
在实际环境中测试
在生产环境中测试,无水印。
随时随地满足您的需求。
Java PDF 图书馆


本文将使用IronPDF库以高效的方法在Java中创建一个PDF解析器。
IronPDF for Java 是一个 Java PDF 库,可轻松准确地创建、读取和操作 PDF 文档。 它建立在 IronPDF for .NET 的成功基础之上,提供了跨不同平台的高效功能。 用于 Java 的 IronPDF 利用 IronPdfEngine,其速度快且经过性能优化。
使用IronPDF,您可以从PDF文件中提取文本和图像,还可以从各种来源创建PDF,包括HTML字符串、文件、URL和图像。 此外,您可以轻松地添加新内容,使用 IronPDF 插入签名,以及将元数据嵌入 PDF 文档。 IronPdf 专为 Java 8+、Scala 和 Kotlin 而设计,兼容 Windows、Linux 和云平台。
要制作 Java PDF 解析项目,您需要以下工具:
Java IDE:您可以使用任何支持 Java 的 IDE。有多个 Java IDE 可供开发使用。 本教程将使用IntelliJ IDE。 您可以使用 NetBeans、Eclipse 等等。
Maven 项目:Maven 是一个依赖管理工具,允许对 Java 项目进行控制。 可以从Maven 官方网站下载 Java 的 Maven。 IntelliJ Java IDE 内置支持 Maven。
IronPDF - 您可以通过多种方式下载和安装IronPDF for Java。
pom.xml文件中。 :ProductInstall访问Maven存储库网站以获取最新的IronPDF for Java软件包。
从Iron Software 官网下载页面直接下载。
