
在实际环境中测试
在生产环境中测试,无水印。
随时随地满足您的需求。
C# PDF库
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


在 PDF 文件中查找文本是一项极具挑战性的任务,尤其是在处理不易编辑的静态文件时,或者在翻译 PDF 文件时。可搜索. 无论您是要实现文档工作流自动化、构建搜索功能、需要突出显示符合搜索条件的文本,还是要提取数据,文本提取都是开发人员的一项重要功能。
IronPDF在翻译过程中,.NET 库(一个功能强大的 .NET 库)简化了这一过程,使开发人员能够高效地搜索和翻译这些工具。摘录来自 PDF。 在本文中,我们将探讨如何使用 IronPdf 在 PDF 中使用 C# 查找文本,并提供完整的代码示例和实际应用。
"查找文本 "是指在文档、文件或其他数据结构中搜索特定文本或模式的过程。 就 PDF 文件而言,它涉及在 PDF 文档的文本内容中识别和定位特定单词、短语或模式的实例。 该功能对于各行各业的众多应用都至关重要,尤其是在处理以 PDF 格式存储的非结构化或半结构化数据时。
PDF 文件旨在以一致的、与设备无关的格式呈现内容。 然而,PDF 中文本的存储方式可能会有很大差异。 文本可存储为
复杂布局: 文本以片段或不寻常的编码方式存储,因此难以准确提取和搜索。
这种多变性意味着在 PDF 中进行有效的文本搜索通常需要专门的库,如 IronPDF,能够无缝处理不同的内容类型。
在 PDF 中查找文本的能力有广泛的应用,包括
自动化工作流程: 通过识别 PDF 文档中的关键术语或值,实现处理发票、合同或报告等任务的自动化。
数据提取: 提取信息用于其他系统或分析。
内容核实: 确保文件(如合规声明或法律条款)中包含所需的术语或短语。
由于以下挑战,在 PDF 中查找文本并不总是那么简单:
IronPDFPDF for .NET》旨在为在 .NET 生态系统中工作的开发人员提供尽可能无缝的 PDF 操作。 它提供了一套专门用于简化文本提取和处理流程的功能。
易用性:
IronPDF 的功能包括直观的 API此外,译文还必须能够让开发人员快速上手,而不需要很高的学习曲线。 无论是进行基本的文本提取还是HTML 转换为 PDF无论是.NET、Java、Python 或 Node js,还是高级操作,其方法都简单易用。
高准确性:
有些 PDF 库在处理包含复杂布局或嵌入字体的 PDF 时会遇到困难,而 IronPDF 则不同,它能可靠、精确地提取文本。
跨平台支持:
IronPDF 兼容 .NET Framework 和 .NET Core,确保开发人员可以在现代网络应用程序、桌面应用程序甚至传统系统中使用它。
支持高级查询:
该库支持正则表达式和定向提取等高级搜索技术,因此适用于数据挖掘或文档索引等复杂用例。
IronPDF for .NET 通过 NuGet 提供,可以轻松添加到您的 .NET 项目中。 以下是开始工作的方法。
至安装 IronPdf请使用 Visual Studio 中的 NuGet 软件包管理器,或在软件包管理器控制台中运行以下命令:
Install-Package IronPdfInstall-Package IronPdf'INSTANT VB TODO TASK: The following line uses invalid syntax:
'Install-Package IronPdf这将下载并安装库及其依赖项。
安装该库后,您需要通过引用 IronPDF 命名空间将其包含在您的项目中。 在代码文件顶部添加以下一行:
using IronPdf;using IronPdf;Imports IronPdfIronPDF 简化了在 PDF 文档中查找文本的过程。 下面将逐步演示如何实现这一目标。
第一步是加载要处理的 PDF 文件。 如下代码所示,翻译工作将使用 PdfDocument 类完成:
using IronPdf;
PdfDocument pdf = PdfDocument.FromFile("example.pdf");using IronPdf;
PdfDocument pdf = PdfDocument.FromFile("example.pdf");Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("example.pdf")PdfDocument 类在内存中表示 PDF 文件,使您能够执行各种操作,如提取文本或修改内容。 加载 PDF 文件后,我们可以从整个 PDF 文档或文件中的特定 PDF 页面搜索文本。
加载 PDF 后,使用 ExtractAllText()提取整个文档文本内容的方法。 然后,您可以使用标准的字符串操作技术搜索特定术语:
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string path = "example.pdf";
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile(path);
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for a specific term
string searchTerm = "Invoice";
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
Console.WriteLine(isFound
? $"The term '{searchTerm}' was found in the PDF!"
