
在實際環境中測試
在生產環境中測試,無水印。
在任何需要的地方都能運行。
Java PDF 檔案庫


本文將使用IronPDF庫以高效的方法在Java中創建PDF解析器。
IronPDF for Java 是一個 Java PDF 函式庫,能夠輕鬆且精確地創建、閱讀和操作 PDF 文件。 它基於IronPDF for .NET的成功之上,並在不同平台上提供高效功能。 IronPDF for Java 使用 IronPdfEngine,該引擎速度快且經過性能優化。
使用 IronPDF,您可以從 PDF 文件中提取文本和圖像,它還可以從包括 HTML 字串、文件、URL 和圖像在內的各種來源創建 PDF。 此外,您可以輕鬆地添加新內容,使用IronPDF插入簽名,並將元數據嵌入PDF文件。 IronPDF 專為 Java 8+、Scala 和 Kotlin 設計,並與 Windows、Linux 和雲端平台相容。
要在 Java 中建立一個 PDF 解析專案,您將需要以下工具:
Java IDE:您可以使用任何支援 Java 的 IDE。有多種 Java IDE 可用於開發。 在本教程中將使用IntelliJ IDE。 您可以使用 NetBeans、Eclipse 等。
Maven 專案:Maven 是一個依賴管理工具,允許對 Java 專案進行控制。 Maven for Java 可以從Maven 官方網站下載。 IntelliJ Java IDE內建對Maven的支持。
IronPDF - 您可以通过多种方式下載並安裝 IronPDF for Java。
pom.xml 文件中添加 IronPDF 依賴。 :ProductInstall造訪 Maven 存儲庫網站,獲取最新的 IronPDF for Java 套件。
直接從 Iron Software 的官方下載頁面下載。
pom.xml文件: <dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.5</version>
</dependency>一旦安裝所有必要的前提條件,第一步是導入必要的IronPDF套件以處理PDF文檔。 在 Main.java 文件的顶部添加以下代码:
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;IronPDF中的某些方法需要許可才能使用。 您可以購買許可證或在免費試用中免費試用IronPDF。 您可以按如下方式設定金鑰:
