
在實際環境中測試
在生產環境中測試,無水印。
在任何需要的地方都能運行。
Java PDF 檔案庫


在 Java 中閱讀 PDF 文件可以成為任何專案的核心部分,無論是商業應用程式還是資料分析。 借助IronPDF庫,在您的Java專案中整合PDF處理功能比以往任何時候都更容易。
fromFile方法載入現有的PDF文件extractAllText 方法從開啟的 PDF 中讀取文字IronPDF Java PDF 庫概述 是軟體開發人員的完美解決方案,他們需要快速從 HTML 生成高品質的可捕捉PDF。 該程式庫還提供強大的文件操作工具,使您能夠在IronPDF中對頁面佈局和格式、內容和格式進行動態控制。
讓我們看看如何使用IronPDF庫在Java程式中讀取存儲在路徑上的PDF文件。
第一步是使用Maven安裝IronPDF,更多細節可以參考IronPDF安裝指南。
以下是在 Maven 項目中安裝 IronPDF 的步驟:
在您偏好的 IDE 中打開您的 Maven 專案。
pom.xml文件中,於dependencies部分添加IronPDF庫的依賴。 :ProductInstall保存 pom.xml 文件並讓 Maven 下載並安裝 IronPDF 庫。
安裝完成後,您應該能夠在您的專案中匯入並使用 IronPDF 的下列類別和 Apache Tika 解析器。
以下是可以使用 IronPDF 庫讀取新文件(無論是否具有表格邊界)的代碼。
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
public class Test {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("C:\\sample.pdf"));
String text = pdf.extractAllText();
System.out.println(text);
}
}在這個程式中,使用 IronPDF 中的 PdfDocument 類別 來讀取 PDF 檔案的內容。程式的第一行從 IronPDF 函式庫中匯入所需的類別。 第二行從 Java 標準庫中導入IOException類。
該程式定義了一個名為Test的公共類別。 在這個類中,有一個名為main的public static方法,該方法將一個字符串數組作為參數。
main 方法使用 IronPDF 的 PdfDocument 的 fromFile 方法 來載入位於 "C:\sample.pdf" 的 PDF 文件。 此方法返回一個代表 PDF 文件的 PdfDocument 對象。
一旦載入 PDF 文件,程式會調用 [IronPDF 中 PdfDocument 的 extractAllText 方法](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText()),從 PDF 文件中提取所有文字。這個方法會返回包含 PDF 文件中所有文字的 String。
提取的文本然後儲存在名為 "text" 的String變數中。 此變數可用於處理或顯示 PDF 文件的內容。
最後,程式使用System.out.println方法將提取的文字列印到控制台。
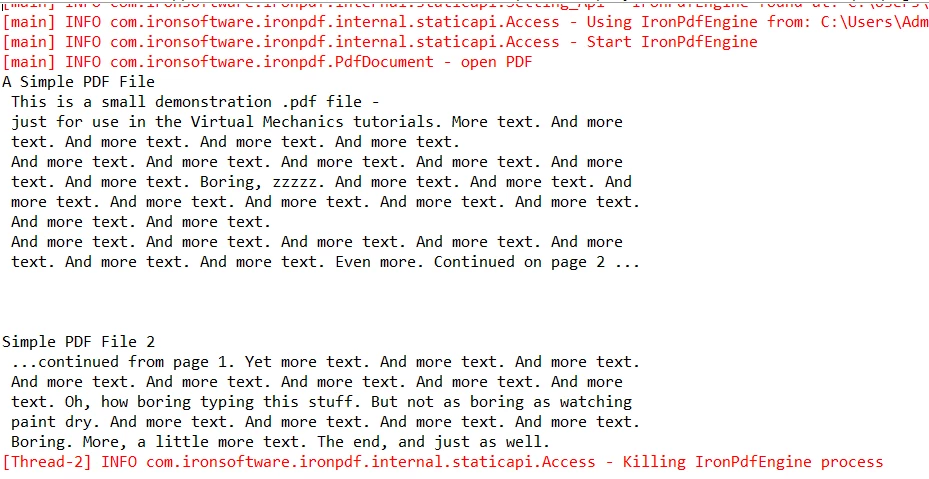
程式輸出
IronPDF 是在 Java 中读取同一路径或多个不同路径中的 PDF 文件的绝佳解决方案,因为它提供了高性能和许多功能,使 PDF 的开发变得简单。 其語法簡單易用。 它的 API 允許開發者快速撰寫他們專案所需的程式碼。
探索 IronPDF 授權選項 計劃起價只需 $749,對於預算有限的人來說,它是可負擔得起的選擇來提取內容。 總體而言,IronPDF 為任何希望在 Java 應用程式中處理 PDF 的 Java 開發人員提供了一個出色的選擇。

<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2025.3.6</version>
</dependency>
不需要信用卡
您的試用金鑰應已發送至您的電子郵件。![]() 試用表格已
試用表格已
成功提交。
如果沒有收到,請聯絡
support@ironsoftware.com

免費開始
不需要信用卡
在生產環境中測試,無水印。
在任何需要的地方都能運行。
獲得 30 天的全功能產品。
在幾分鐘內上手運行。
試用產品期間完全訪問我們的支援工程團隊






預約30分鐘的個人演示。
無合約,無卡片信息,無承諾。