pom.xml文件中添加以下依赖项: <dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.5</version>
</dependency>安装好所有先决条件后,第一步就是导入必要的 IronPDF 软件包,以处理 PDF 文档。 在 Main.java 文件的顶部添加以下代码:
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;IronPDF中的某些方法需要许可证才能使用。 您可以购买许可证或免费试用 IronPDF。 您可以将密钥设置如下:
License.setLicenseKey("YOUR-KEY");要解析现有文档以提取内容,需要使用PdfDocument类。 其静态fromFile方法用于在Java程序中从特定路径和文件名解析PDF文件。 代码如下
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));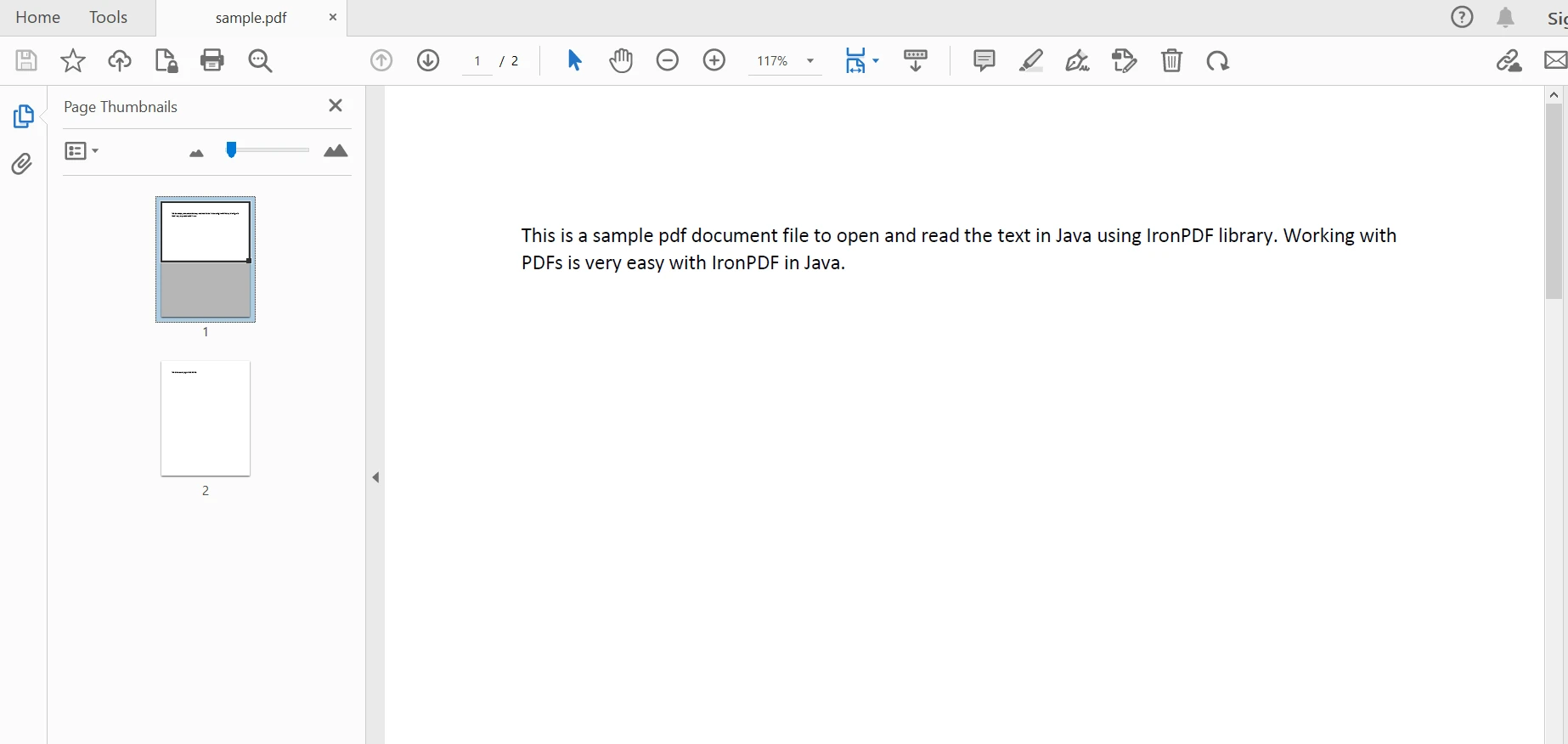
解析的文档
IronPDF for Java 提供了一种从 PDF 文档中提取文本 的简单方法。 以下代码片段用于从 PDF 文件中提取文本数据:
String extracted_text = parsedDocument.extractAllText();上述代码的输出结果如下:
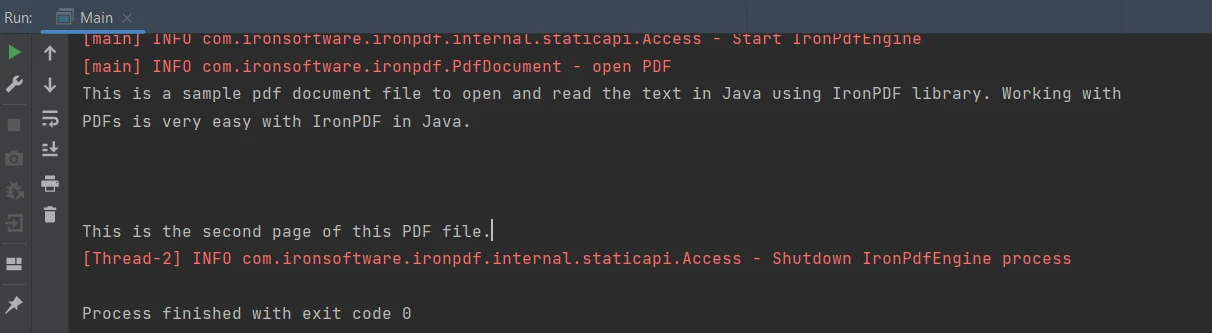
输出
IronPDF for Java 的功能不仅限于现有的 PDF,它还可以创建和解析一个新文件以提取内容。 在本教程中,将从URL创建一个PDF文件并从中提取内容。 下面的示例展示了如何完成这项任务:
