
在实际环境中测试
在生产环境中测试,无水印。
随时随地满足您的需求。
C# PDF库
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


在数字文档管理的动态环境中,从 PDF 文件中毫不费力地提取数据的能力是支撑众多应用的基础任务。 提取文本的过程对于综合数据分析、内容索引、商业用途和文本处理等目的至关重要。 在一系列可用的工具中,iTextSharp 是一个备受推崇的 C# 库,它是从 PDF 文件中提取文本的出色解决方案。
在这篇内容全面的文章中,我们将深入探讨使用 iTextSharp 的丰富功能,探索这个功能强大、用途广泛的解析器库如何赋予开发人员使用 C# 编程语言从 PDF 文档中高效提取文本内容的能力。 我们将介绍基本方法、示例技术和最佳实践,让开发人员掌握有效利用 iTextSharp 进行文本提取所需的知识。 我们还将在本篇文章中讨论和比较最好、最强大的 PDF 库 IronPDF。
下载用于从 PDF 中提取文本的 C# 库。
通过实例化PdfReader对象来加载现有PDF。
使用GetTextFromPage方法从PdfDocument对象中提取文本。
实例化foreach循环以迭代遍历这些行。
WriteLine方法将行写入文件。IronPDF 概述,在 .NET 开发领域中是一款功能丰富且杰出的库,彻底改变了 PDF 的生成和操作。 IronPDF 为开发人员提供了一套全面的工具,可与 C# 应用程序无缝集成,轻松创建、修改和渲染 PDF 文档。 凭借其直观的应用程序接口和强大的功能,这个多功能库为从 HTML、图像和内容生成高质量 PDF 提供了无限可能。 在本文中,我们将探讨IronPDF的功能,深入研究其关键特性,并展示如何利用它在C#中高效地处理与PDF相关的任务。
iTextSharp 是使用 C# 进行 PDF 操作领域著名的强大库,它彻底改变了开发人员处理 PDF 文档的方式。 它是一款多功能、功能强大的工具,便于创建、修改和提取 PDF 文件中的内容。 iTextSharp 使开发人员能够生成复杂的 PDF、提取图像、处理现有文档和提取数据,使其成为广泛应用的首选解决方案。 在本文中,我们将深入探讨 iTextSharp 的功能和特性,探索如何在 C# 编程环境中有效利用 iTextSharp 管理和处理 PDF。
安装 IronPDF 是一个简单明了的过程,以下是在 C# 项目中安装和集成 IronPDF 的步骤。
打开 Visual Studio,创建一个新项目或打开一个现有项目。
转到 "工具",从下拉菜单中选择 "NuGet 包管理器"。
在新的侧菜单中,选择解决方案的 NuGet 包管理器。
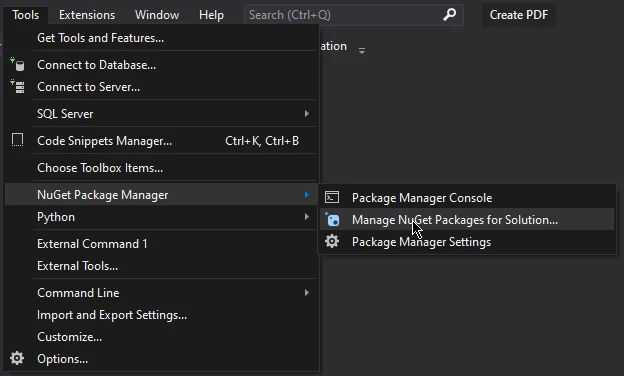
在 "NuGet 包管理器 "窗口中,选择 "浏览 "选项卡。
在搜索栏中输入 "IronPDF",然后按 Enter 键。
IronPDF 实例列表将出现,选择最新版本并按安装。
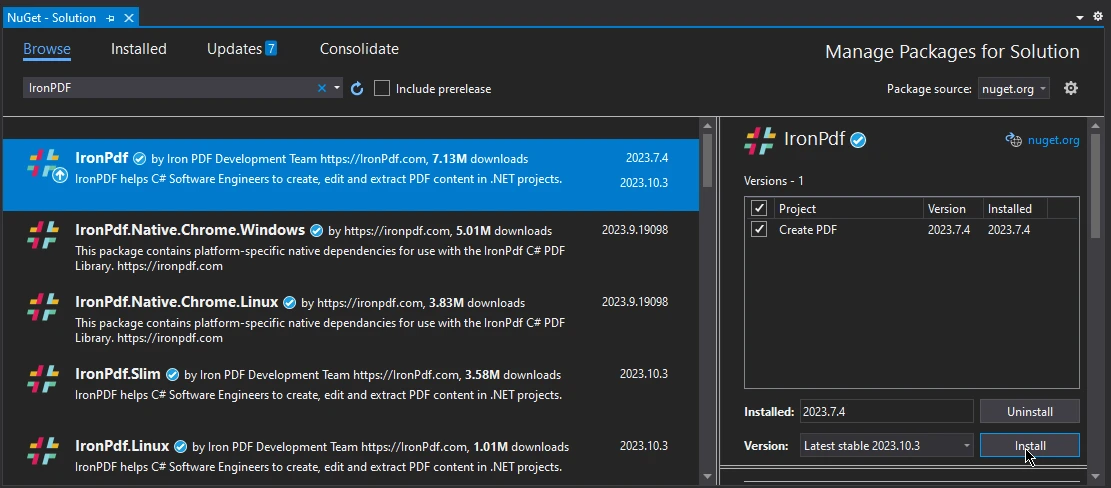
就这样,IronPDF 安装完毕,可以在您的 C# 项目中使用了。
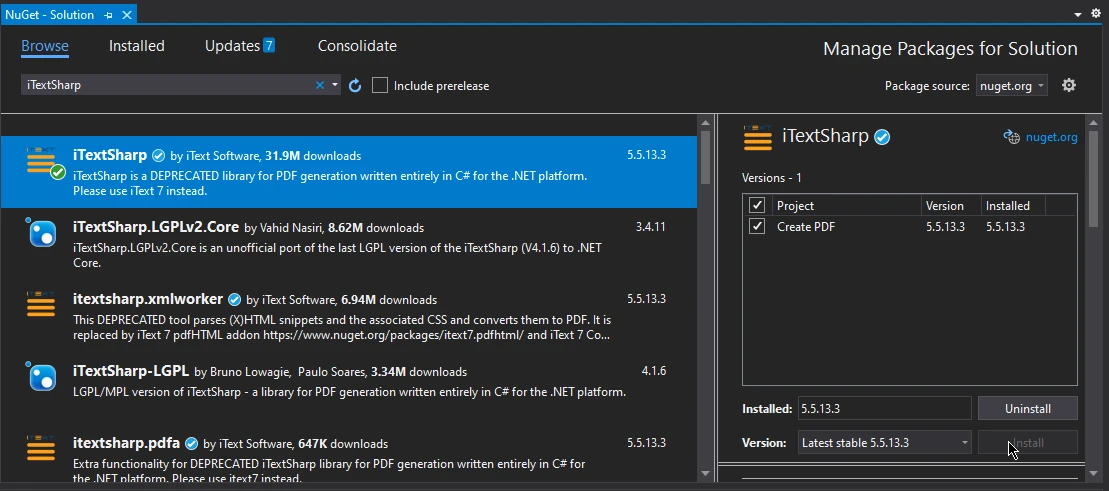
安装 iTextSharp PDF 库与安装 IronPDF 相同。 重复上述步骤,只需在浏览窗口中搜索 "iTextSharp "而不是 IronPDF,从软件包列表中选择并点击安装,即可在项目中集成 iTextSharp PDF 库。
IronPDF 提供从 PDF 文件中提取文本的功能,可根据特定页面自动提取文本或从所有 PDF 文件中提取文本。 在下面的代码示例中,我们将看到如何从 PDF 文档示例的特定页面中提取文本。
using IronPdf;
using System;
using PdfDocument PDF = PdfDocument.FromFile("Watermarked.pdf");
string Text = PDF.ExtractTextFromPage(1);
Console.Write(Text);using IronPdf;
using System;
using PdfDocument PDF = PdfDocument.FromFile("Watermarked.pdf");
string Text = PDF.ExtractTextFromPage(1);
Console.Write(Text);Imports IronPdf
Imports System
Private PdfDocument As using
Private Text As String = PDF.ExtractTextFromPage(1)
