
在实际环境中测试
在生产环境中测试,无水印。
随时随地满足您的需求。
C# PDF库
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


Parallel.ForEach是C#中的一种方法,允许您对集合或数据源执行并行迭代。 并行循环使得可以同时执行任务,而不是顺序处理集合中的每个项目,这可以通过减少整体执行时间显著提高性能。并行处理通过将工作分配到多个核心处理器上来实现,使得任务可以同时运行。 这在处理相互独立的任务时特别有用。
与通常按顺序处理项目的foreach循环相比,并行方法可以通过利用多个线程并行处理大数据集,从而更快地处理大量数据。
IronPDF是一个强大的.NET PDF处理库,能够将 HTML 转换为 PDF, 从 PDF 中提取文本, 合并和拆分文档,以及更多。 在处理大量PDF任务时,使用Parallel.ForEach进行并行处理可以显著减少执行时间。无论是生成数百个PDF还是同时从多个文件提取数据,利用IronPDF的数据并行性可以确保任务更快、更高效地完成。
本指南面向希望使用IronPDF和Parallel.ForEach优化PDF处理任务的.NET开发人员。 建议具备C#的基础知识,并熟悉IronPDF库。 在本指南结束时,您将能够实现并行处理,以同时处理多个PDF任务,从而提高性能和可扩展性。
使用IronPDF在你的项目中,你需要通过NuGet安装该库。
要安装IronPDF,请按照以下步骤操作:
在 Visual Studio 中打开项目。
进入 工具 → NuGet 包管理器 → 为解决方案管理 NuGet 包。
或者,您可以通过 NuGet 包管理器控制台安装它:
Install-Package IronPdfInstall-Package IronPdf'INSTANT VB TODO TASK: The following line uses invalid syntax:
'Install-Package IronPdf一旦安装了IronPDF,您就可以开始使用它进行PDF生成和操作任务。
Parallel.ForEach 是 System.Threading.Tasks 命名空间的一部分,提供了一种简单有效的方法来并发执行迭代。 Parallel.ForEach 的语法如下:
Parallel.ForEach(collection, item =>
{
// Code to process each item
});Parallel.ForEach(collection, item =>
{
// Code to process each item
});Parallel.ForEach(collection, Sub(item)
' Code to process each item
End Sub)集合中的每个项目都会并行处理,系统决定如何在可用线程间分配工作负载。 您还可以通过指定选项来控制并行度,例如使用的最大线程数。
相比之下,传统的foreach循环逐个处理每个项目,而并行循环可以同时处理多个项目,在处理大型集合时能提高性能。
首先,确保按照“入门”部分所述安装了IronPDF。 然后,您可以开始编写并行 PDF 处理逻辑。
string[] htmlPages = { "page1.html", "page2.html", "page3.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
});string[] htmlPages = { "page1.html", "page2.html", "page3.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
