
在实际环境中测试
在生产中测试无水印。
随时随地为您服务。
Java PDF 图书馆

Google HTTP客户端库是一个健壮的库,旨在简化在Java应用程序中发出HTTP请求和处理响应的过程。 它是 Google 应用引擎和 Google API 客户端的一部分,属于 Google Apis 的一部分。由 Google 开发和维护,这个强大的 Java 库支持多种 HTTP 方法,并与 JSON 数据模型和 XML 数据模型无缝集成,是希望与网络服务交互的开发人员的绝佳选择。 另外,我们将探索IronPDF用于Java,并演示如何将其集成到Google HTTP 客户端库从HTTP响应数据生成PDF文档。
简化的HTTP请求:该库抽象了创建和发送HTTP请求的大部分复杂性,从而使开发人员更容易使用。
支持多种身份验证方法:支持OAuth 2.0和其他身份验证方案,这对于与现代API进行交互至关重要。
JSON和XML解析:该库可以自动将JSON和XML响应解析为Java对象,减少样板代码。
异步请求:它支持异步请求,可以通过将网络操作卸载到后台线程来提高应用程序性能。
内置重试机制:该库包括一个内置的重试机制,用于处理瞬态网络错误,可以帮助提高应用程序的稳健性。

要使用 Google HTTP 客户端库 for Java,您必须将完整的客户端库和必要的依赖项添加到您的项目中。 如果您使用的是 Maven,您可以将以下依赖项添加到您的 pom.xml 文件中:
<dependencies>
<dependency>
<groupId>com.google.http-client</groupId>
<artifactId>google-http-client</artifactId>
<version>1.39.2</version>
</dependency>
<dependency>
<groupId>com.google.http-client</groupId>
<artifactId>google-http-client-jackson2</artifactId>
<version>1.39.2</version>
</dependency>
</dependencies>让我们通过各种示例来探索Google HTTP Client Library for Java的基本用法。
以下代码演示了如何使用 Google HTTP 客户端库进行完整请求内容简单的 GET 请求:
import com.google.api.client.http.HttpRequest;
import com.google.api.client.http.HttpRequestFactory;
import com.google.api.client.http.HttpResponse;
import com.google.api.client.http.javanet.NetHttpTransport;
import com.google.api.client.http.GenericUrl;
public class HttpClientExample {
public static void main(String[] args) {
try {
HttpRequestFactory requestFactory = new NetHttpTransport().createRequestFactory();
GenericUrl url = new GenericUrl("https://jsonplaceholder.typicode.com/posts/1");
HttpRequest request = requestFactory.buildGetRequest(url);
HttpResponse response = request.execute();
System.out.println(response.parseAsString());
} catch (Exception e) {
e.printStackTrace();
}
}
}在这个例子中,我们创建了一个HttpRequestFactory,并使用它构建和执行对占位符API的GET请求。 我们在这里使用 try-catch 块来降低编译错误的频率,通过在请求失败时捕获异常。 接下来,我们将响应打印到控制台,如下所示。

以下代码演示了如何使用JSON数据发出POST请求:
import com.google.api.client.http.HttpRequest;
import com.google.api.client.http.HttpRequestFactory;
import com.google.api.client.http.HttpResponse;
import com.google.api.client.http.javanet.NetHttpTransport;
import com.google.api.client.http.GenericUrl;
import com.google.api.client.http.json.JsonHttpContent;
import com.google.api.client.json.JsonFactory;
import com.google.api.client.json.jackson2.JacksonFactory;
import java.util.HashMap;
import java.util.Map;
public class HttpClientExample {
public static void main(String[] args) {
try {
HttpRequestFactory requestFactory = new NetHttpTransport().createRequestFactory();
GenericUrl url = new GenericUrl("https://jsonplaceholder.typicode.com/posts");
Map<String, Object> jsonMap = new HashMap<>();
jsonMap.put("title", "foo");
jsonMap.put("body", "bar");
jsonMap.put("userId", 1);
JsonFactory jsonFactory = new JacksonFactory();
JsonHttpContent content = new JsonHttpContent(jsonFactory, jsonMap);
HttpRequest request = requestFactory.buildPostRequest(url, content);
HttpResponse response = request.execute();
System.out.println(response.parseAsString());
} catch (Exception e) {
e.printStackTrace();
}
}
}在此示例中,我们创建一个 JSON 对象并使用 JsonHttpContent 将其发送到一个 POST 请求中。然后将响应打印到控制台。