Console.Write(Text)上述代码使用 C# 中的 IronPDF 库从 PDF 文件中提取文本并显示在控制台中。 首先,导入必要的命名空间,包括 IronPDF 和 System。 然后,该代码使用FromFile方法将名为"Watermarked.pdf"的PDF文档加载到PdfDocument对象中。 随后,它使用ExtractTextFromPage从PDF的第二页提取文本,并将其存储在名为Text的字符串变量中。 最后,提取的文本使用Console.Write在控制台中显示。

您还可以使用 iTextSharp 从 PDF 文件中提取文本,下面是 iTextSharp 库的一个示例。
using System;
using System.Text;
using iTextSharp.text.pdf;
using iTextSharp.text.pdf.parser;
namespace PDFApp2
{
class Program
{
static void Main(string [] args)
{
string filePath = @"C:\Users\buttw\OneDrive\Desktop\highlighted PDF.pdf";
string outPath = @"C:\Users\buttw\OneDrive\Desktop\name.txt";
int pagesToScan = 2;
string strText = string.Empty;
try
{
PdfReader reader = new PdfReader(filePath);
for (int page = 1; page <= pagesToScan; page++)
{
ITextExtractionStrategy its = new iTextSharp.text.pdf.parser.LocationTextExtractionStrategy();
strText = PdfTextExtractor.GetTextFromPage(reader, page, its);
strText = Encoding.UTF8.GetString(ASCIIEncoding.Convert(Encoding.Default, Encoding.UTF8, Encoding.Default.GetBytes(strText)));
string [] lines = strText.Split('\n');
foreach (string line in lines)
{
using (System.IO.StreamWriter file = new System.IO.StreamWriter(outPath, true))
{
file.WriteLine(line);
}
}
}
reader.Close();
}
catch (Exception ex)
{
Console.Write(ex);
}
}
}
}using System;
using System.Text;
using iTextSharp.text.pdf;
using iTextSharp.text.pdf.parser;
namespace PDFApp2
{
class Program
{
static void Main(string [] args)
{
string filePath = @"C:\Users\buttw\OneDrive\Desktop\highlighted PDF.pdf";
string outPath = @"C:\Users\buttw\OneDrive\Desktop\name.txt";
int pagesToScan = 2;
string strText = string.Empty;
try
{
PdfReader reader = new PdfReader(filePath);
for (int page = 1; page <= pagesToScan; page++)
{
ITextExtractionStrategy its = new iTextSharp.text.pdf.parser.LocationTextExtractionStrategy();
strText = PdfTextExtractor.GetTextFromPage(reader, page, its);
strText = Encoding.UTF8.GetString(ASCIIEncoding.Convert(Encoding.Default, Encoding.UTF8, Encoding.Default.GetBytes(strText)));
string [] lines = strText.Split('\n');
foreach (string line in lines)
{
using (System.IO.StreamWriter file = new System.IO.StreamWriter(outPath, true))
{
file.WriteLine(line);
}
}
}
reader.Close();
