
在实际环境中测试
在生产环境中测试,无水印。
随时随地满足您的需求。
Java PDF 图书馆


本文将探讨如何使用Java编程语言从现有PDF文档中提取图像并将其保存在一个文件夹中。 为此,使用IronPDF for Java库提取图像。
IronPDF 是一个 Java 库,旨在帮助开发人员在其 Java 应用程序中生成、修改和提取 PDF 文件中的数据。 使用 IronPDF,您可以从多种来源创建 PDF 文档,例如 HTML、图像等。 此外,您可以合并、拆分和操作现有的PDF文件。 IronPDF还包括安全功能,例如密码保护和数字签名。
由Iron Software开发和维护,IronPDF以其从PDF、HTML和URL中提取文本的能力而闻名。 这使它成为一个多功能且强大的工具,可用于各种应用,无论是从头创建 PDF 还是处理现有的 PDF。
在使用IronPDF从PDF文件中提取数据之前,必须满足以下几个前提条件:
Java 安装:确保 Java 已安装在您的系统中,并将其路径设置在环境变量中。 如果您尚未安装 Java,请按照Java 网站的下载页面上的说明进行操作。
Java IDE:将Eclipse或IntelliJ安装为您的Java IDE。您可以从此链接下载Eclipse,并从此下载页面下载IntelliJ。
IronPDF 库:下载并将 IronPDF 库添加到您的项目中作为依赖项。 有关设置说明,请访问IronPDF 网站。
安装 IronPDF for Java 是一个简单的过程,前提是满足所有要求。 本指南将使用 JetBrains IntelliJ IDEA 演示安装并运行一些示例代码。
这是需要做的事:
启动 IntelliJ IDEA:在您的系统上打开 JetBrains IntelliJ IDEA。
创建一个Maven项目:在IntelliJ IDEA中,创建一个新的Maven项目。 这将为安装IronPDF for Java提供合适的环境。
