
在实际环境中测试
在生产环境中测试,无水印。
随时随地满足您的需求。
Java PDF 图书馆


本教程将向您展示如何使用IronPDF for Java从PDF文件中提取数据。通过代码示例解释了设置环境、导入库、读取输入文件和提取所需数据的过程。
IronPDF是一个软件库,为开发人员提供生成和编辑的能力。使用 IronPDF for Java 从 PDF 文件中提取数据在他们的Java应用程序中。 它允许你从 HTML 文档创建 PDF图像等,以及合并多个PDF文件, 分割 PDF 文件以及操作现有的PDF。 IronPDF还提供了对PDF进行安全保护的功能密码保护功能和为 PDF 添加数字签名以及其他功能。
IronPDF for Java 由 Iron Software 开发和维护。 其中最受好评的功能之一是从PDF文件以及HTML和URL中提取文本和数据。
使用IronPDF从PDF文件中提取数据,您必须满足以下先决条件:
Java 安装: 确保您的系统上已安装 Java,并在环境变量中设置了 Java 的路径。 如果你还没有安装Java,请参考这个Java 网站上的下载页面说明。
Java IDE: 安装一个像Eclipse或IntelliJ这样的Java集成开发环境。 您可以从此处下载EclipseEclipse 下载页面和 IntelliJIntelliJ 下载页面.
