
在实际环境中测试
在生产环境中测试,无水印。
随时随地满足您的需求。
C# PDF库
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


用 C# 从 PDF 文件中提取数据是一项相当大的挑战。 数据可以是文本、图像、图表、图形、表格等形式。有时,业务分析人员需要提取数据以进行数据分析,并根据分析结果做出决策。 IronPDF C# PDF Library 是从 PDF 文件中提取数据的绝佳解决方案。
本文将演示如何使用 IronPDF 库用 C# 从 PDF 文档中提取表格数据。
IronPDF 是一个 C# .NET 库解决方案,用于在 .NET 中生成 PDF,帮助开发人员在其软件应用程序中轻松读取、创建和编辑 PDF 文档。 其 Chromium 引擎可准确、快速地渲染 PDF 文档。 它允许开发人员从不同格式无缝转换为 PDF,反之亦然。 它支持最新的 .NET 7 Framework 以及 .NET Framework 6、5、4、.NET Core 和 Standard。
此外,IronPDF .NET API 还能让开发人员轻松操作和编辑 PDF、添加页眉和页脚,以及从 PDF 中提取文本、图像和表格。
要从 PDF 文档中提取表格数据,我们需要在本地计算机系统中安装以下组件:
Visual Studio - Visual Studio 2022 是官方的 C# 开发 IDE,必须安装在计算机上。 请从Visual Studio 网站下载并安装。
创建项目 - 创建一个用于提取数据的控制台应用程序。 请按照以下步骤创建项目:
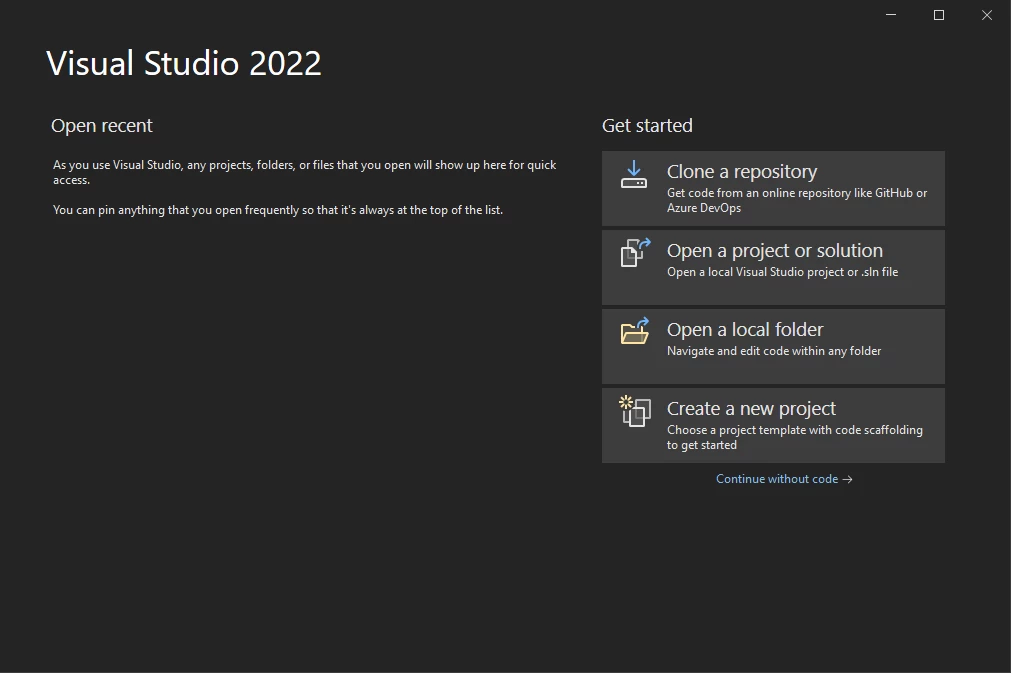
Visual Studio 的启动界面
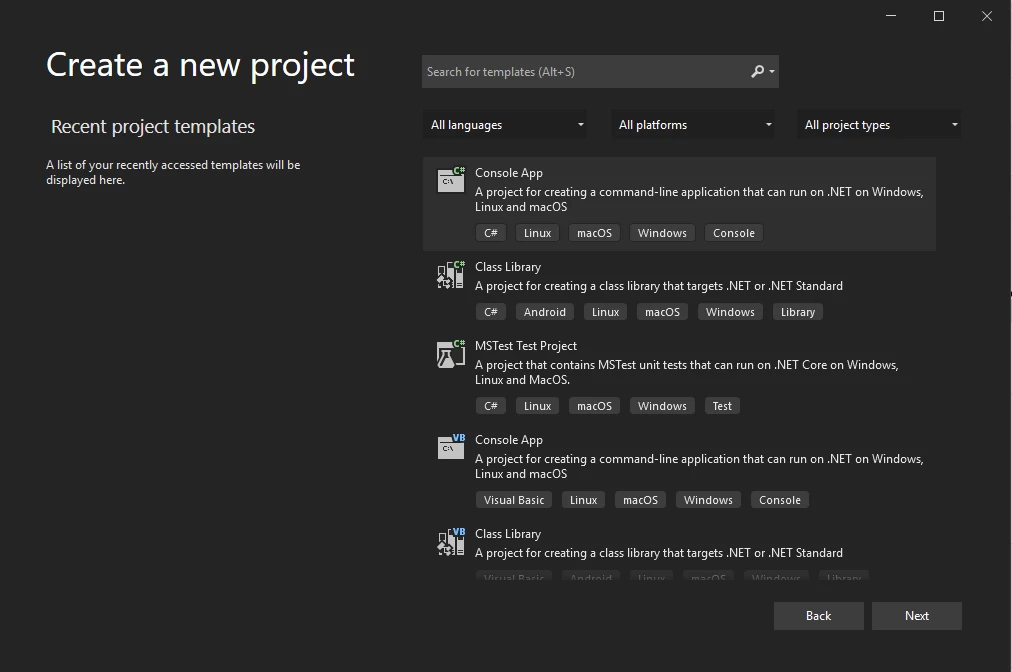
在 Visual Studio 中创建一个新的控制台应用程序

配置新创建的应用程序
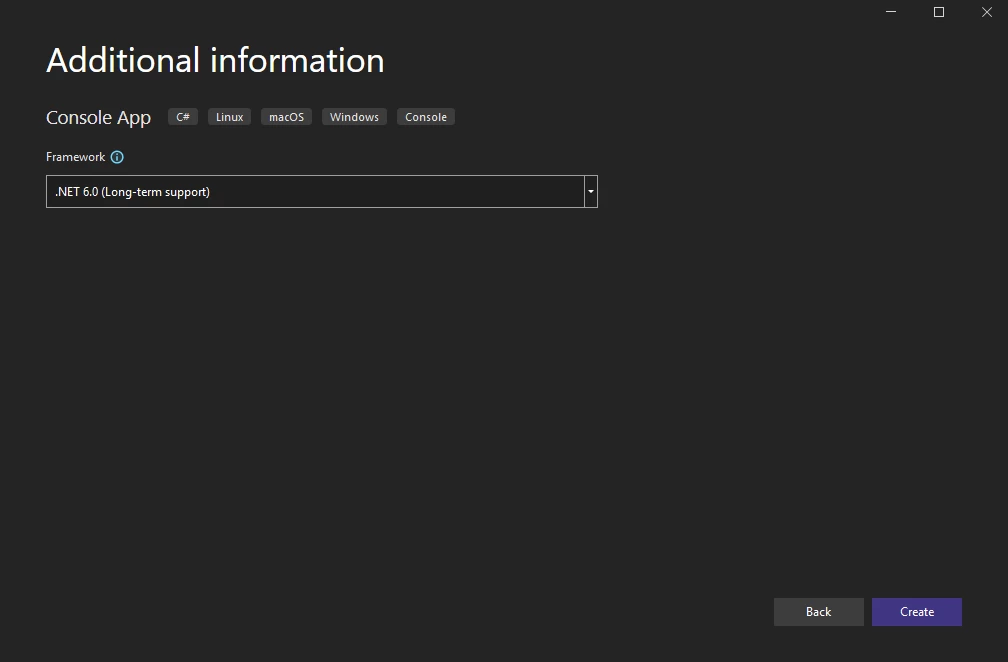
选择一个 .NET Framework
安装 IronPDF - 有三种不同的方法来安装 IronPDF 库。 它们如下
使用 Visual Studio。 Visual Studio 包含 NuGet 软件包管理器,可帮助在 C# 应用程序中安装所有 NuGet 软件包。
单击顶部菜单中的工具,或

工具和管理 NuGet 包
- 打开 NuGet 包管理器后,浏览 IronPDF 并点击安装,如下图所示:
工具和管理 NuGet 包
直接下载 NuGet 包。 另一个轻松下载和安装 IronPDF 的方法是访问其 NuGet 包页面。