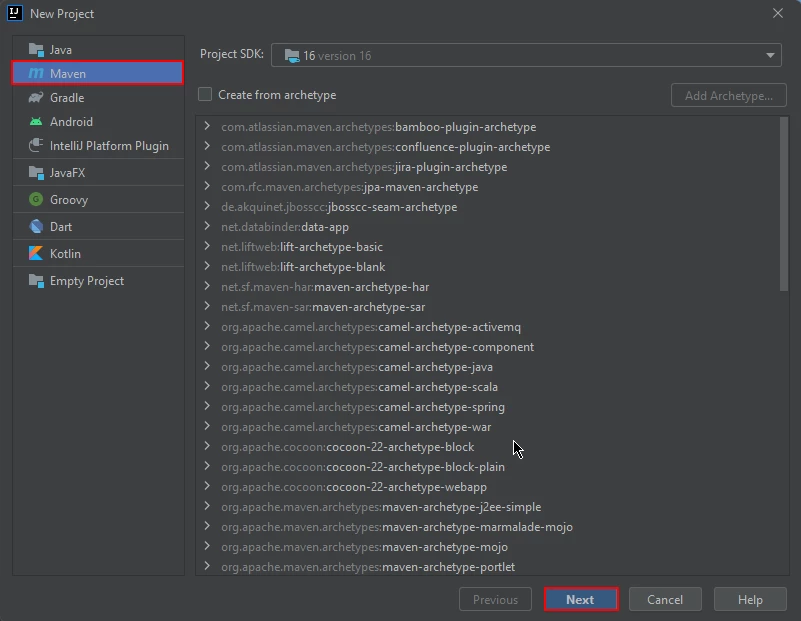
创建一个新的Maven项目
一个新窗口将会出现。 输入项目名称,然后点击完成。
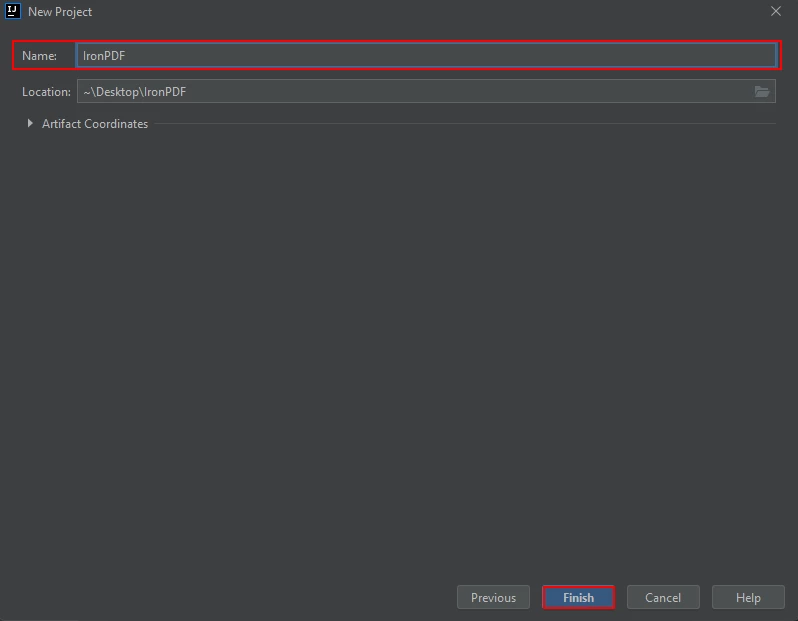
输入项目名称
点击完成后,一个新项目将打开pom.xml文件,以添加IronPDF for Java的Maven依赖项。
接下来,在pom.xml文件中添加以下依赖项,或者您可以从以下Maven 仓库下载 JAR 文件。
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>com.ironsoftware</artifactId>
<version>2025.4.4</version>
</dependency>
将依赖项放入pom.xml文件后,文件的右上角将出现一个小图标。
!如何在 Java 中从 PDF 提取图像,图 3:带有小图标用于安装依赖项的 pom.xml 文件
带有小图标以安装依赖项的pom.xml文件
点击此图标安装IronPDF for Java的Maven依赖。 这只需要几分钟,具体取决于您的网络连接。
您可以使用IronPDF中的一个名为[extractAllImages](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllImages()的方法从PDF文档中提取图像。 此方法返回 PDF 文件中所有可用的图像。之后,您可以使用 ImageIO.write 方法提供输出图像的路径和格式,将所有提取的图像保存到您选择的文件路径。
在以下示例中,PDF文档中的图像将被提取并保存到文件系统中作为PNG图像。
import com.ironsoftware.ironpdf.PdfDocument;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class main {