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extracted_text = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extracted_text);
}
}输出结果如下
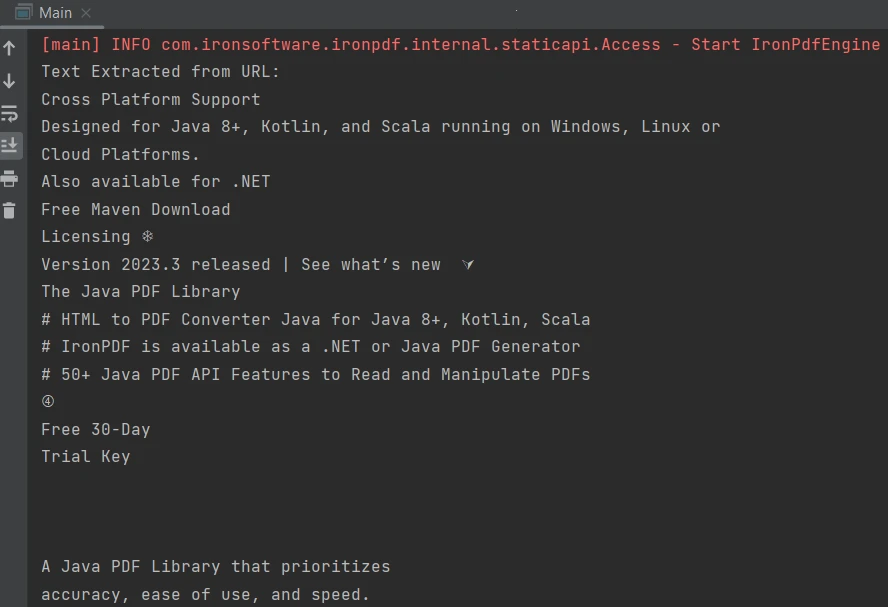
输出
IronPDF 还提供了一种简单的选项来从已解析的文档中提取所有图像。 在此,教程将使用之前的示例来说明如何轻松地从 PDF 文件中提取图像。
import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}extractAllImages 方法返回一个 BufferedImages 列表。 然后,每个BufferedImage都可以使用ImageIO.write方法存储为PNG图像在某个位置。 解析后的 PDF 文件中有 34 张图片,每张图片都提取得非常完美。

提取的图像
使用[extractAllText 方法](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText(),只需一行代码即可轻松从PDF文件中的表格边界提取内容。 以下代码片段演示了如何从 PDF 文件的表格中提取文本:
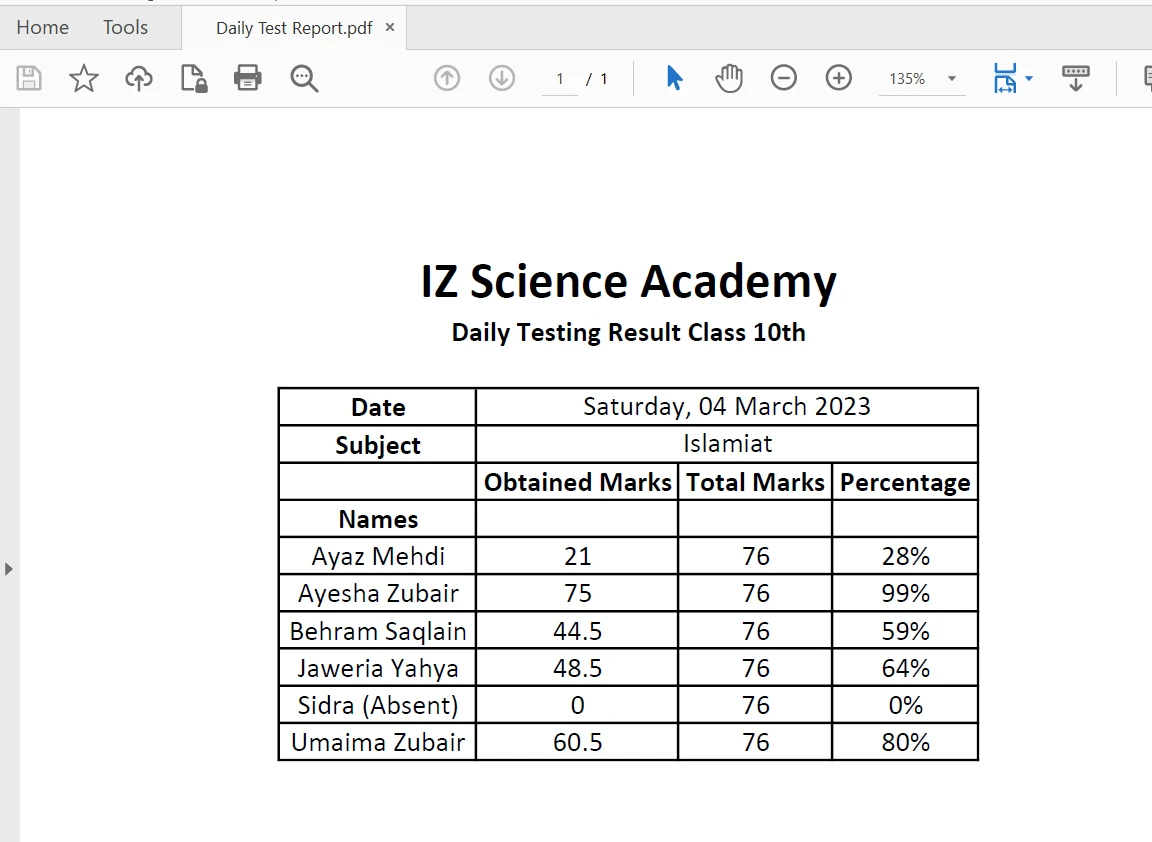
PDF中的表格
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extracted_text = parsedDocument.extractAllText();
System.out.println(extracted_text);输出结果如下