});Dim htmlPages() As String = { "page1.html", "page2.html", "page3.html" }
Parallel.ForEach(htmlFiles, Sub(htmlFile)
' Load the HTML content into IronPDF and convert it to PDF
Dim renederer As New ChromePdfRenderer()
Dim pdf As PdfDocument = renederer.RenderHtmlAsPdf(htmlFile)
' Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf")
End Sub)此代码演示了如何并行将多个HTML页面转换为PDF。
在处理并行任务时,错误处理至关重要。 在Parallel.ForEach循环中使用try-catch块来管理任何异常。
Parallel.ForEach(pdfFiles, pdfFile =>
{
try
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractAllText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {pdfFile}: {ex.Message}");
}
});Parallel.ForEach(pdfFiles, pdfFile =>
{
try
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractAllText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {pdfFile}: {ex.Message}");
}
});Parallel.ForEach(pdfFiles, Sub(pdfFile)
Try
Dim pdf = IronPdf.PdfDocument.FromFile(pdfFile)
Dim text As String = pdf.ExtractAllText()
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text)
Catch ex As Exception
Console.WriteLine($"Error processing {pdfFile}: {ex.Message}")
End Try
End Sub)并行处理的另一个用例是从一批PDF中提取文本。 处理多个PDF文件时,同时执行文本提取可以节省大量时间。以下示例演示了如何实现这一点。
using IronPdf;
using System.Linq;
using System.Threading.Tasks;
class Program
{
static void Main(string[] args)
{
string[] pdfFiles = { "doc1.pdf", "doc2.pdf", "doc3.pdf" };
Parallel.ForEach(pdfFiles, pdfFile =>
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
});
}
}using IronPdf;
using System.Linq;
using System.Threading.Tasks;
class Program
{
static void Main(string[] args)
{
string[] pdfFiles = { "doc1.pdf", "doc2.pdf", "doc3.pdf" };
Parallel.ForEach(pdfFiles, pdfFile =>