在创建任何内容之前,需要将 IronPDF 命名空间添加到文件中,并设置许可证密钥以使用 IronPDF 库中的ExtractText方法。
using IronPdf;
License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";using IronPdf;
License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";Imports IronPdf
License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY"在这里,将从一个包含表格的 HTML 字符串创建一个 PDF 文档,然后使用 IronPdf 提取这些数据。 HTML 保存在一个字符串变量中,代码如下:
string HTML = "<html>" +
"<style>" +
"table, th, td {" +
"border:1px solid black;" +
"}" +
"</style>" +
"<body>" +
"<h1>A Simple table example</h2>" +
"<table>" +
"<tr>" +
"<th>Company</th>" +
"<th>Contact</th>" +
"<th>Country</th>" +
"</tr>" +
"<tr>" +
"<td>Alfreds Futterkiste</td>" +
"<td>Maria Anders</td>" +
"<td>Germany</td>" +
"</tr>" +
"<tr>" +
"<td>Centro comercial Moctezuma</td>" +
"<td>Francisco Chang</td>" +
"<td>Mexico</td>" +
"</tr>" +
"</table>" +
"<p>To understand the example better, we have added borders to the table.</p>" +
"</body>" +
"</html>";string HTML = "<html>" +
"<style>" +
"table, th, td {" +
"border:1px solid black;" +
"}" +
"</style>" +
"<body>" +
"<h1>A Simple table example</h2>" +
"<table>" +
"<tr>" +
"<th>Company</th>" +
"<th>Contact</th>" +
"<th>Country</th>" +
"</tr>" +
"<tr>" +