IronPDF 库: 下载并将 IronPDF 库添加为项目中的依赖项。 访问IronPDF 设置说明页面安装说明。
安装IronPDF for Java很简单,只要满足所有要求。 本指南将使用 JetBrains 的 IntelliJ IDEA 演示安装和运行示例代码。
这是需要做的事:
打开 IntelliJ IDEA:在您的系统上启动 JetBrains IntelliJ IDEA。
创建一个Maven项目:在IntelliJ IDEA中,创建一个新的Maven项目。 这将为安装IronPDF for Java提供合适的环境。
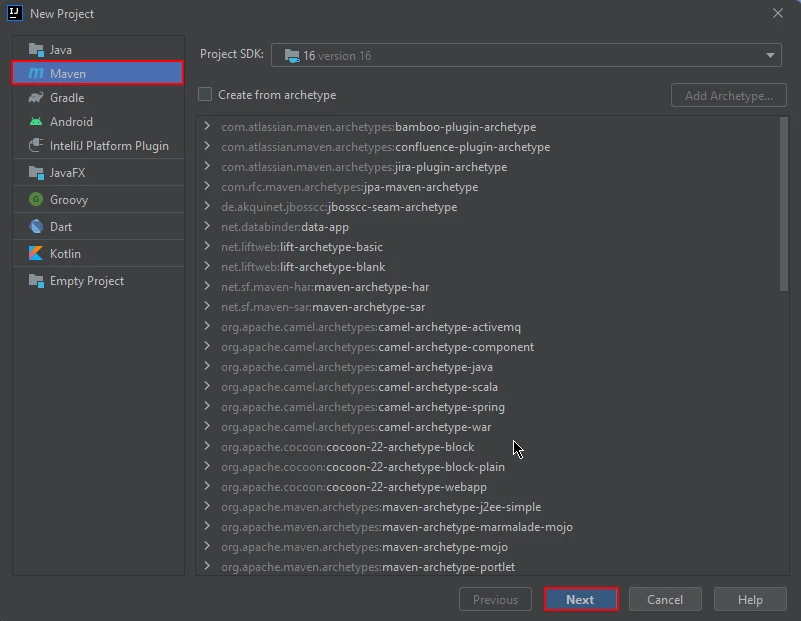
在 IntelliJ 中创建新的 Maven 项目
一个新窗口将会出现。 输入项目名称,然后点击完成。
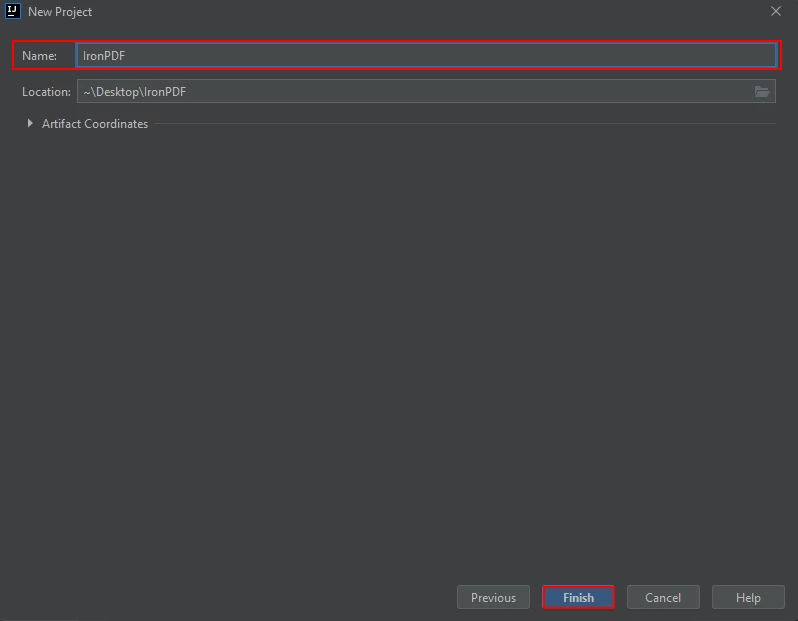
命名 Maven 项目并点击完成
单击完成后,将打开一个带有 pom.xml 的新项目。 这将用于添加IronPDF Java Maven依赖项。
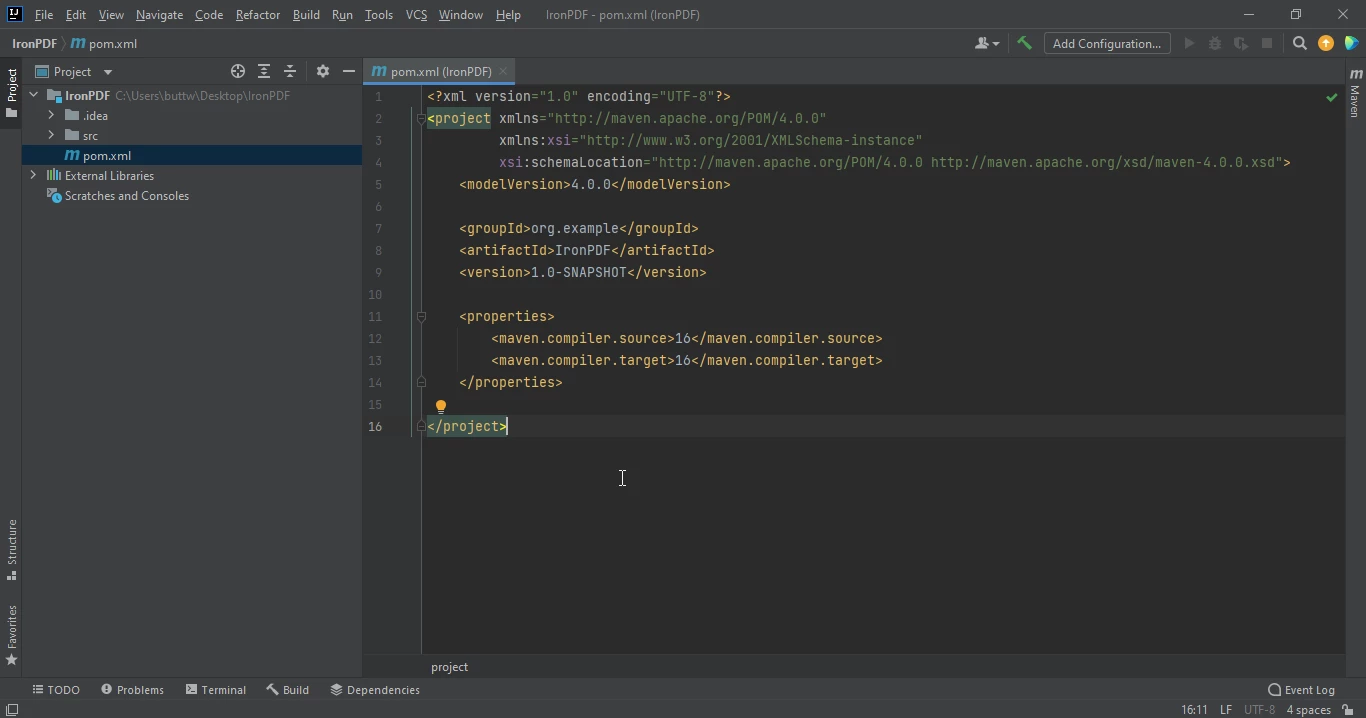
pom.xml 文件
在 "pom.xml "文件中添加以下依赖项,或者您可以从IronPDF 库在 Sonatype Central 上的页面.
