使用pip将其安装在您的计算机上:
pip install xgboost导入库
import xgboost as xgb
import numpy as np
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error准备数据
在这个例子中,我们将使用波士顿房价数据集:
# Load the Boston housing dataset
boston = load_boston()
#load default value from the package
X = boston.data
y = boston.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)创建DMatrix
XGBoost使用一种称为DMatrix的自定义数据结构进行训练。
# Create DMatrix for training and testing sets
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)设置参数
配置模型参数。 示例配置如下:
# Set parameters
params = {
'objective': 'reg:squarederror', # Objective function
'max_depth': 4, # Maximum depth of a tree
'eta': 0.1, # Learning rate
'subsample': 0.8, # Subsample ratio of the training instances
'colsample_bytree': 0.8, # Subsample ratio of columns when constructing each tree
'seed': 42 # Random seed for reproducibility
}训练模型
使用train方法训练XGBoost模型。
# Number of boosting rounds
num_round = 100
# Train the model
bst = xgb.train(params, dtrain, num_round)进行预测
现在,使用这个训练模型对测试集进行预测。
# Make predictions
preds = bst.predict(dtest)评估模型
使用适当的指标评估机器学习模型的性能——例如,均方根误差:
# Calculate mean squared error
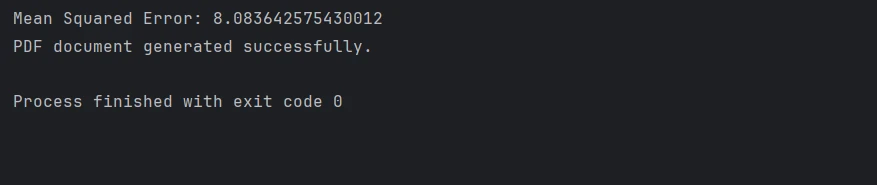
mse = mean_squared_error(y_test, preds)
print(f"Mean Squared Error: {mse}")保存和加载模型
您可以将训练好的模型保存到文件中,并在需要时稍后加载:
# Save the model
bst.save_model('xgboost_model.json')
# Load the model performance
bst_loaded = xgb.Booster()
bst_loaded.load_model('xgboost_model.json')以下是生成的JSON文件。