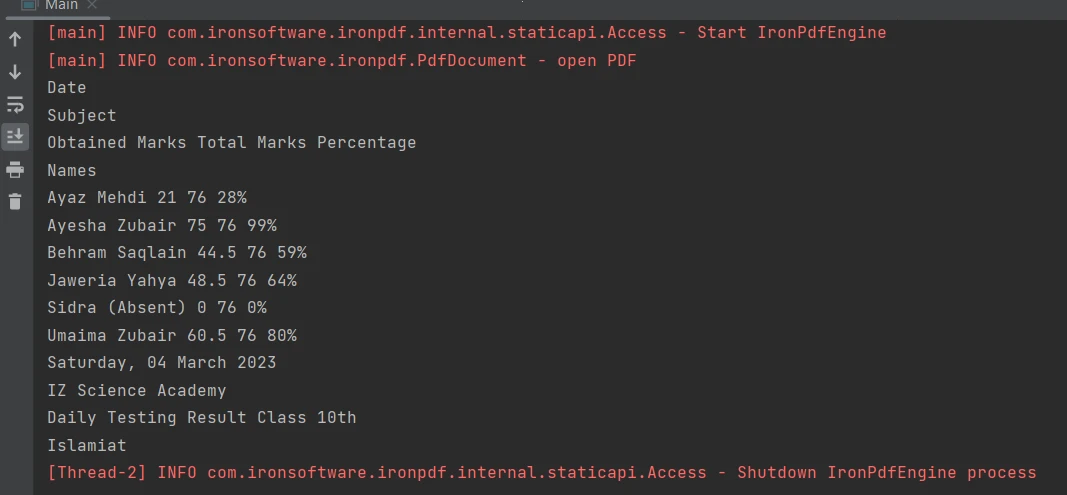
输出
本文演示了如何使用 IronPDF for Java 在 Java 中解析现有 PDF 文档或从 URL 创建新的 PDF 解析器文件,以从中提取数据。 打开文件后,它可以从 PDF 中提取表格数据、图像和文本,还可以将提取的文本添加到文本文件中,以供日后使用。
有关如何在 Java 中以编程方式操作 PDF 文件的更多详细信息,请访问这些PDF 文件创建示例。
Java版IronPDF库在开发过程中是免费的,并且提供免费试用。 然而,商业用途可以通过IronSoftware获得许可,起价为$749。
达瑞乌斯·塞兰特拥有迈阿密大学计算机科学学士学位,目前在Iron Software担任全栈WebOps营销工程师。从小对编码的热爱使他认为计算机既神秘又易接近,成为创意和解决问题的完美媒介。
在Iron Software,达瑞乌斯乐于创造新事物并简化复杂概念,使其更易于理解。作为我们在职开发者之一,他还自愿教授学生,将他的专业知识传授给下一代。
对达瑞乌斯而言,他的工作之所以令人满足,是因为它具有价值并产生了真正的影响。

<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2025.4.4</version>
</dependency>
无需信用卡
您的试用密钥应该在邮件中。![]() 试用表格已
试用表格已
成功提交。
如果没有,请联系
support@ironsoftware.com

免费开始
无需信用卡
在生产环境中测试,无水印。
随时随地满足您的需求。
获得30天的全功能产品。
几分钟内就能启动并运行。
在您的产品试用期间,全面访问我们的支持工程团队。






预约30分钟的个人演示。
无需合同,无需卡片信息,无需承诺。