IronPDF是一个强大的库,专为Java开发人员设计,简化了创建、编辑和管理PDF文档的过程。 它提供了广泛的功能,包括将HTML转换为PDF、操作现有PDF文件以及从PDF中提取文本和图像。
HTML 转换为 PDF:以高保真度将 HTML 内容转换为 PDF。
操作现有PDF:合并、拆分和修改现有的PDF文档。
文本和图像提取:从 PDF 文档中提取文本和图像以进行进一步处理。
水印和注释:向PDF文件添加水印、注释和其他增强功能。
要在您的 Java 项目中使用 IronPDF,您需要包含 IronPDF 库。 您可以从IronPDF网站下载JAR文件,或使用Maven等构建工具将其包含在您的项目中。 对于使用 Maven 的用户,请在您的 pom.xml 中添加以下代码:
<!--Adds IronPDF Java. Use the latest version in the version tag.-->
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2023.12.1</version>
</dependency>
<!--Adds the slf4j logger which IronPDF Java uses.-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.3</version>
</dependency>在本节中,我们将演示如何使用Google HTTP客户端库从网络服务中获取HTML内容,然后使用IronPDF将该HTML内容转换为PDF文档。
import com.google.api.client.http.HttpRequest;
import com.google.api.client.http.HttpRequestFactory;
import com.google.api.client.http.HttpResponse;
import com.google.api.client.http.javanet.NetHttpTransport;
import com.google.api.client.http.GenericUrl;
import com.google.api.client.json.JsonFactory;
import com.google.api.client.json.jackson2.JacksonFactory;
import com.google.api.client.http.json.JsonHttpContent;
import com.google.api.client.auth.oauth2.Credential;
import com.google.api.client.auth.oauth2.CredentialAccessMethod;
import com.google.api.client.auth.oauth2.TokenResponse;
import com.google.api.client.auth.oauth2.TokenResponseException;
import com.google.api.client.auth.oauth2.TokenRequest;
import com.google.api.client.auth.oauth2.AuthorizationCodeFlow;
import com.google.api.client.auth.oauth2.AuthorizationCodeRequestUrl;
