
在实际环境中测试
在生产环境中测试,无水印。
随时随地满足您的需求。
C# PDF库
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


本教程介绍如何利用 IronPDF 的一流支持,以编程方式从 PDF 文件中提取文本和图像。
高效的 PDF 转换。 机器能做的事情,IronPDF 几乎都能做到。 有了这个 PDF 库,开发人员可以快速创建、阅读文本内容、编写、加载和操作 PDF。
IronPdf 借助 Chrome 引擎将 HTML 转换为 PDF 记录。以及 Windows Forms、HTML、ASPX、Razor HTML、.NET Core、ASP.NET、Windows Forms 和 WPF。 IronPdf 还支持 Xamarin、Blazor、Unity 和 HoloLense 应用程序。 IronPDF 支持 Microsoft .NET 和 .NET Core 应用程序(包括 ASP.NET Web 包和常规 Windows 包)。 IronPDF 可用于制作美观的 PDF。
IronPdf 可以使用 HTML5、JavaScript、CSS 和图像创建 PDF。 IronPDF 还有一个功能强大的 HTML 到 PDF 转换器,可与 PDF 集成。 IronPDF 采用 Chromium 渲染引擎,拥有强大的 PDF 转换机制。它还与任何外部资源无关。
您可以从 CSS 文件创建 PDF 文件。
欲了解更多详情,请访问此IronPDF许可信息页面,获取免费限量钥匙和专业版。