"<td>Alfreds Futterkiste</td>" +
"<td>Maria Anders</td>" +
"<td>Germany</td>" +
"</tr>" +
"<tr>" +
"<td>Centro comercial Moctezuma</td>" +
"<td>Francisco Chang</td>" +
"<td>Mexico</td>" +
"</tr>" +
"</table>" +
"<p>To understand the example better, we have added borders to the table.</p>" +
"</body>" +
"</html>";Dim HTML As String = "<html>" & "<style>" & "table, th, td {" & "border:1px solid black;" & "}" & "</style>" & "<body>" & "<h1>A Simple table example</h2>" & "<table>" & "<tr>" & "<th>Company</th>" & "<th>Contact</th>" & "<th>Country</th>" & "</tr>" & "<tr>" & "<td>Alfreds Futterkiste</td>" & "<td>Maria Anders</td>" & "<td>Germany</td>" & "</tr>" & "<tr>" & "<td>Centro comercial Moctezuma</td>" & "<td>Francisco Chang</td>" & "<td>Mexico</td>" & "</tr>" & "</table>" & "<p>To understand the example better, we have added borders to the table.</p>" & "</body>" & "</html>"接下来,使用ChromePdfRenderer从HTML字符串创建PDF。 代码如下
ChromePdfRenderer renderer = new ChromePdfRenderer();
PdfDocument pdfDocument = renderer.RenderHtmlAsPdf(HTML);
pdfDocument.SaveAs("table_example.pdf");ChromePdfRenderer renderer = new ChromePdfRenderer();
PdfDocument pdfDocument = renderer.RenderHtmlAsPdf(HTML);