import com.google.api.client.auth.oauth2.AuthorizationCodeTokenRequest;
import com.google.api.client.auth.oauth2.ClientParametersAuthentication;
import com.google.api.client.json.JsonGenerator;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import com.ironsoftware.ironpdf.PdfDocument;
public class HtmlToPdfExample {
public static void main(String[] args) {
try {
// Fetch HTML content using Google HTTP Client Library
HttpRequestFactory requestFactory = new NetHttpTransport().createRequestFactory();
GenericUrl url = new GenericUrl("https://jsonplaceholder.typicode.com/posts/1");
HttpRequest request = requestFactory.buildGetRequest(url);
HttpResponse response = request.execute();
String htmlContent = response.parseAsString();
// Convert HTML content to PDF using IronPDF
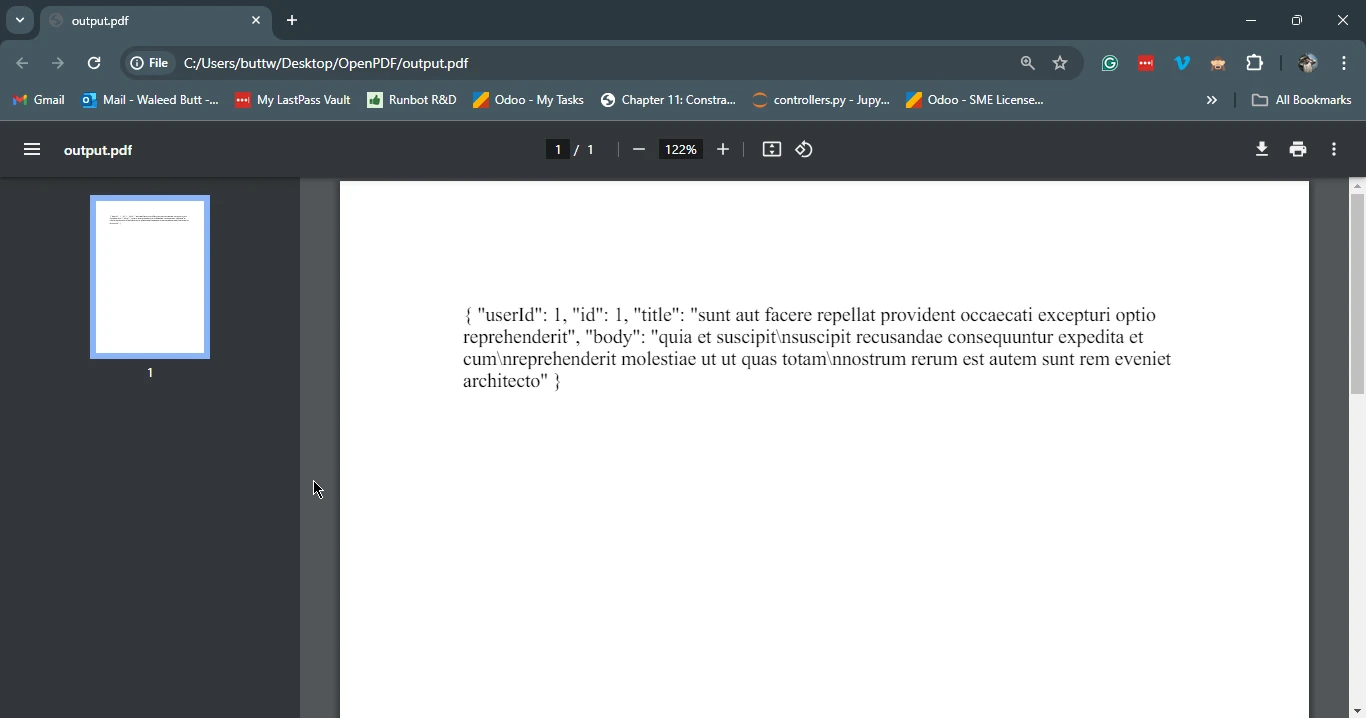
PdfDocument pdf = PdfDocument.renderHtmlAsPdf(htmlContent);
pdf.saveAs("output.pdf");
System.out.println("PDF created successfully!");
} catch (Exception e) {
e.printStackTrace();
}
}
}在此示例中,我们首先使用 Google HTTP 客户端库从占位符 API 获取 HTML 内容。 然后,我们使用IronPDF将获取的HTML内容转换为PDF文档,并保存为output.pdf。
Google HTTP Client Library for Java 是一个强大的工具,用于与网络服务交互,提供简化的 HTTP 请求,支持多种身份验证方法,无缝集成 JSON 和 XML 解析,并兼容各种 Java 环境。 结合IronPDF,开发人员可以轻松从网络服务获取HTML内容并将其转换为PDF文档,从而为各种应用提供完整的库,从生成报告到为Web应用创建可下载内容。 通过利用这两个库,Java开发人员可以显著增强其应用程序的功能,同时减少代码的复杂性。
请参阅以下内容链接.

<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2025.2.8</version>
</dependency>
无需信用卡
您的试用密钥应在电子邮件中。![]()
试用表格已提交
成功地.
如果不是,请联系
support@ironsoftware.com

免费开始
无需信用卡
在生产中测试无水印。
随时随地为您服务。
获取30天的完全功能产品。
几分钟内即可启动和运行。
在您的产品试用期间,全面访问我们的支持工程团队。








