
在实际环境中测试
在生产环境中测试,无水印。
随时随地满足您的需求。
C# PDF库
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


PDF(便携式文档格式)是一种广泛使用的文件格式,用于一致且安全地共享文档。 在文件管理系统、报告工具等各种应用程序中,用 C# 阅读和操作此类文件是一项常见要求。 在本文中,我们将比较两个流行的用于在C#中读取PDF文件的库:IronPDF和iTextSharp(最新的.NET库iText)。
IronPDF 是来自 Iron Software 的一个全面的 C# 库,提供了多种功能来处理 PDF 文件。 它允许开发人员无缝创建、编辑和处理 PDF 文档。 IronPDF 以简单易用著称,是需要将 PDF 功能快速集成到应用程序中的开发人员的绝佳选择。
iTextSharp 是另一个用于处理C#中PDF文件的流行库。 它已经存在了相当长的一段时间,并在业内广泛使用。 iText 为创建和处理 PDF 文档提供了丰富的功能。 它以灵活性和可扩展性著称,适用于复杂的 PDF 相关任务。
在 Visual Studio 中创建一个新的 C# 项目,比较 IronPDF 与 iTextSharp 在阅读 PDF 文件方面的优劣。
为项目安装 IronPDF 和 iTextSharp 库。
使用 IronPDF 阅读 PDF 文件。
Visual Studio:确保您已安装Visual Studio或其他C#开发环境。
首先设置一个 C# 控制台应用程序。 打开 Visual Studio 并选择创建新项目。 选择控制台应用程序类型。
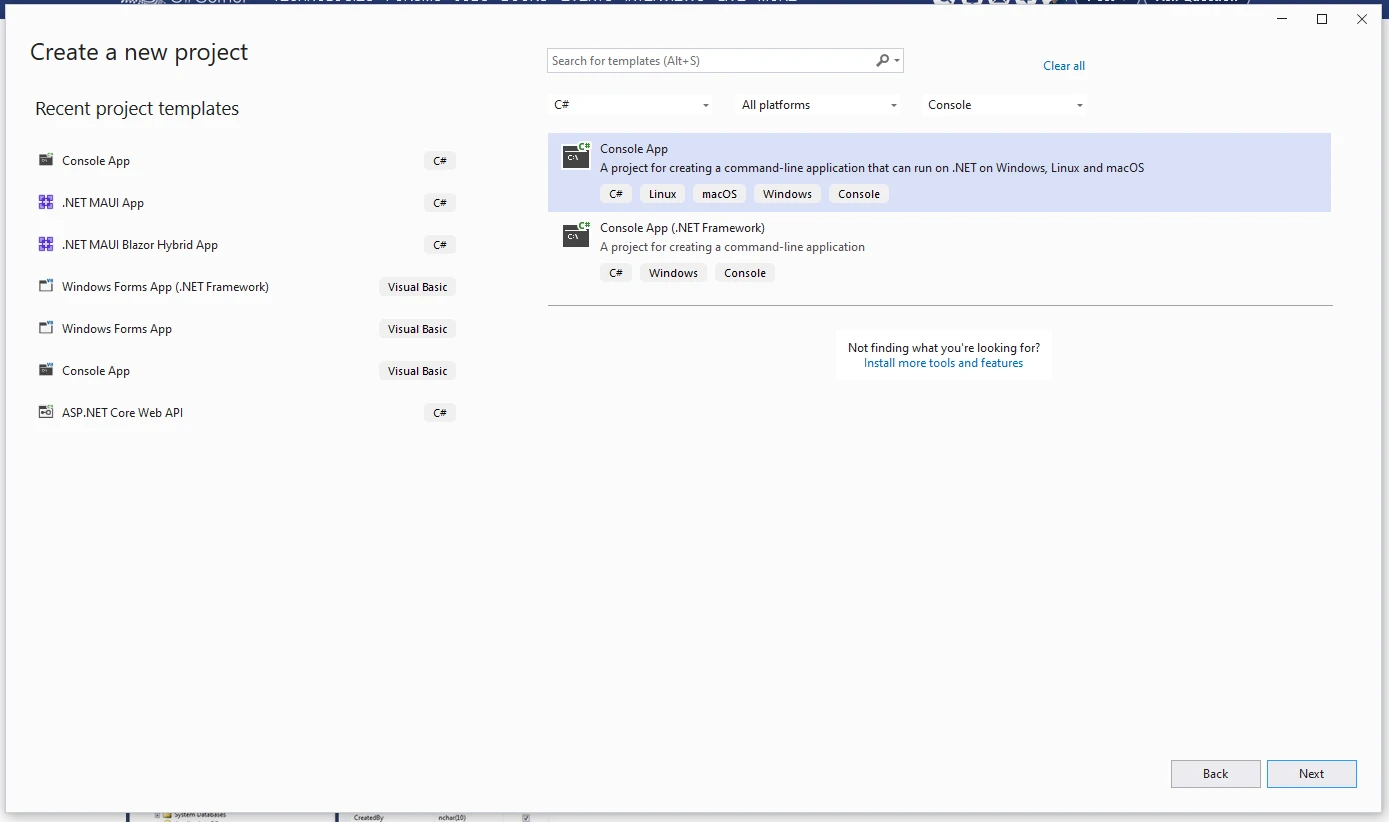
提供如下所示的项目名称。
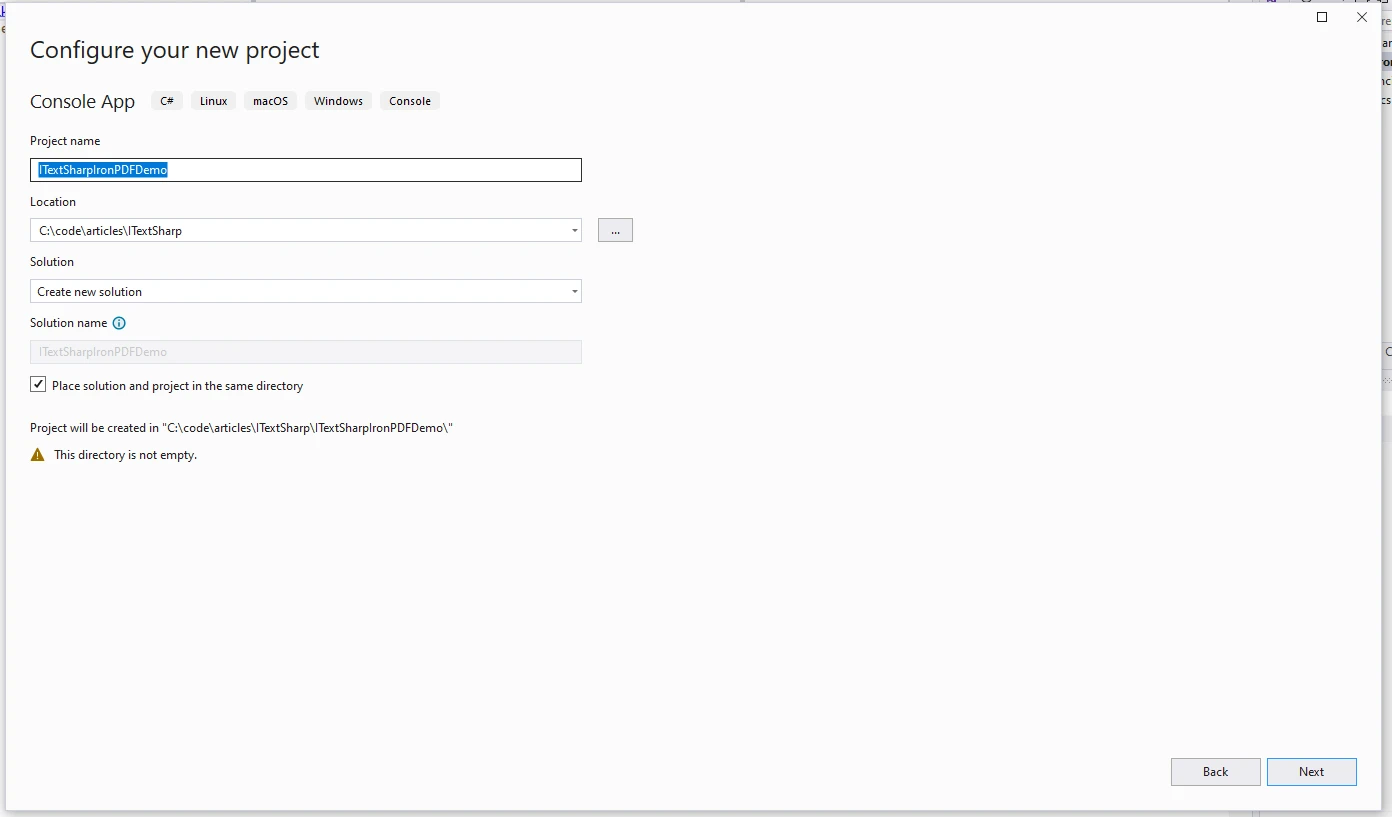
选择项目所需的 .NET 版本。
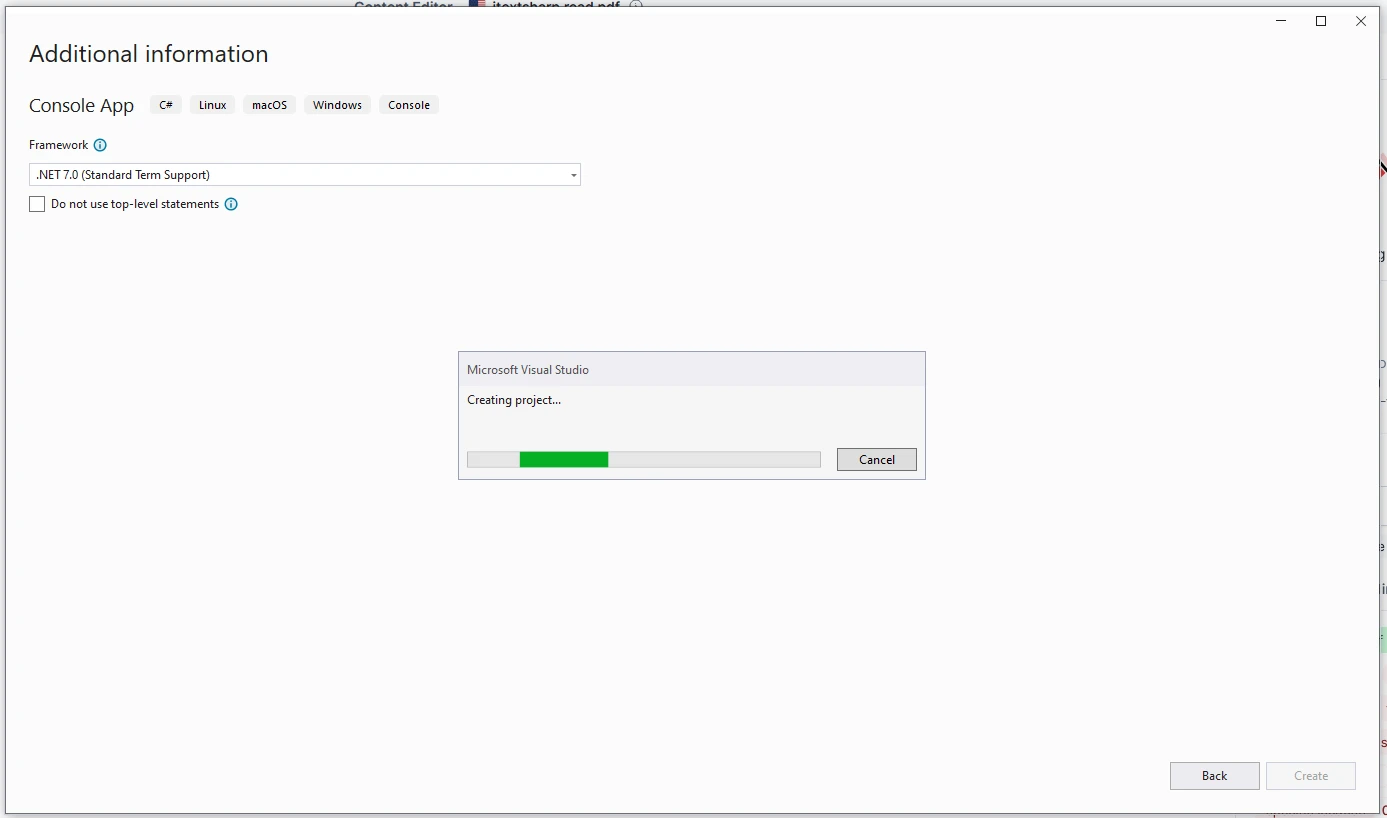
完成后,Visual Studio 将生成一个新项目。
iTextSharp 可以通过iText 的 NuGet 包管理器安装。 最新版本作为 iText 软件包提供。
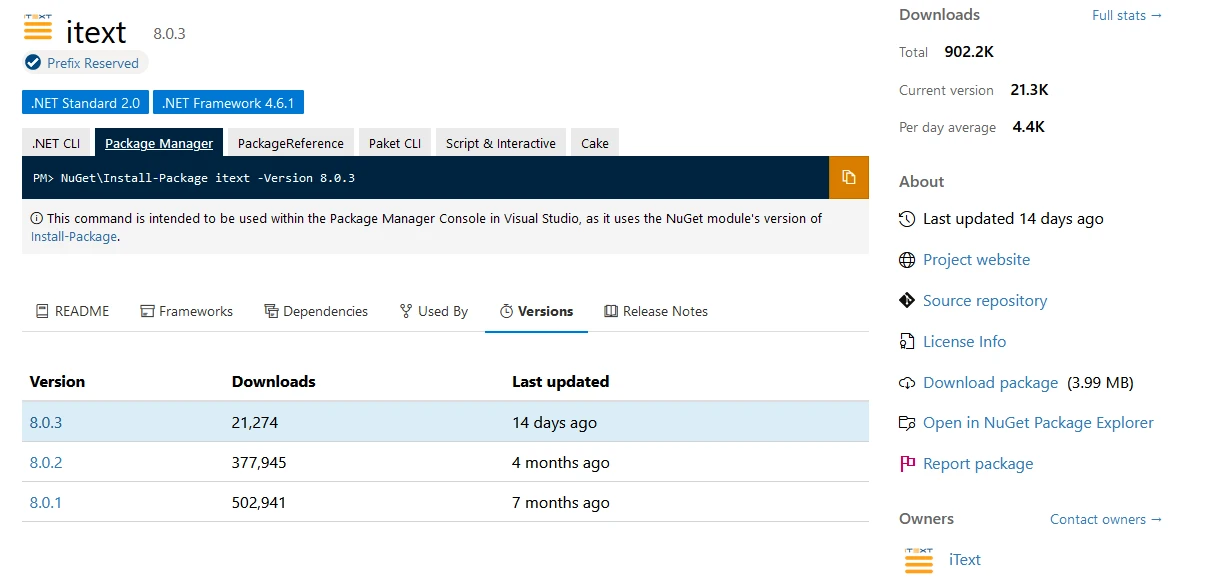
或从 Visual Studio 软件包管理器,如下图所示。 在软件包管理器中搜索 iText,然后单击安装。

IronPDF 可以从 NuGet 包管理器 安装,如下所示。
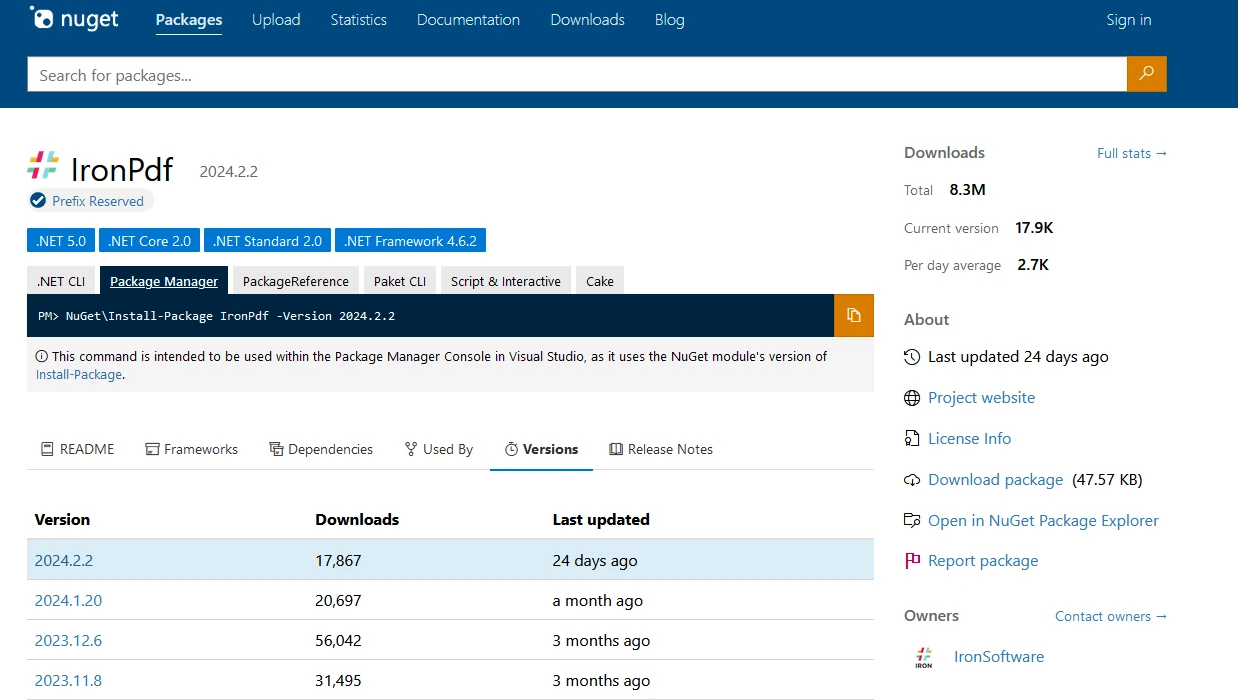
或者从 Visual Studio 软件包管理器中安装,如下图所示。 在包管理器中搜索IronPDF: C# PDF Library并点击安装。