License.setLicenseKey("YOUR-KEY");要分析現有文件以進行內容提取,使用PdfDocument類。 其靜態fromFile方法用於在Java程式中從特定路徑和特定檔案名稱解析PDF檔案。 代碼如下:
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));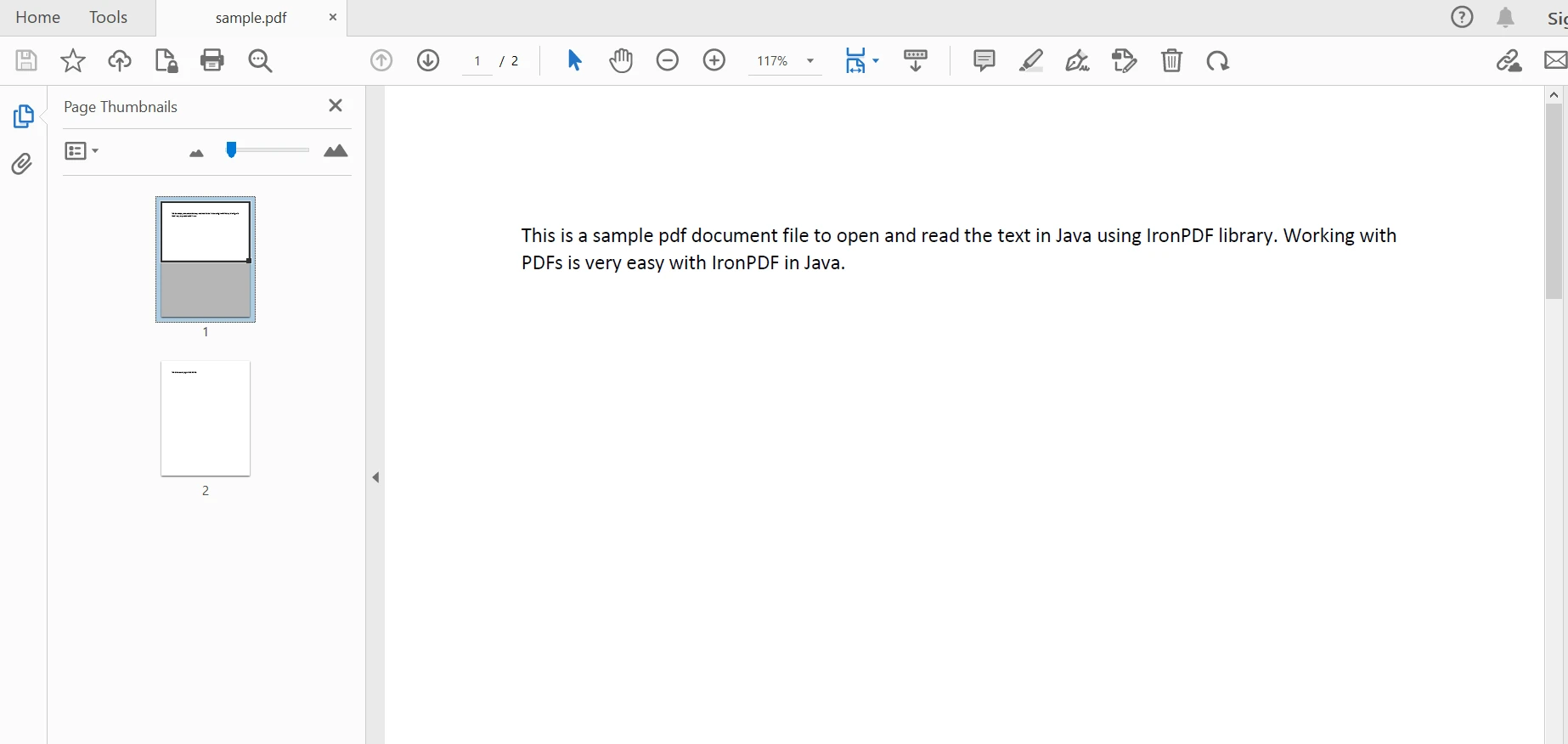
解析文件
IronPDF for Java 提供了一種簡便的方法來從 PDF 文件中提取文字。 以下代碼片段用於從 PDF 文件中提取文字數據:
String extracted_text = parsedDocument.extractAllText();上述程式碼產生如下輸出:
輸出
IronPDF for Java 的功能不僅限於現有的 PDF 文件,它還可以創建和解析新文件以提取內容。 在這裡,本教程將從URL創建 PDF 文件並從中提取內容。 以下示例顯示如何完成此任務:
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extracted_text = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extracted_text);
}
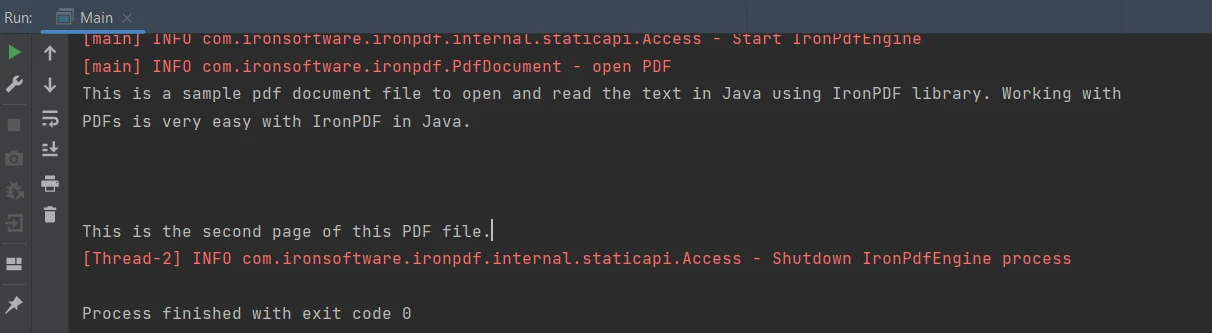
}輸出如下:
輸出
IronPDF還提供了一個簡便的選項來從解析的文檔中提取所有圖像。 在此教程中,我們將使用先前的範例來看看如何輕鬆從 PDF 檔案中提取圖像。
import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}[extractAllImages](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllImages()) 方法返回一個 BufferedImages 的清單。 每個BufferedImage都可以使用ImageIO.write方法儲存為 PNG 圖片。 解析的 PDF 檔案中有 34 張圖像,每張圖像都被完美提取。