IronPDF- 字体格式化
借助 IronPDF 库,IronPDF 还可以从 PDF 文件中读取和提取文本。 以下是 IronPDF 代码的一种模式,可用于检查当前的 PDF 文件。
下面的代码示例演示了第一种方法,只需几行代码就能以字符串形式获取所有 PDF 内容。
Imports IronPdf
Module Program
Sub Main(args As String())
Dim AllText As String
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
AllText = pdfdoc.ExtractAllText()
Console.WriteLine(AllText)
End Sub
End ModuleImports IronPdf
Module Program
Sub Main(args As String())
Dim AllText As String
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
AllText = pdfdoc.ExtractAllText()
Console.WriteLine(AllText)
End Sub
End Module以上示例代码演示了如何使用FromFile方法从现有文件中读取PDF并将其转换为PDF文档对象。 该对象提供了一个名为ExtractAllText的方法,该方法将从PDF中提取纯文本并将其转换为字符串。
下面的示例代码展示了如何使用页码从 PDF 文件中提取数据。
Imports IronPdf
Module Program
Sub Main(args As String())
Dim AllText As String
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
AllText = pdfdoc.ExtractTextFromPage(0)
Console.WriteLine(AllText)
End Sub
End ModuleImports IronPdf
Module Program
Sub Main(args As String())
Dim AllText As String
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
AllText = pdfdoc.ExtractTextFromPage(0)
Console.WriteLine(AllText)
End Sub
End Module上面的代码显示了如何从现有文件中读取PDF并使用FromFile函数将其转换为PDF文档对象。 可使用此对象访问 PDF 上的文本和图像。 该对象提供了一个名为ExtractTextFromPage的方法,它允许将页码作为参数传递,以获取包含PDF页面上每个单词的字符串。
下面的代码显示了如何提取多个页面之间的数据。
Imports IronPdf
Module Program
Sub Main(args As String())
Dim Pages As List(Of Integer) = New List(Of Integer)
Pages.Add(3)
Pages.Add(5)
Pages.Add(7)
Dim AllText As String
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
AllText = pdfdoc.ExtractTextFromPages(Pages)
Console.WriteLine(AllText)
End Sub
End ModuleImports IronPdf
Module Program
Sub Main(args As String())
Dim Pages As List(Of Integer) = New List(Of Integer)
Pages.Add(3)
Pages.Add(5)
Pages.Add(7)
Dim AllText As String
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
AllText = pdfdoc.ExtractTextFromPages(Pages)
Console.WriteLine(AllText)
End Sub
End Module上面的代码演示了如何使用FromFile方法从现有文件中读取PDF并将其转换为PDF文档对象。 该对象允许检查 PDF 格式的文本和图像。 该对象有一个名为ExtractTextFromPages的方法,可以通过传递页码列表作为参数来获取包含文档指定页面上所有文本内容的字符串。 下面左侧是源 PDF,右侧是提取的数据。
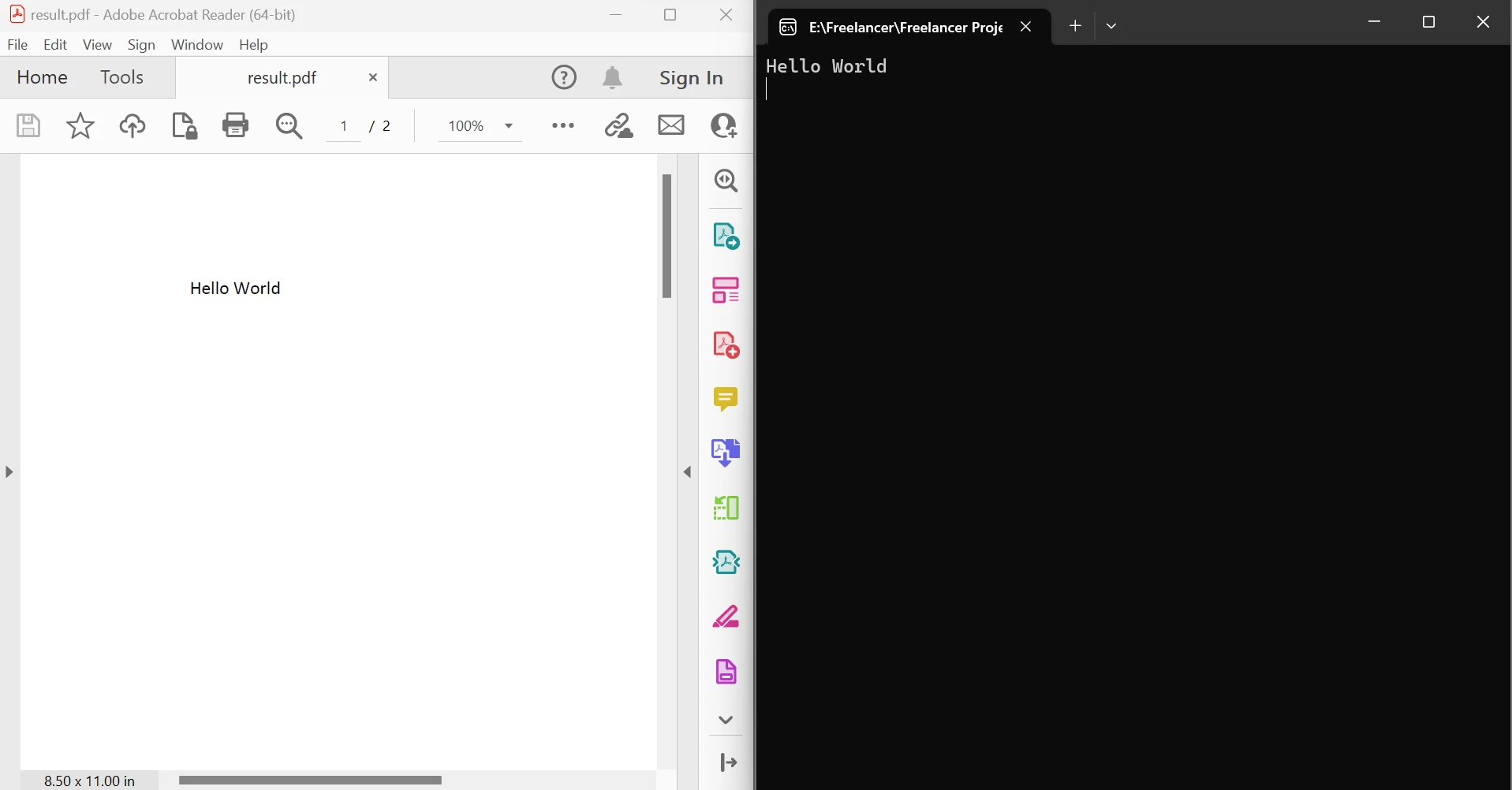
提取页面之间的文本输出
IronPDF 提供了一系列提取图像的方法,如:
从页面提取位图ExtractBitmapsFromPagesExtractImagesFromPage从页面提取图像ExtractRawImagesFromPage每种方法都可以从文档的一页或多页中提取图像。
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
Dim images = pdfdoc.ExtractRawImagesFromPage(1)
For Each As Byte() In images
Dim ms As New IO.MemoryStream(CType(, Byte()))
Dim image = New Bitmap(ms)
image.Save("output//test.jpg")
NextDim pdfdoc = PdfDocument.FromFile("result.pdf")
Dim images = pdfdoc.ExtractRawImagesFromPage(1)
For Each As Byte() In images
Dim ms As New IO.MemoryStream(CType(, Byte()))
Dim image = New Bitmap(ms)
image.Save("output//test.jpg")
Next上面的代码展示了如何从现有文件中读取文档,并使用FromFile函数将其转换为PDF文档对象。 通过将页面编号列表传递给对象的ExtractRawImagesFromPage方法,可以获得一个包含文档中指定页面上每张图片的字节列表。 使用foreach循环来处理每个字节并将其转换为内存流。 然后转换成位图,以便于保存图片。 下图显示了上述代码的输出结果。

从PDF输出中提取图像
要了解有关IronPDF API代码教程的更多信息,请参阅IronPDF文档。 您也可以访问其他教程,学习如何使用C# 解析PDF文本。
IronPDF 库的开发许可是免费的。 如果在生产环境中使用 IronPdf,可以根据开发人员的需求购买不同的许可证。 Lite计划从$749开始,并且没有持续费用。 此外,还提供 SaaS 和 OEM 再分发替代方案。 所有许可证均包括更新、一年的产品支持和永久许可证。 这些工具还可用于制造、暂存和开发。 这是一次性购买。 您还可以获得额外的免费、有时间限制的许可证。 访问IronPDF的全面许可信息,以阅读有关IronPDF的完整定价和许可详细信息。 IronPdf 还提供免费的复制保护许可证。
无需信用卡
您的试用密钥应该在邮件中。![]() 试用表格已
试用表格已
成功提交。
如果没有,请联系
support@ironsoftware.com
免费开始
无需信用卡
在生产环境中测试,无水印。
随时随地满足您的需求。
获得30天的全功能产品。
几分钟内就能启动并运行。
在您的产品试用期间,全面访问我们的支持工程团队。





预约30分钟的个人演示。
无需合同,无需卡片信息,无需承诺。