在 program.cs 文件中添加以下代码,并提供包含以下内容的 PDF 文档示例。

using IronPdf;
Console.WriteLine("Comparison of IronPDF And iTextSharp Read PDF Files in C#");
// pdfreader reader
ReadUsingIronPDF.Read();
public class ReadUsingIronPDF
{
public static void Read()
{
// read from specific location
string filename = "C:\\code\\articles\\ITextSharp\\ITextSharpIronPdfDemo\\Example.pdf";
var pdfReader = PdfDocument.FromFile(filename);
// Get all text to put in a search index using new simpletextextractionstrategy
var allText = pdfReader.ExtractAllText();
Console.WriteLine("------------------Text From PDF-----------------");
Console.WriteLine(allText);
Console.WriteLine("------------------Text From PDF-----------------");
var allIMages = pdfReader.ExtractAllImages();
Console.WriteLine("------------------Image Count From PDF-----------------");
Console.WriteLine($"Total Images={allIMages.Count()}");
Console.WriteLine("------------------Image Count From PDF-----------------");
Console.WriteLine("------------------one Page Text From PDF page-----------------");
var pageCount = pdfReader.PageCount;
for (int page = 0; page < pageCount; page++)
{
string Text = pdfReader.ExtractTextFromPage(page);
Console.WriteLine(Text);
}
}
}using IronPdf;