public static void main(String[] args) throws Exception {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("Final Project Report Craft Arena.pdf"));
List<BufferedImage> images = pdf.extractAllImages();
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("image" + ++i + ".png")));
}
}
}上面的程序打开 "Final Project Report Craft Arena.pdf" 文件,并使用 extractAllImages 方法将文件中的所有图像提取到 BufferedImage 对象的列表中。 然后将每个新文件图像保存到具有唯一名称的单独PNG文件中。
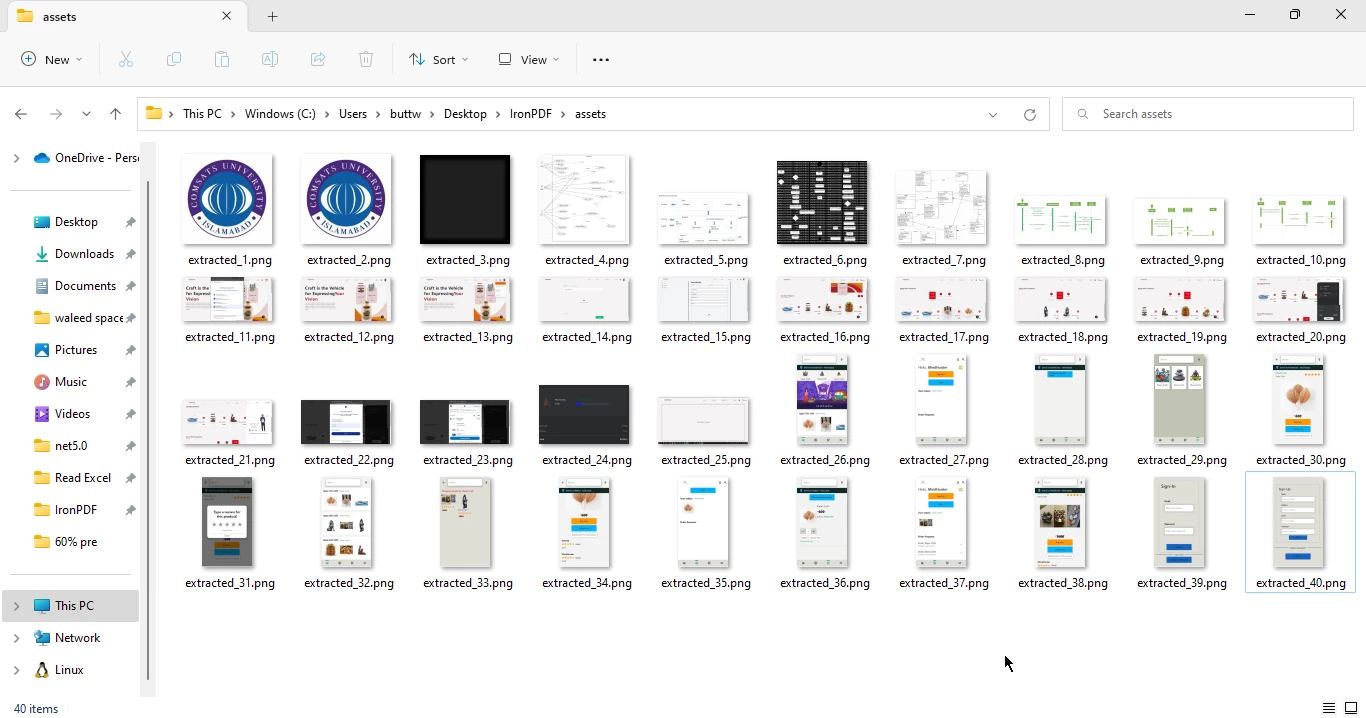
从PDF提取图像输出
本节将讨论如何直接从URL中提取图像。 在下面的代码中,URL 会被转换成 PDF 页面,然后切换导航以从 PDF 中提取图像。
import com.ironsoftware.ironpdf.PdfDocument;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class main {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com/?tag=hp2-brobookmark-us-20");
List<BufferedImage> images = pdf.extractAllImages();
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("image" + ++i + ".png")));
}
}