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
});
}
}Imports IronPdf
Imports System.Linq
Imports System.Threading.Tasks
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim pdfFiles() As String = { "doc1.pdf", "doc2.pdf", "doc3.pdf" }
Parallel.ForEach(pdfFiles, Sub(pdfFile)
Dim pdf = IronPdf.PdfDocument.FromFile(pdfFile)
Dim text As String = pdf.ExtractText()
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text)
End Sub)
End Sub
End Class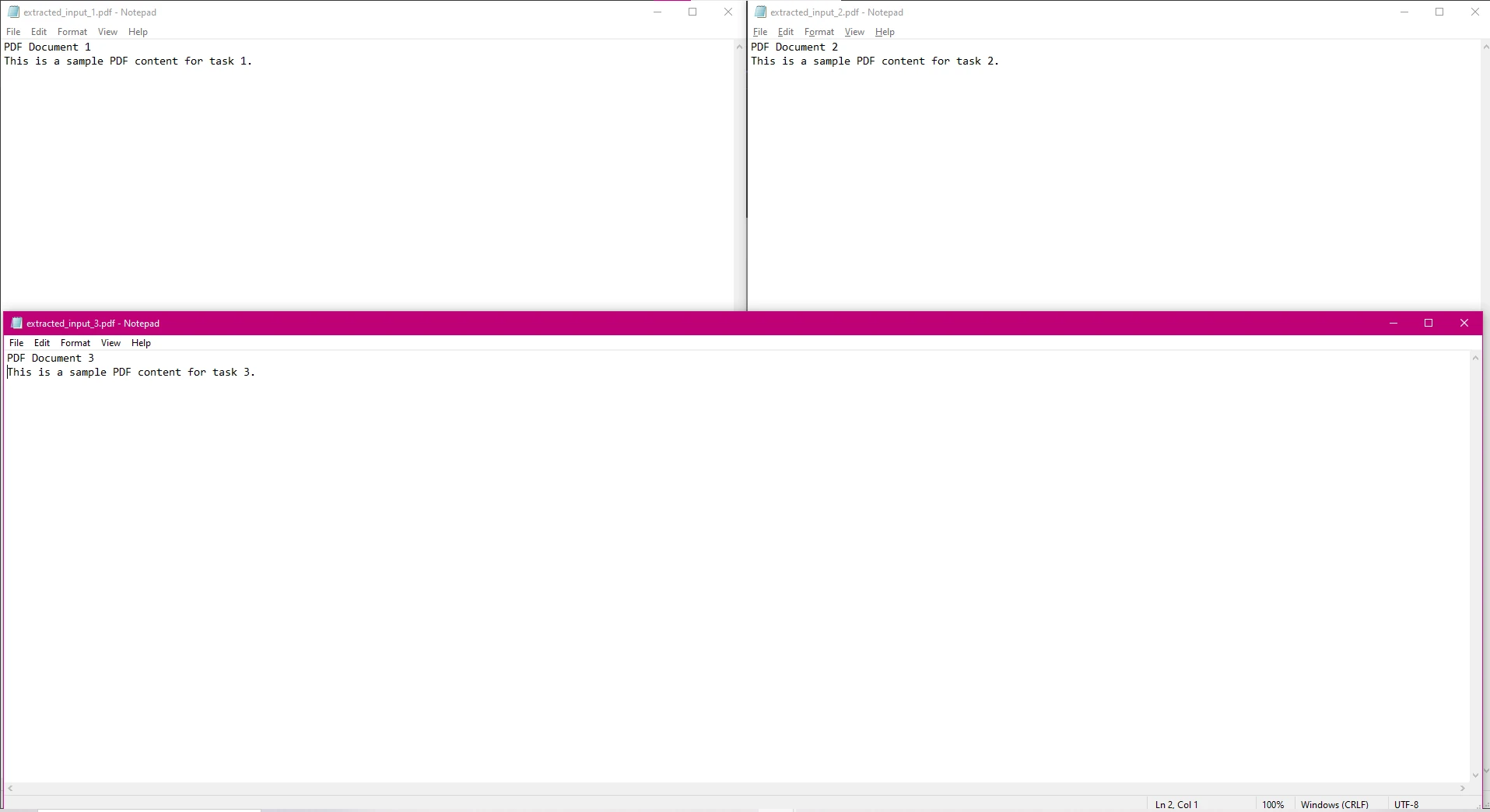
在此代码中,每个PDF文件被并行处理以提取文本,提取的文本被保存在单独的文本文件中。
在此示例中,我们将并行从多个HTML文件列表中生成多个PDF,这可能是当您需要将多个动态HTML页面转换为PDF文档时的典型情况。
using IronPdf;
string[] htmlFiles = { "example.html", "example_1.html", "example_2.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
try
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlFileAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
Console.WriteLine($"PDF created for {htmlFile}");
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {htmlFile}: {ex.Message}");
}
});using IronPdf;
string[] htmlFiles = { "example.html", "example_1.html", "example_2.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
try
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlFileAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
Console.WriteLine($"PDF created for {htmlFile}");
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {htmlFile}: {ex.Message}");
}
});Imports IronPdf
Private htmlFiles() As String = { "example.html", "example_1.html", "example_2.html" }
Parallel.ForEach(htmlFiles, Sub(htmlFile)
Try
' Load the HTML content into IronPDF and convert it to PDF
Dim renederer As New ChromePdfRenderer()