提取的圖像
使用[extractAllText 方法](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText(),只需一行代碼就能輕鬆從 PDF 文件中的表格邊界中提取內容。 以下代碼片段示範如何從 PDF 文件中的表格提取文字:
!如何在 Java 中解析 PDF(開發人員教程),圖 5:PDF 中的表格
PDF 中的表格
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extracted_text = parsedDocument.extractAllText();
System.out.println(extracted_text);輸出如下:
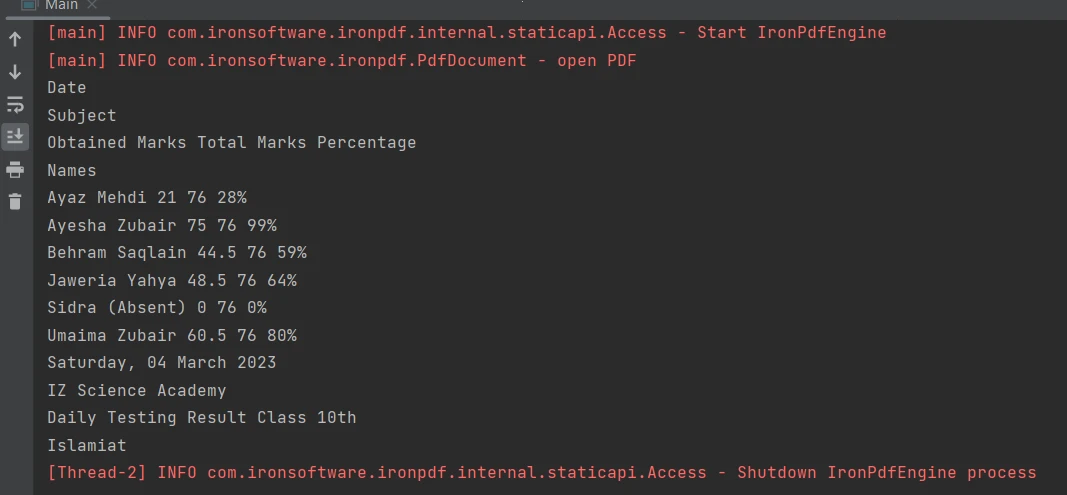
輸出
這篇文章演示了如何在 Java 中使用 IronPDF 解析現有的 PDF 文件或從 URL 創建新的 PDF 解析器文件來提取數據。 打開文件後,可以從 PDF 中提取表格數據、圖像和文本,還可以將提取的文本添加到文本文件中以供日後使用。
有關如何在 Java 中以程式方式處理 PDF 文件的更多詳細資訊,請參閱這些PDF 文件創建範例。
IronPDF for Java 庫可免費用於開發目的,並提供免費試用。 不過,若為商業用途,可通過IronSoftware取得許可,費用從$749起。
Darrius Serrant 擁有邁阿密大學的計算機科學學士學位,目前擔任 Iron Software 的全端 WebOps 行銷工程師。自幼對編程產生興趣,他認為計算機既神秘又易於接觸,使其成為創造力和解決問題的完美媒介。
在 Iron Software,Darrius 享受創造新事物並簡化複雜概念使其更易理解的過程。作為我們的其中一位常駐開發人員,他也自願教導學生,將他的專業知識傳授給下一代。
對 Darrius 來說,他的工作之所以令人滿足,是因為它受到重視並且產生了真正的影響。

<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2025.4.4</version>
</dependency>
不需要信用卡
您的試用金鑰應已發送至您的電子郵件。![]() 試用表格已
試用表格已
成功提交。
如果沒有收到,請聯絡
support@ironsoftware.com

免費開始
不需要信用卡
在生產環境中測試,無水印。
在任何需要的地方都能運行。
獲得 30 天的全功能產品。
在幾分鐘內上手運行。
試用產品期間完全訪問我們的支援工程團隊






預約30分鐘的個人演示。
無合約,無卡片信息,無承諾。