: $"The term '{searchTerm}' was not found.");
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string path = "example.pdf";
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile(path);
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for a specific term
string searchTerm = "Invoice";
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
Console.WriteLine(isFound
? $"The term '{searchTerm}' was found in the PDF!"
: $"The term '{searchTerm}' was not found.");
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim path As String = "example.pdf"
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile(path)
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Search for a specific term
Dim searchTerm As String = "Invoice"
Dim isFound As Boolean = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase)
Console.WriteLine(If(isFound, $"The term '{searchTerm}' was found in the PDF!", $"The term '{searchTerm}' was not found."))
End Sub
End Class输入 PDF
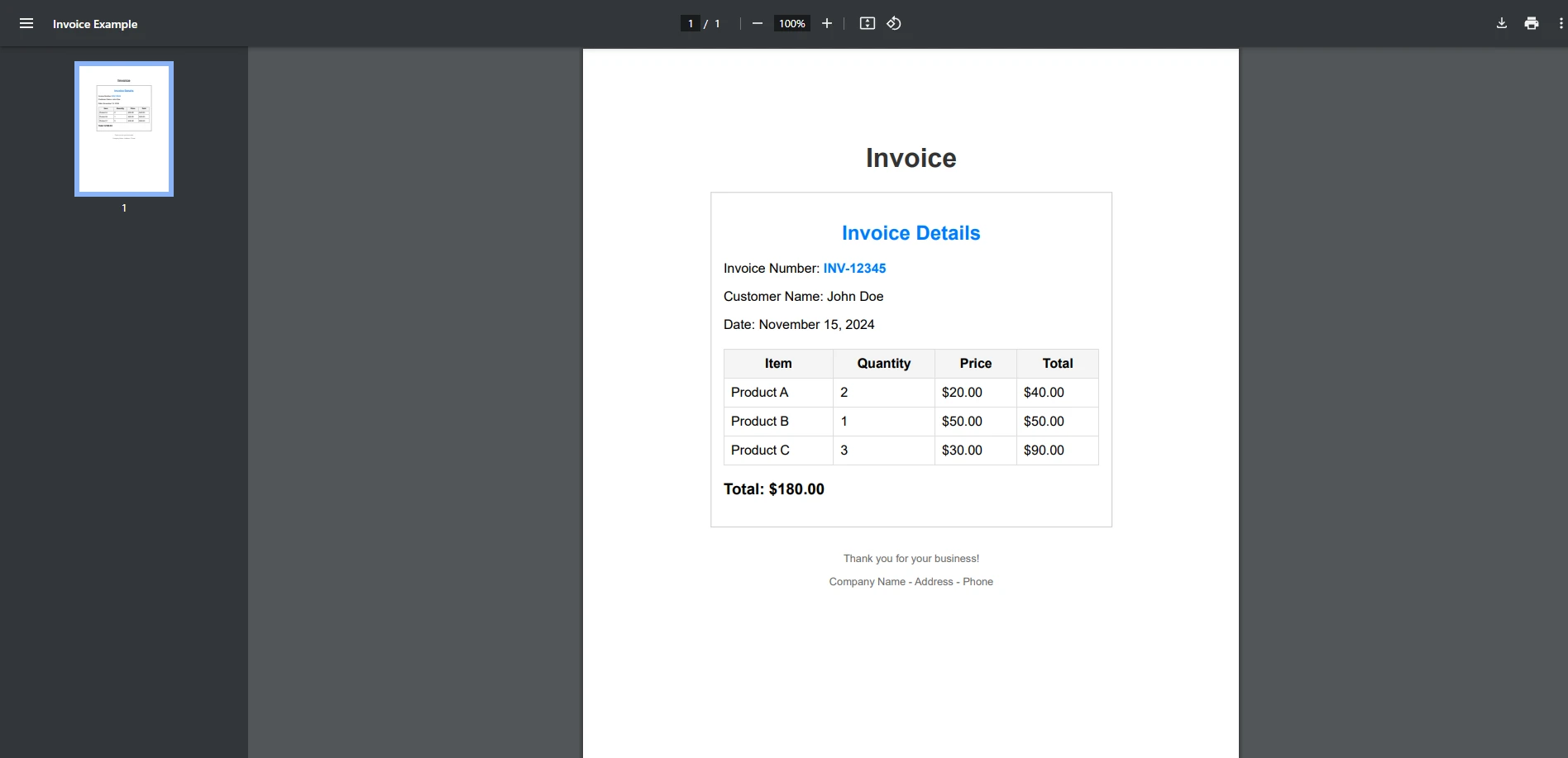
控制台输出
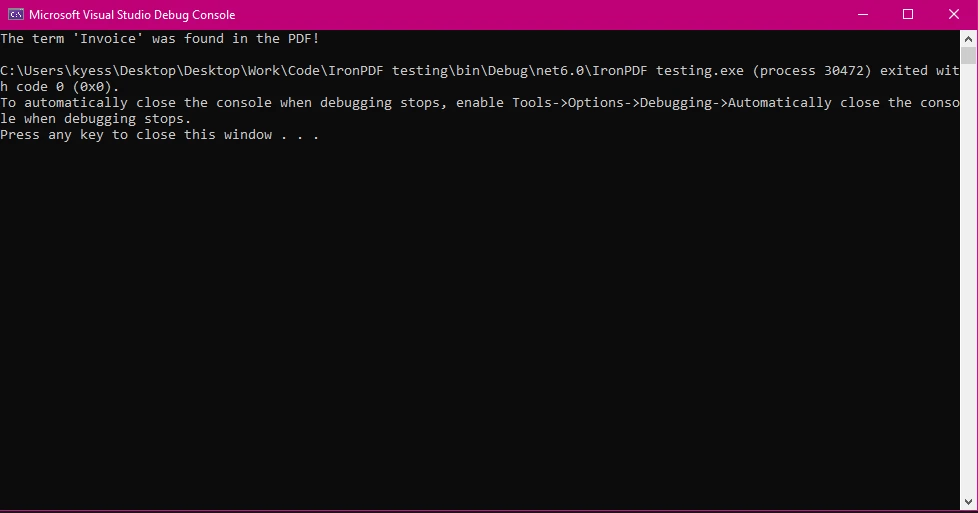
本示例演示了一个简单的情况,即检查 PDF 中是否存在术语。 StringComparison.OrdinalIgnoreCase可确保搜索到的文本不区分大小写。