Console.WriteLine("Comparison of IronPDF And iTextSharp Read PDF Files in C#");
// pdfreader reader
ReadUsingIronPDF.Read();
public class ReadUsingIronPDF
{
public static void Read()
{
// read from specific location
string filename = "C:\\code\\articles\\ITextSharp\\ITextSharpIronPdfDemo\\Example.pdf";
var pdfReader = PdfDocument.FromFile(filename);
// Get all text to put in a search index using new simpletextextractionstrategy
var allText = pdfReader.ExtractAllText();
Console.WriteLine("------------------Text From PDF-----------------");
Console.WriteLine(allText);
Console.WriteLine("------------------Text From PDF-----------------");
var allIMages = pdfReader.ExtractAllImages();
Console.WriteLine("------------------Image Count From PDF-----------------");
Console.WriteLine($"Total Images={allIMages.Count()}");
Console.WriteLine("------------------Image Count From PDF-----------------");
Console.WriteLine("------------------one Page Text From PDF page-----------------");
var pageCount = pdfReader.PageCount;
for (int page = 0; page < pageCount; page++)
{
string Text = pdfReader.ExtractTextFromPage(page);
Console.WriteLine(Text);
}
}
}Imports IronPdf
Console.WriteLine("Comparison of IronPDF And iTextSharp Read PDF Files in C#")