pdfDocument.SaveAs("table_example.pdf");Dim renderer As New ChromePdfRenderer()
Dim pdfDocument As PdfDocument = renderer.RenderHtmlAsPdf(HTML)
pdfDocument.SaveAs("table_example.pdf")SaveAs 方法将 PdfDocument 对象保存为名为 "table_example.pdf" 的 PDF 文件。 保存的文件如下所示:
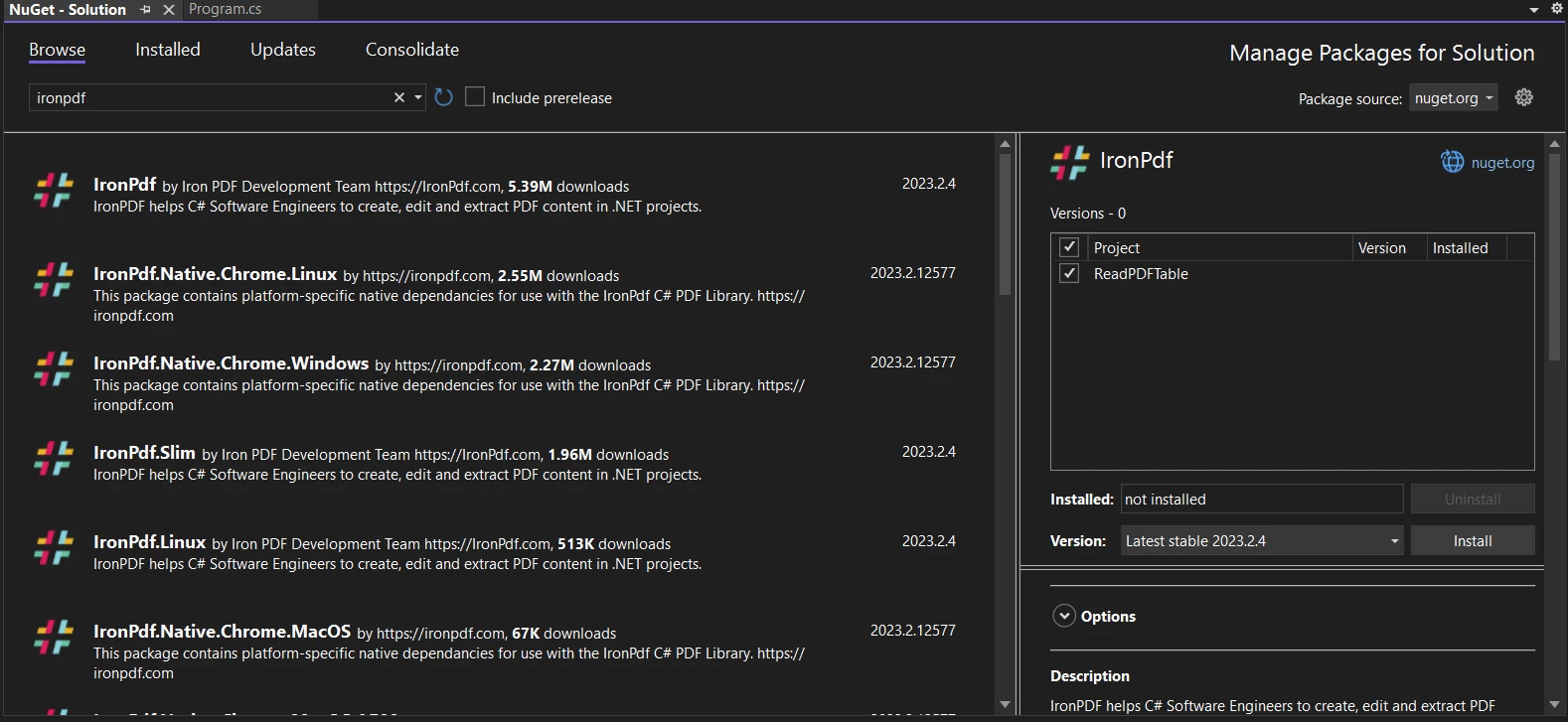
在NuGet包管理器UI中搜索IronPDF
要从 PDF 表格中提取数据,使用 PdfDocument 对象打开文档,然后使用 ExtractAllText 方法检索数据以进行进一步分析。 下面的代码演示了如何完成这项任务:
PdfDocument pdfDocument = new PdfDocument("table_example.pdf");
string text = pdfDocument.ExtractAllText();PdfDocument pdfDocument = new PdfDocument("table_example.pdf");
string text = pdfDocument.ExtractAllText();Dim pdfDocument As New PdfDocument("table_example.pdf")
Dim text As String = pdfDocument.ExtractAllText()上述代码使用ExtractAllText方法分析整个PDF文档,并将提取的数据(包括表格数据)返回到一个字符串变量中。 然后,变量的值可以显示或存储在文件中,以供日后使用。 以下代码可在屏幕上显示:
Console.WriteLine("The extracted Text is:\n" + text);Console.WriteLine("The extracted Text is:\n" + text);Imports Microsoft.VisualBasic
Console.WriteLine("The extracted Text is:" & vbLf & text)
要提取文本的PDF文件
C# 提供了一个 String.Split 方法,可以根据分隔符分割字符串。 以下代码将帮助您将输出限制为表格数据。
string [] textList = text.Split("\n");
foreach (string textItem in textList)
{
if (textItem.Contains("."))