IronPdf 提供多种高级功能,扩展了文本搜索功能。
正则表达式是在文本中查找模式的强大工具。 例如,您可能希望在 PDF 中找到所有电子邮件地址:
using System.Text.RegularExpressions;
// Extract all text
string pdfText = pdf.ExtractAllText();
// Use a regex to find patterns (e.g., email addresses)
Regex regex = new Regex(@"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}");
MatchCollection matches = regex.Matches(pdfText);
foreach (Match match in matches)
{
Console.WriteLine($"Found match: {match.Value}");
}using System.Text.RegularExpressions;
// Extract all text
string pdfText = pdf.ExtractAllText();
// Use a regex to find patterns (e.g., email addresses)
Regex regex = new Regex(@"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}");
MatchCollection matches = regex.Matches(pdfText);
foreach (Match match in matches)
{
Console.WriteLine($"Found match: {match.Value}");
}Imports System.Text.RegularExpressions
' Extract all text
Private pdfText As String = pdf.ExtractAllText()
' Use a regex to find patterns (e.g., email addresses)
Private regex As New Regex("[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}")
Private matches As MatchCollection = regex.Matches(pdfText)
For Each match As Match In matches
Console.WriteLine($"Found match: {match.Value}")
Next match输入 PDF
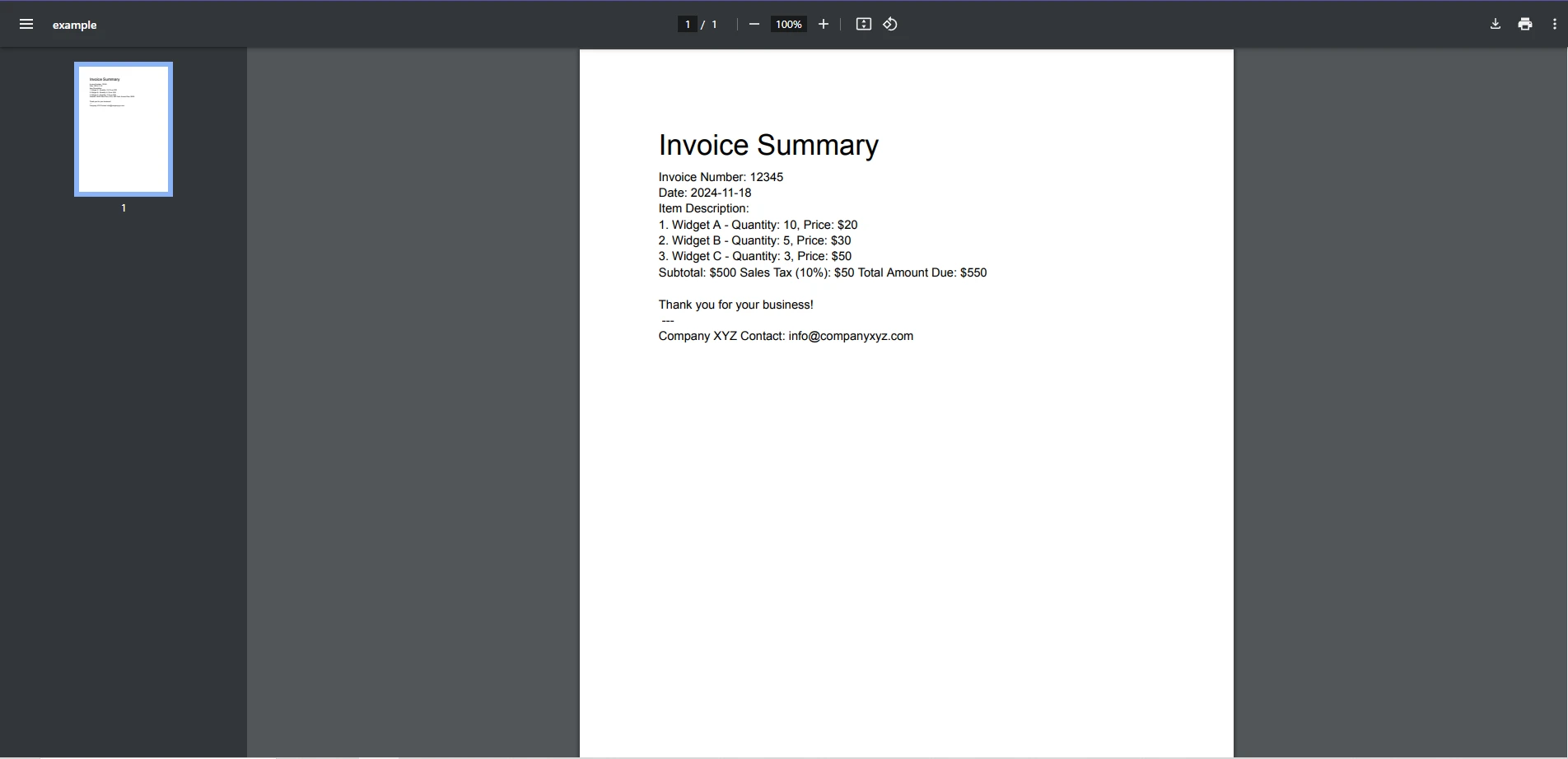
控制台输出
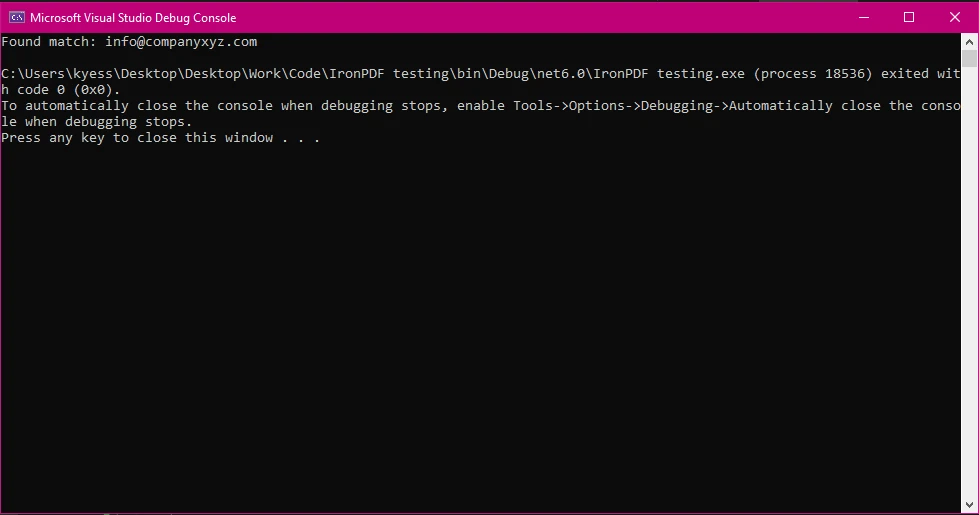
本示例使用 regex 模式识别并打印文档中的所有电子邮件地址。
有时,您可能只需要在 PDF 的特定页面内进行搜索。 IronPDF 允许您使用 PdfDocument.Pages 属性针对单个页面进行翻译:
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("urlPdf.pdf");
var pageText = pdf.Pages[0].Text.ToString(); // Extract text from the first page
if (pageText.Contains("IronPDF"))
{
Console.WriteLine("Found the term 'IronPDF' on the first page!");
}
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("urlPdf.pdf");
var pageText = pdf.Pages[0].Text.ToString(); // Extract text from the first page
if (pageText.Contains("IronPDF"))
{
Console.WriteLine("Found the term 'IronPDF' on the first page!");
}
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile("urlPdf.pdf")
Dim pageText = pdf.Pages(0).Text.ToString() ' Extract text from the first page
If pageText.Contains("IronPDF") Then
Console.WriteLine("Found the term 'IronPDF' on the first page!")