' pdfreader reader
ReadUsingIronPDF.Read()
'INSTANT VB TODO TASK: Local functions are not converted by Instant VB:
'public class ReadUsingIronPDF
'{
' public static void Read()
' {
' ' read from specific location
' string filename = "C:\code\articles\ITextSharp\ITextSharpIronPdfDemo\Example.pdf";
' var pdfReader = PdfDocument.FromFile(filename);
' ' Get all text to put in a search index using new simpletextextractionstrategy
' var allText = pdfReader.ExtractAllText();
' Console.WriteLine("------------------Text From PDF-----------------");
' Console.WriteLine(allText);
' Console.WriteLine("------------------Text From PDF-----------------");
' var allIMages = pdfReader.ExtractAllImages();
' Console.WriteLine("------------------Image Count From PDF-----------------");
' Console.WriteLine(string.Format("Total Images={0}", allIMages.Count()));
' Console.WriteLine("------------------Image Count From PDF-----------------");
' Console.WriteLine("------------------one Page Text From PDF page-----------------");
' var pageCount = pdfReader.PageCount;
' for (int page = 0; page < pageCount; page++)
' {
' string Text = pdfReader.ExtractTextFromPage(page);
' Console.WriteLine(Text);
' }
' }
'}要创建文本 PDF,请创建一个 Word 文档,并在 Word 文档中添加上述文本,然后将其保存为 PDF 文档,命名为 Example.pdf
在代码中,我们从 PDF 文件路径创建一个 PDFReader,并提取所有文本
可使用 ExtractImages 方法提取 PDF 中的图像
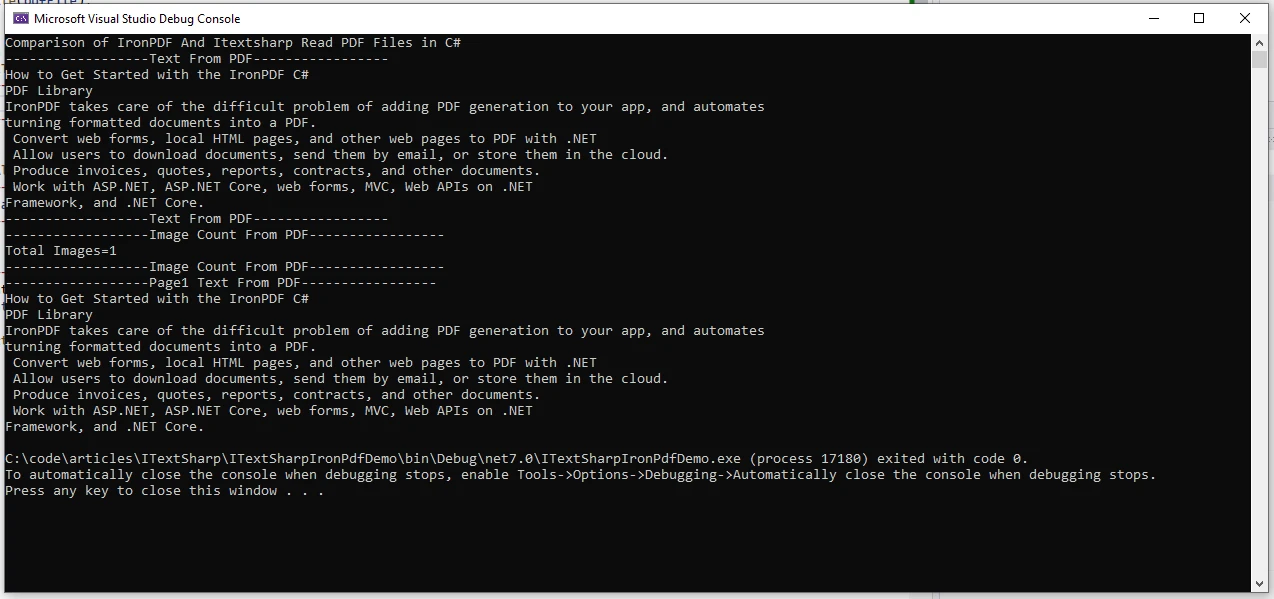
现在,要比较从 iTextSharp 读取的文本,请在同一 program.cs 文件中添加以下代码。为简单起见,我们没有将类分在不同的文件中。
using IronPdf;
using iText.Kernel.Pdf;
using iText.Kernel.Pdf.Canvas.Parser.Listener;
using iText.Kernel.Pdf.Canvas.Parser;
Console.WriteLine("Comparison of IronPDF And iTextSharp Read PDF Files in C#");
//ReadUsingIronPDF.Read();
ReadUsingITextSharp.Read();
public class ReadUsingITextSharp
{
public static void Read()
{
string pdfFile = "C:\\code\\articles\\ITextSharp\\ITextSharpIronPdfDemo\\Example.pdf";
// Create a PDF reader
PdfReader pdfReader = new PdfReader(pdfFile);
iText.Kernel.Pdf.PdfDocument pdfDocument = new iText.Kernel.Pdf.PdfDocument(pdfReader);
// Extract plain text from the PDF
LocationTextExtractionStrategy strategy = new LocationTextExtractionStrategy();
string pdfText = PdfTextExtractor.GetTextFromPage(pdfDocument.GetPage(1), strategy);
// Display or manipulate the extracted text as needed
Console.WriteLine(pdfText);
}
}using IronPdf;
using iText.Kernel.Pdf;
using iText.Kernel.Pdf.Canvas.Parser.Listener;