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>com.ironsoftware</artifactId>
<version>2025.4.4</version>
</dependency>
一旦你将依赖项放置在pom.xml文件中,文件的右上角会出现一个小图标。
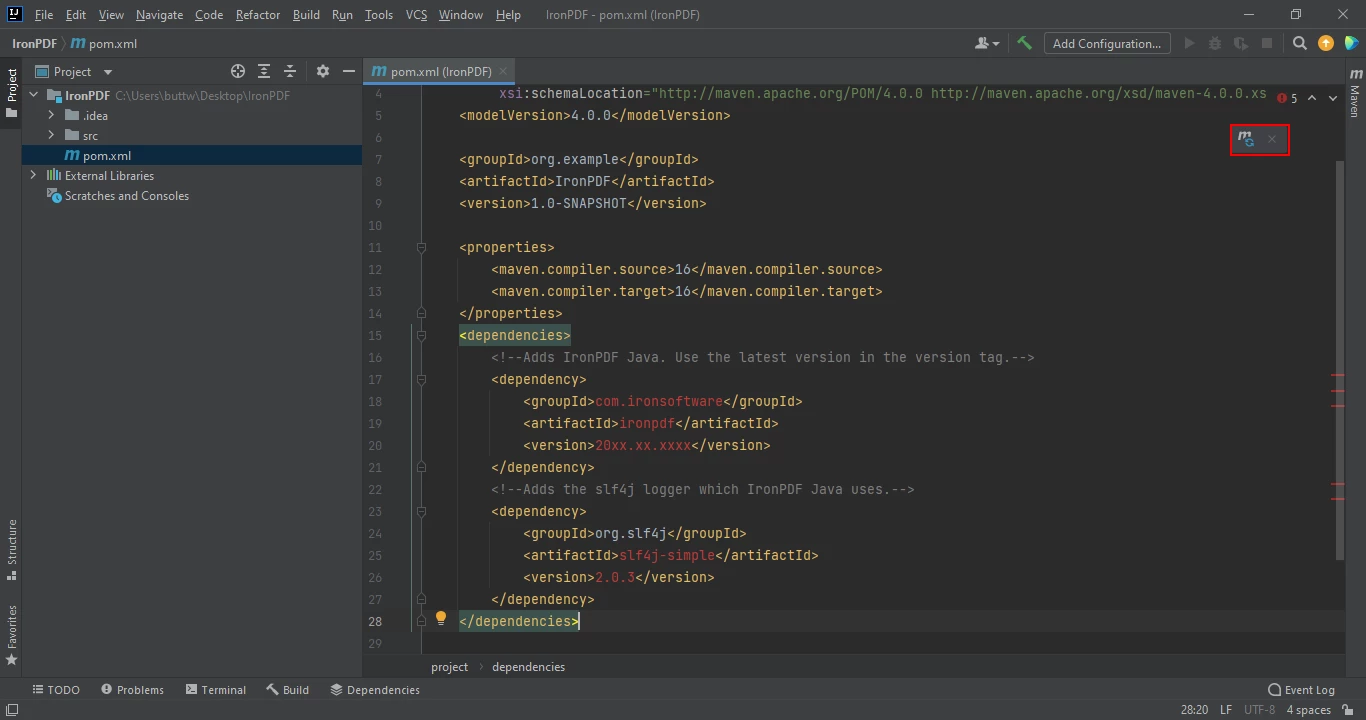
点击浮动图标自动安装Maven依赖
通过点击此按钮安装IronPDF for Java的Maven依赖项。 根据您的互联网连接速度,这应该只需要几分钟。
IronPDF 是一个用于创建、编辑和从PDF文档中提取数据的Java库。 它提供了一个简单的API,从PDF文件、URL和表格中提取文本。
使用IronPDF for Java,您可以轻松地从PDF文档中提取文本数据。 下面是从PDF文件提取数据的示例代码。
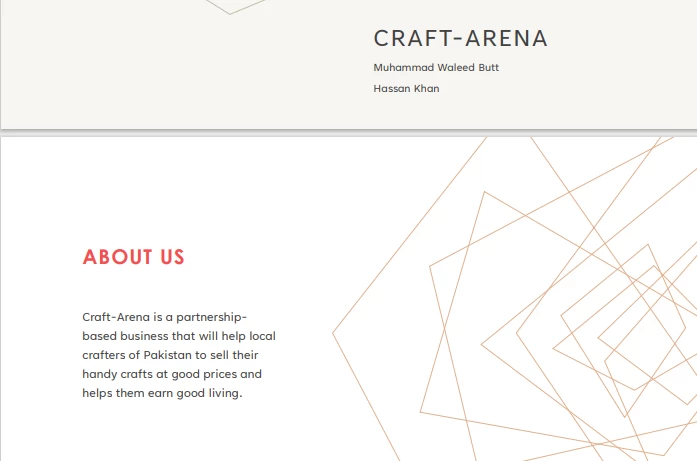
PDF输入
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business plan.pdf"));
String text = pdf.extractAllText();
System.out.println("Text extracted from the PDF: " + text);
}
}源代码的输出结果如下:
> Text extracted from the PDF:
>
> CRAFT-ARENA
>
> Muhammad Waleed Butt
>
> Hassan Khan
>
> ABOUT US
>
> Craft-Arena is a partnershipbased business that will help local crafters of Pakistan to sell their handy crafts at good prices and helps them earn good living.IronPDF for Java在运行时将URL转换为PDF并从中提取文本。 此示例将查看从URL提取文本的源代码。
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
// new PDF parser
String text = pdf.extractAllText();
System.out.println("Text extracted from the URLs: " + text);
}
}
提取的网页数据
使用 IronPDF for Java 从 PDF 中提取表格数据非常简单; 您只需要一个包含表格的PDF文件,并运行以下代码。
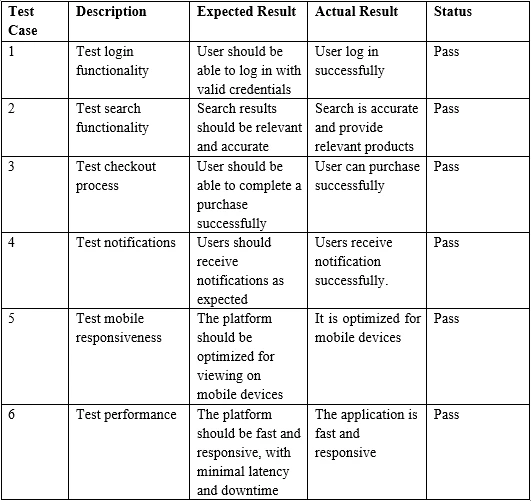
Sample PDF 表格输入