Dim pdf As PdfDocument = renederer.RenderHtmlFileAsPdf(htmlFile)
' Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf")
Console.WriteLine($"PDF created for {htmlFile}")
Catch ex As Exception
Console.WriteLine($"Error processing {htmlFile}: {ex.Message}")
End Try
End Sub)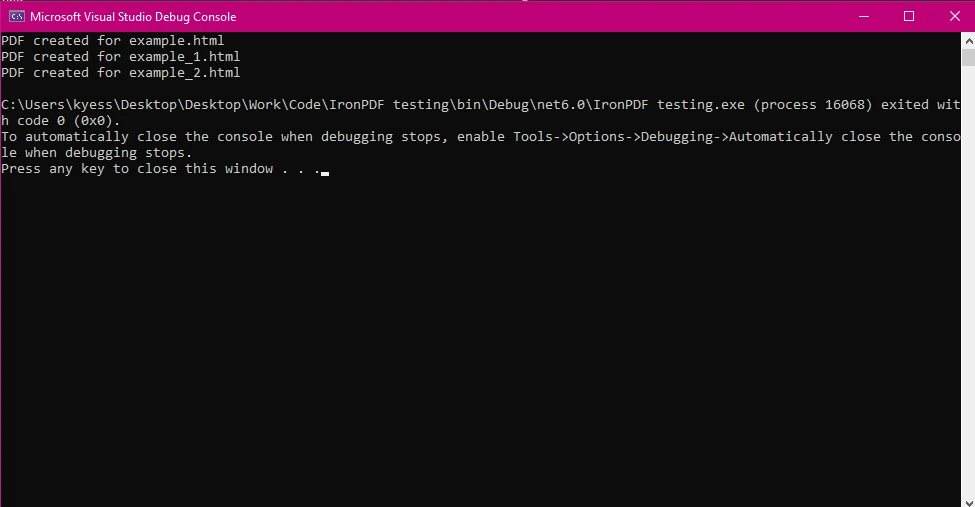
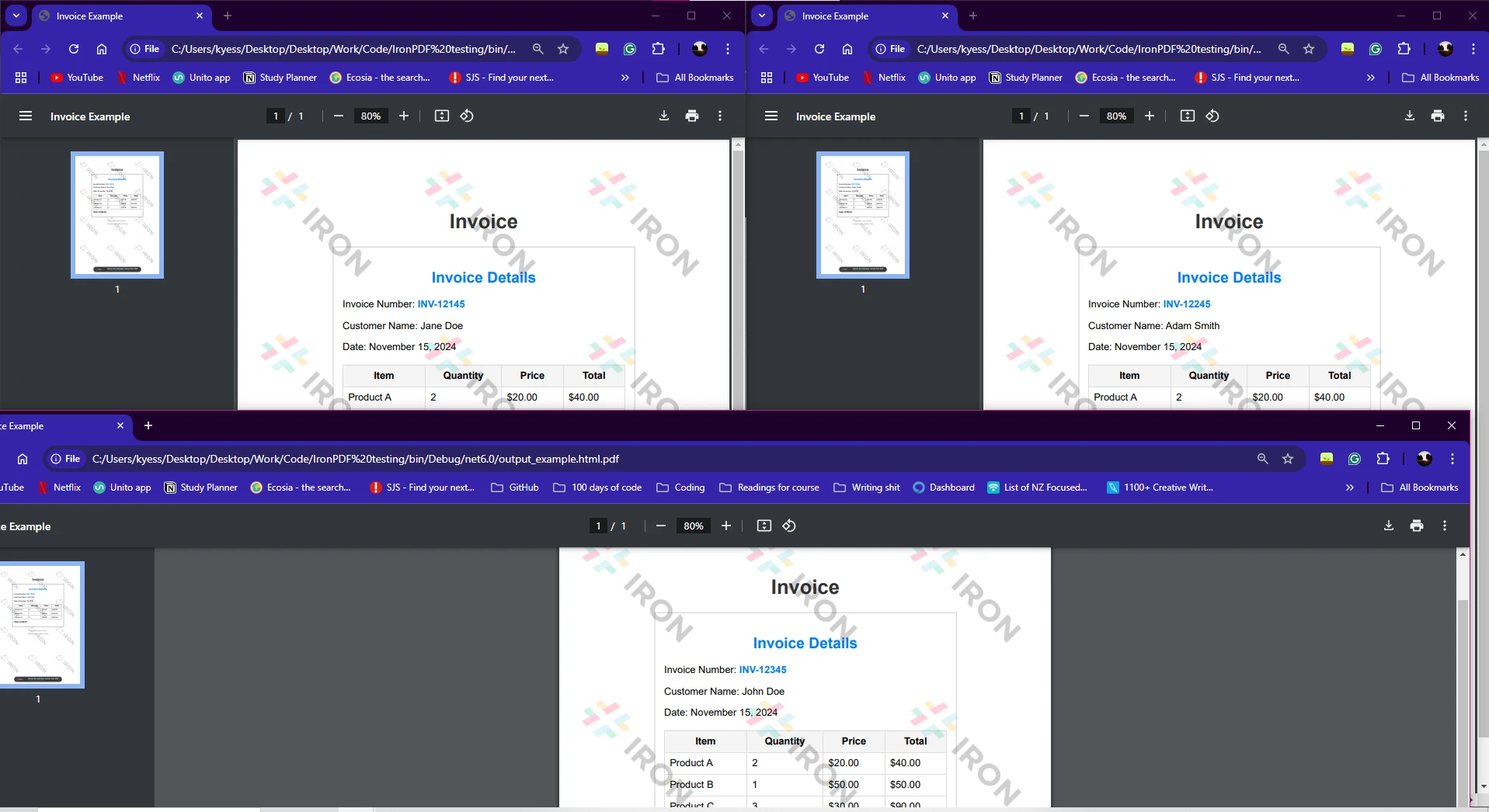
HTML 文件: 数组 htmlFiles 包含多个您希望转换为 PDF 的 HTML 文件的路径。
Parallel.ForEach(htmlFiles, htmlFile =>{...}) 并发处理每个 HTML 文件,这在处理多个文件时加快了操作速度。
保存 PDF: 生成 PDF 后,使用 pdf.SaveAs 方法保存文件,并将输出文件名附加上原始 HTML 文件的名称。
IronPDF 在大多数操作中是线程安全的。 但是,像并行写入同一文件这样的操作可能会导致问题。 始终确保每个并行任务在单独的输出文件或资源上运行。
为了优化性能,请考虑控制并行度。 对于大型数据集,您可能需要限制并发线程的数量以防止系统过载。
var options = new ExecutionDataflowBlockOptions
{
MaxDegreeOfParallelism = 4
};var options = new ExecutionDataflowBlockOptions
{
MaxDegreeOfParallelism = 4
};Dim options = New ExecutionDataflowBlockOptions With {.MaxDegreeOfParallelism = 4}处理大量PDF时,要注意内存使用。 尽量在不再需要时立即释放像 PdfDocument 这样的资源。
扩展方法是一种特殊的静态方法,允许您在不修改源代码的情况下向现有类型添加新功能。 当使用像IronPDF这样的库时,这可能会很有用,你可能想要添加自定义处理方法或扩展其功能,以便在并行处理场景中更加方便地处理PDF。
通过使用扩展方法,您可以创建简洁、可重用的代码,从而简化并行循环中的逻辑。 这种方法不仅减少了重复,还帮助您维持一个干净的代码库,特别是在处理复杂的PDF工作流程和数据并行时。
使用并行循环,比如Parallel.ForEach与IronPDF在处理大量PDF时提供显著的性能提升。 无论您是将HTML转换为PDF、提取文本还是操作文档,数据并行性通过并发运行任务来实现更快的执行。 并行方法确保操作可以在多个核心处理器上执行,从而减少总执行时间并提高批处理任务的性能。
虽然并行处理加快了任务速度,但要注意线程安全和资源管理。 IronPDF在大多数操作中是线程安全的,但在访问共享资源时处理潜在冲突非常重要。 考虑错误处理和内存管理以确保稳定性,特别是在您的应用程序扩展时。
如果您准备深入了解IronPDF并探索高级功能,官方文件,允许您在购买前在自己的项目中测试该库。
无需信用卡
您的试用密钥应该在邮件中。![]() 试用表格已
试用表格已
成功提交。
如果没有,请联系
support@ironsoftware.com
免费开始
无需信用卡
在生产环境中测试,无水印。
随时随地满足您的需求。
获得30天的全功能产品。
几分钟内就能启动并运行。
在您的产品试用期间,全面访问我们的支持工程团队。





预约30分钟的个人演示。
无需合同,无需卡片信息,无需承诺。