下面是两个库的基本安装,并展示了如何使用XGBoost进行数据分析和使用IronPDF生成PDF报告的示例。
使用功能强大的Python包IronPDF生成、操作和读取PDF文件。 这使程序员能够对PDF执行许多基于编程的操作,例如处理现有PDF和将HTML转换为PDF文件。 IronPDF是一个高效的解决方案,适用于需要动态生成和处理PDF的应用程序,因为它提供了一种自适应且友好的方式来生成高质量的PDF文档。
IronPDF 能从任何 HTML 内容生成新的或现有的 PDF 文档。 它允许从 Web 内容中创建精美的艺术 PDF 出版物,捕捉现代 HTML5、CSS3 和 JavaScript 的所有形式的强大功能。
它可以在新程序生成的PDF文档中添加文本、图片、表格和其他内容。 使用IronPDF,现有的PDF文档可以打开和编辑以便进一步修改。 在 PDF 中,您可以根据需要编辑/添加内容和删除文档中的特定内容。
它使用CSS来美化PDF中的内容。它支持复杂的布局、字体、颜色和所有这些设计组件。 此外,可以与JavaScript一起使用的HTML材料的渲染方式允许在PDF中动态创建内容。
可以通过 Pip 安装 IronPDF。使用以下命令安装:
pip install ironpdf导入所有相关库并加载您的数据集。 在我们的案例中,我们将使用波士顿房价数据集:
import xgboost as xgb
import numpy as np
from ironpdf import * from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Load data
boston = load_boston()
X = boston.data
y = boston.target
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create DMatrix
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
# Set parameters
params = {
'objective': 'reg:squarederror',
'max_depth': 4,
'eta': 0.1,
'subsample': 0.8,
'colsample_bytree': 0.8,
'seed': 42
}
# Train model
num_round = 100
bst = xgb.train(params, dtrain, num_round)
# Make predictions
preds = bst.predict(dtest)
# Create a PDF document
iron_pdf = ChromePdfRenderer()
# Create HTML content
html_content = f"""
<html>
<head>
<title>XGBoost Model Report</title>
</head>
<body>
<h1>XGBoost Model Report</h1>
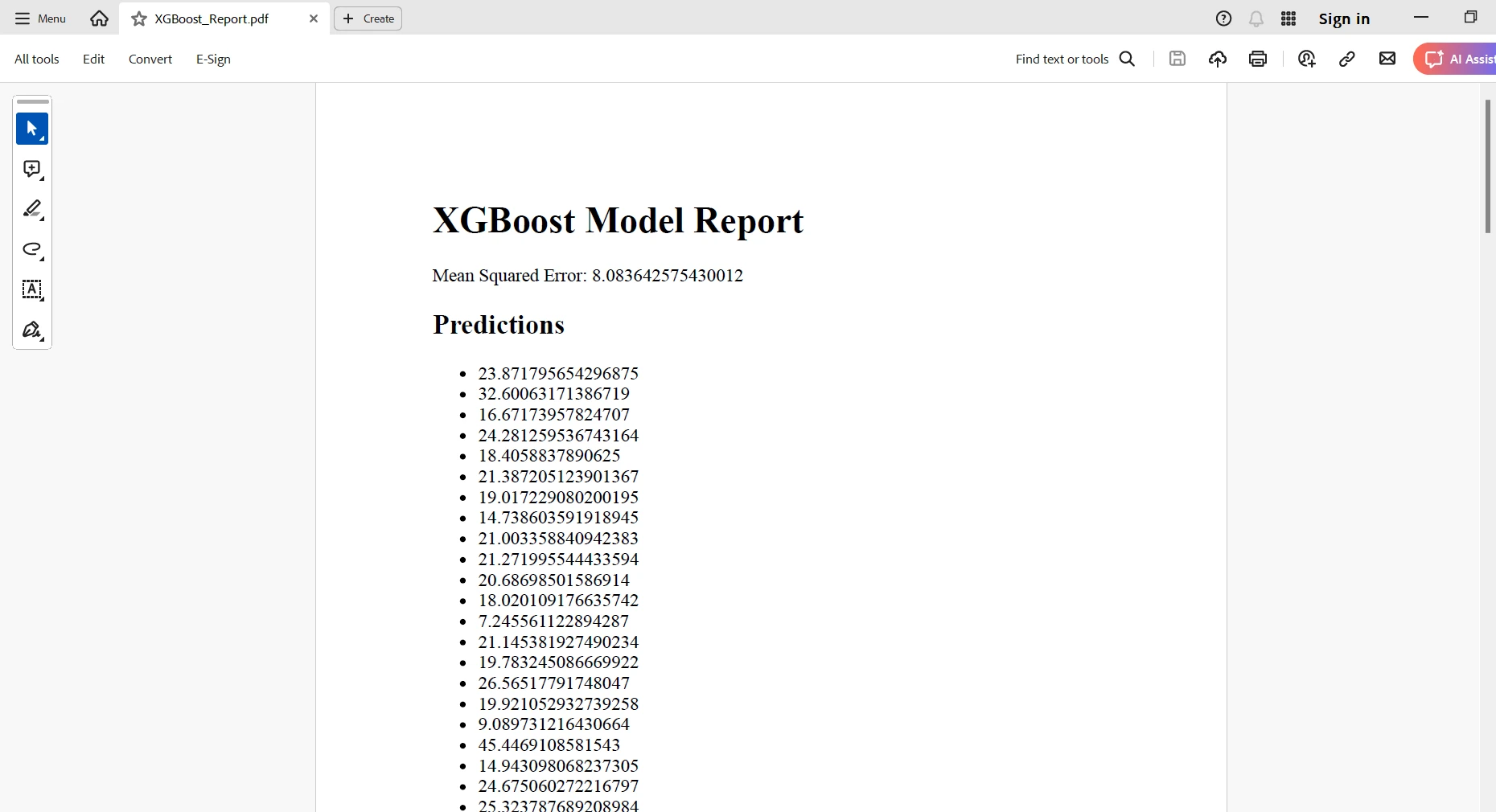
<p>Mean Squared Error: {mse}</p>
<h2>Predictions</h2>
<ul>
{''.join([f'<li>{pred}</li>' for pred in preds])}
</ul>
</body>
</html>
"""
pdf=iron_pdf.RenderHtmlAsPdf(html_content)
# Save the PDF document
pdf.SaveAs("XGBoost_Report.pdf")
print("PDF document generated successfully.")现在,您将创建 DMatrix 类的对象以有效地处理数据,然后设置与目标函数和超参数相关的模型参数。 在训练完 XGBoost 模型后,在测试集上进行预测; 您可以使用均方误差或类似指标来评估性能。 然后,使用IronPDF创建包含所有结果的PDF。
您创建了包含所有结果的HTML表示形式; 然后,您将使用IronPDF的RenderHtmlAsPdf类将此HTML内容转换为PDF 文档. 最后,您可以将生成的PDF报告保存到所需的位置。 换句话说,这种集成将使您能够自动创建非常精细、专业的报告,其中包含从机器学习模型中获得的见解。
总之,XGBoost 和 IronPDF 集成在一起,以进行高级数据分析和专业报告生成。 XGBoost的效率和可伸缩性为通过复杂的机器学习任务提供了最佳解决方案,其具有强大的预测能力和优秀的模型优化工具。 您可以使用Python无缝地将IronPDF与这些强大的工具结合在一起,将从XGBoost获得的丰富见解转化为详尽的PDF报告。
这些集成因此将大大促进富有吸引力且信息丰富的文档的生成,从而使其能够与利益相关者沟通或适合进一步分析。 没有 XGBoost 与 IronPDF 之间内建的协同作用,商业分析、学术研究或任何数据驱动的项目都不可能实现,因为它们能够高效地处理数据并轻松传达发现。
集成IronPDF和铁软件(Iron Software)产品确保您的客户和最终用户获得功能丰富的高级软件解决方案。 这也将有助于优化您的项目和流程。
全面的文档、活跃的社区和频繁的更新与IronPDF功能密切相关。 Iron Software是现代软件开发项目中值得信赖的合作伙伴。 IronPDF提供给所有开发人员免费试用。 他们可以尝试所有功能。 获得此产品最大价值的许可证费用为$749。
无需信用卡
您的试用密钥应该在邮件中。![]() 试用表格已
试用表格已
成功提交。
如果没有,请联系
support@ironsoftware.com

免费开始
无需信用卡
在生产环境中测试,无水印。
随时随地满足您的需求。
获得30天的全功能产品。
几分钟内就能启动并运行。
在您的产品试用期间,全面访问我们的支持工程团队。






预约30分钟的个人演示。
无需合同,无需卡片信息,无需承诺。