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("table.pdf"));
String text = pdf.extractAllText();
System.out.print("Text extracted from the Marked tables: " + text);
}
}> Test Case Description Expected Result Actual Result Status
>
> 1 Test login functionality User should be able to log in with valid credentials
>
> User log in successfully Pass
>
> 2 Test search functionality Search results should be relevant and accurate
>
> Search is accurate and provide relevant products Pass
>
> 3 Test checkout process User should be able to complete a purchase successfully
>
> User can purchase successfully Pass总之,本教程演示了如何使用IronPDF for Java从PDF文件中提取数据,特别是表格数据。
欲了解更多信息,请参阅从 PDF 示例中提取文本在 IronPDF 网站上。
IronPDF 是一个具有商业许可详细信息,从 $749 开始。 但是,您可以在生产环境中评估它, 使用 IronPDF 试用许可证免费试用.
达瑞乌斯·塞兰特拥有迈阿密大学计算机科学学士学位,目前在Iron Software担任全栈WebOps营销工程师。从小对编码的热爱使他认为计算机既神秘又易接近,成为创意和解决问题的完美媒介。
在Iron Software,达瑞乌斯乐于创造新事物并简化复杂概念,使其更易于理解。作为我们在职开发者之一,他还自愿教授学生,将他的专业知识传授给下一代。
对达瑞乌斯而言,他的工作之所以令人满足,是因为它具有价值并产生了真正的影响。

<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2025.4.4</version>
</dependency>
无需信用卡
您的试用密钥应该在邮件中。![]() 试用表格已
试用表格已
成功提交。
如果没有,请联系
support@ironsoftware.com

免费开始
无需信用卡
在生产环境中测试,无水印。
随时随地满足您的需求。
获得30天的全功能产品。
几分钟内就能启动并运行。
在您的产品试用期间,全面访问我们的支持工程团队。






预约30分钟的个人演示。
无需合同,无需卡片信息,无需承诺。