}在上述代码中,提供了亚马逊主页的URL作为输入,并返回了74张图片。
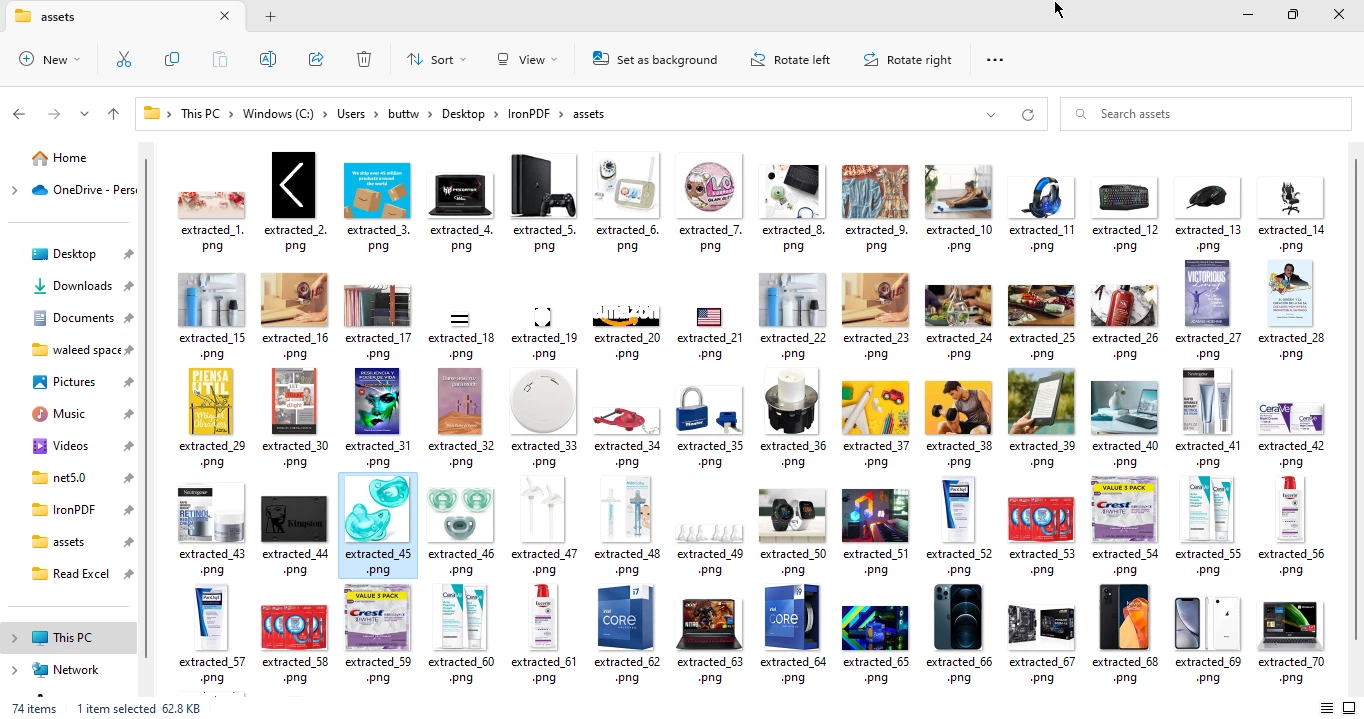
从PDF提取图像输出
使用IronPDF库在Java中可以从PDF文档中提取图像。 要安装IronPDF,您需要安装Java、一个Java IDE(Eclipse或IntelliJ)、Maven,以及将IronPDF库安装并集成到您的项目中。 使用IronPDF从PDF文档中提取图像的过程非常简单,只需调用extractAllImages方法即可。 然后,您可以使用ImageIO.write方法将图像保存到您选择的文件路径。
本文提供了一个循序渐进的指南,介绍了如何使用Java和IronPDF库从PDF文档中提取图像。 有关如何从PDF中提取文本的更多详细信息,请参见提取文本代码示例。
达瑞乌斯·塞兰特拥有迈阿密大学计算机科学学士学位,目前在Iron Software担任全栈WebOps营销工程师。从小对编码的热爱使他认为计算机既神秘又易接近,成为创意和解决问题的完美媒介。
在Iron Software,达瑞乌斯乐于创造新事物并简化复杂概念,使其更易于理解。作为我们在职开发者之一,他还自愿教授学生,将他的专业知识传授给下一代。
对达瑞乌斯而言,他的工作之所以令人满足,是因为它具有价值并产生了真正的影响。

<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2025.4.4</version>
</dependency>
无需信用卡
您的试用密钥应该在邮件中。![]() 试用表格已
试用表格已
成功提交。
如果没有,请联系
support@ironsoftware.com

免费开始
无需信用卡
在生产环境中测试,无水印。
随时随地满足您的需求。
获得30天的全功能产品。
几分钟内就能启动并运行。
在您的产品试用期间,全面访问我们的支持工程团队。






预约30分钟的个人演示。
无需合同,无需卡片信息,无需承诺。