using iText.Kernel.Pdf.Canvas.Parser;
Console.WriteLine("Comparison of IronPDF And iTextSharp Read PDF Files in C#");
//ReadUsingIronPDF.Read();
ReadUsingITextSharp.Read();
public class ReadUsingITextSharp
{
public static void Read()
{
string pdfFile = "C:\\code\\articles\\ITextSharp\\ITextSharpIronPdfDemo\\Example.pdf";
// Create a PDF reader
PdfReader pdfReader = new PdfReader(pdfFile);
iText.Kernel.Pdf.PdfDocument pdfDocument = new iText.Kernel.Pdf.PdfDocument(pdfReader);
// Extract plain text from the PDF
LocationTextExtractionStrategy strategy = new LocationTextExtractionStrategy();
string pdfText = PdfTextExtractor.GetTextFromPage(pdfDocument.GetPage(1), strategy);
// Display or manipulate the extracted text as needed
Console.WriteLine(pdfText);
}
}Imports IronPdf
Imports iText.Kernel.Pdf
Imports iText.Kernel.Pdf.Canvas.Parser.Listener
Imports iText.Kernel.Pdf.Canvas.Parser
Console.WriteLine("Comparison of IronPDF And iTextSharp Read PDF Files in C#")
'ReadUsingIronPDF.Read();
ReadUsingITextSharp.Read()
'INSTANT VB TODO TASK: Local functions are not converted by Instant VB:
'public class ReadUsingITextSharp
'{
' public static void Read()
' {
' string pdfFile = "C:\code\articles\ITextSharp\ITextSharpIronPdfDemo\Example.pdf";