}
catch (Exception ex)
{
Console.Write(ex);
}
}
}
}Imports Microsoft.VisualBasic
Imports System
Imports System.Text
Imports iTextSharp.text.pdf
Imports iTextSharp.text.pdf.parser
Namespace PDFApp2
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim filePath As String = "C:\Users\buttw\OneDrive\Desktop\highlighted PDF.pdf"
Dim outPath As String = "C:\Users\buttw\OneDrive\Desktop\name.txt"
Dim pagesToScan As Integer = 2
Dim strText As String = String.Empty
Try
Dim reader As New PdfReader(filePath)
For page As Integer = 1 To pagesToScan
Dim its As ITextExtractionStrategy = New iTextSharp.text.pdf.parser.LocationTextExtractionStrategy()
strText = PdfTextExtractor.GetTextFromPage(reader, page, its)
strText = Encoding.UTF8.GetString(ASCIIEncoding.Convert(Encoding.Default, Encoding.UTF8, Encoding.Default.GetBytes(strText)))
Dim lines() As String = strText.Split(ControlChars.Lf)
For Each line As String In lines
Using file As New System.IO.StreamWriter(outPath, True)
file.WriteLine(line)
End Using
Next line
Next page
reader.Close()
Catch ex As Exception
Console.Write(ex)
End Try
End Sub
End Class
End Namespace所提供的代码是一个 C# 程序,它使用 iTextSharp 库从 PDF 文档的特定页面提取文本并保存到文本文件中。首先,导入了必要的命名空间,包括 System.Text、iTextSharp.text.pdf 和 iTextSharp.text.pdf.parser。 程序会指定文件名、输入 PDF 文件路径、输出文本文件路径和要扫描的页数。 然后,它利用 iTextSharp 的 PdfReader 来读取 PDF 文件。对于每个指定的页面,它使用 iTextSharp 的新 LocationTextExtractionStrategy 提取文本,将编码转换为 UTF-8。提取的文本被分割成行,新的 StringBuilder 文本从 PDF 代码在正确的方向上工作。 过程中遇到的任何异常都会被捕获并显示在控制台中。 程序以关闭PdfReader结束。

iTextSharp 是一个功能强大、用途广泛的 C# 库,它彻底改变了 PDF 操作,实现了无缝内容创建、修改和提取。 其强大的功能使其成为开发人员的首选解决方案,使他们能够生成复杂的 PDF 并有效管理 PDF 中的文本内容。 此外,.NET 领域的另一个著名库 IronPDF 提供了一套全面的 PDF 生成和图像处理工具,增强了开发人员从各种来源轻松创建、修改和渲染高质量 PDF 的能力。 在比较这两个PDF库时,IronPDF由于其文档完备且易于使用的API而占据优势,该API只需几行代码即可完成所有文本提取,而使用iTextSharp则需要编写冗长且复杂的代码,并且需要对库和C#有深入的了解。
要了解更多关于IronPDF 的功能及其特性,请访问官方网站。 使用IronPDF提取文本的完整教程可以在此IronPDF文本提取教程中找到。 关于IronPDF和iTextSharp的完整教程,请访问IronPDF与iTextSharp比较。
无需信用卡
您的试用密钥应该在邮件中。![]() 试用表格已
试用表格已
成功提交。
如果没有,请联系
support@ironsoftware.com
免费开始
无需信用卡
在生产环境中测试,无水印。
随时随地满足您的需求。
获得30天的全功能产品。
几分钟内就能启动并运行。
在您的产品试用期间,全面访问我们的支持工程团队。





预约30分钟的个人演示。
无需合同,无需卡片信息,无需承诺。