End If
End Sub
End Class输入 PDF
控制台输出
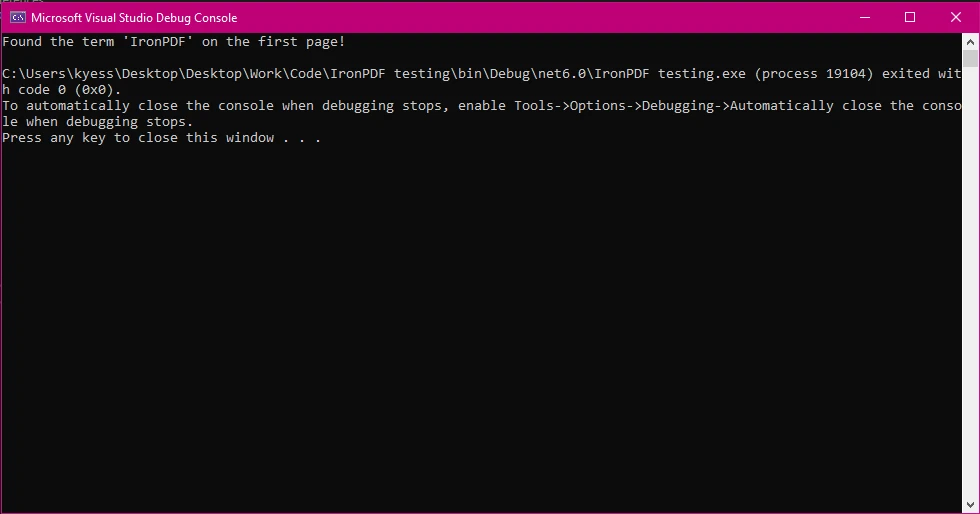
这种方法有助于在处理大型 PDF 时优化性能。
法律专业人士可以使用 IronPdf 自动搜索冗长合同中的关键术语或条款。 例如,在文档中快速定位 "终止条款 "或 "保密性"。
在财务或会计工作流程中,IronPDF 可帮助定位批量 PDF 文件中的发票号码、日期或总金额,从而简化操作并减少人工工作量。
IronPdf 可集成到数据管道中,以提取和分析以 PDF 格式存储的报告或日志中的信息。 这对于处理大量非结构化数据的行业尤其有用。
IronPDFAdobe Acrobat 不仅仅是一个处理 PDF 的库; 它是一个完整的工具包,使 .NET 开发人员能够轻松处理复杂的 PDF 操作。 从提取文本、查找特定术语到使用正则表达式执行高级模式匹配,IronPDF 简化了原本可能需要大量手工劳动或使用多个库才能完成的任务。
在 PDF 中提取和搜索文本的能力为各行各业带来了强大的用例。 法律专业人士可以自动搜索合同中的关键条款,会计师可以简化发票处理,任何领域的开发人员都可以创建高效的文档工作流。 通过提供精确的文本提取、与 .NET Core 和 Framework 的兼容性以及先进的功能,IronPDF 可确保毫无麻烦地满足您的 PDF 需求。
不要让 PDF 处理拖慢您的开发进度。 立即开始使用 IronPDF,简化文本提取,提高工作效率。 以下是开始工作的方法:
无需信用卡
您的试用密钥应该在邮件中。![]() 试用表格已
试用表格已
成功提交。
如果没有,请联系
support@ironsoftware.com
免费开始
无需信用卡
在生产环境中测试,无水印。
随时随地满足您的需求。
获得30天的全功能产品。
几分钟内就能启动并运行。
在您的产品试用期间,全面访问我们的支持工程团队。





预约30分钟的个人演示。
无需合同,无需卡片信息,无需承诺。