' ' Create a PDF reader
' PdfReader pdfReader = New PdfReader(pdfFile);
' iText.Kernel.Pdf.PdfDocument pdfDocument = New iText.Kernel.Pdf.PdfDocument(pdfReader);
' ' Extract plain text from the PDF
' LocationTextExtractionStrategy strategy = New LocationTextExtractionStrategy();
' string pdfText = PdfTextExtractor.GetTextFromPage(pdfDocument.GetPage(1), strategy);
' ' Display or manipulate the extracted text as needed
' Console.WriteLine(pdfText);
' }
'}
学习曲线:iTextSharp的学习曲线更陡峭,尤其是对于初学者而言。
易用性:IronPDF以其直观的API而闻名,使开发人员能够轻松入门。
将您的 IronPDF license key 插入到 appsettings.json 文件中。
"IronPdf.LicenseKey": "your license key"要获得试用许可证,请提供您的电子邮件。
在IronPDF和iTextSharp之间进行选择取决于您项目的具体需求。 如果您需要一个简单易用的库来进行常见的 PDF 操作,IronPDF 可能是更好的选择。在做出决定时,请考虑应用程序的复杂性、预算和学习曲线等因素。
IronPDF 旨在将 PDF 生成无缝集成到您的应用程序中,毫不费力地处理格式化文档到 PDF 的转换。 这款多功能工具可让您使用 .NET 将网络表单、本地 HTML 网页和其他网络内容转换为 PDF。 用户可以方便地下载、通过电子邮件发送或在云端存储文件。 无论您需要制作发票、报价单、报告、合同或其他专业文档,IronPDF 的 PDF 生成功能都能满足您的需求。 利用 IronPDF 直观高效的 PDF 生成功能提升您的应用程序。
无需信用卡
您的试用密钥应该在邮件中。![]() 试用表格已
试用表格已
成功提交。
如果没有,请联系
support@ironsoftware.com
免费开始
无需信用卡
在生产环境中测试,无水印。
随时随地满足您的需求。
获得30天的全功能产品。
几分钟内就能启动并运行。
在您的产品试用期间,全面访问我们的支持工程团队。





预约30分钟的个人演示。
无需合同,无需卡片信息,无需承诺。