{
continue;
}
else
{
Console.WriteLine(textItem);
}
}string [] textList = text.Split("\n");
foreach (string textItem in textList)
{
if (textItem.Contains("."))
{
continue;
}
else
{
Console.WriteLine(textItem);
}
}Imports Microsoft.VisualBasic
Dim textList() As String = text.Split(vbLf)
For Each textItem As String In textList
If textItem.Contains(".") Then
Continue For
Else
Console.WriteLine(textItem)
End If
Next textItem这个简单的代码示例有助于从提取的文本中仅提取表格单元格数据。 首先,文本行被拆分并保存在字符串数组中。 然后,对每个数组元素进行迭代,跳过末尾带有句号". "的元素。 在大多数情况下,从提取的数据中只检索表格数据,但也可能检索其他行。 输出结果如下

控制台显示提取的文本
从上面的截图可以看出,表格数据的格式和逻辑结构在Console.WriteLine方法的输出中得到了保留。 您可以在此C# 中从 PDF 提取数据的代码示例中找到有关如何使用 IronPDF 从 PDF 文档中提取数据的更多详细信息。
输出结果还可以保存为 CSV 文件,稍后可以对其进行格式化和编辑,以便进行更多的数据分析。 代码如下
using (StreamWriter file = new StreamWriter("table_example.csv", false))
{
string [] textList = text.Split("\n");
foreach (string textItem in textList)
{
if (textItem.Contains("."))
{
continue;
}
else
{
file.WriteLine(textItem);
}
}
}using (StreamWriter file = new StreamWriter("table_example.csv", false))
{
string [] textList = text.Split("\n");
foreach (string textItem in textList)
{
if (textItem.Contains("."))
{
continue;
}
else
{
file.WriteLine(textItem);
}
}
}Imports Microsoft.VisualBasic
Using file As New StreamWriter("table_example.csv", False)
Dim textList() As String = text.Split(vbLf)
For Each textItem As String In textList
If textItem.Contains(".") Then
Continue For
Else
file.WriteLine(textItem)
End If
Next textItem
End Using输出将保存为一个CSV文件,其中每个textItem将是一个列。
本文演示了如何使用 IronPDF 从 PDF 文档中提取数据和表格。 IronPDF 为从 PDF 文件中提取文本提供了多个有用的选项。 它提供了ExtractTextFromPage方法,可以从特定页面提取数据。 IronPDF 还支持将不同格式转换为 PDF,例如markdown 文件或DOCX 文件,以及从 PDF 转换为不同格式。 这样,开发人员就可以轻松地将 PDF 功能集成到应用程序开发过程中。 此外,它不需要使用 Adobe Acrobat Reader 来查看和编辑 PDF 文档。
IronPDF 在开发期间是免费的,可用于商业用途需要获得许可。 它提供免费的试用许可证来测试IronPDF的完整功能。 您可以在此链接上找到更多详细信息。
无需信用卡
您的试用密钥应该在邮件中。![]() 试用表格已
试用表格已
成功提交。
如果没有,请联系
support@ironsoftware.com
免费开始
无需信用卡
在生产环境中测试,无水印。
随时随地满足您的需求。
获得30天的全功能产品。
几分钟内就能启动并运行。
在您的产品试用期间,全面访问我们的支持工程团队。





预约30分钟的个人演示。
无需合同,无需卡片信息,无需承诺。

