

如何從 PDF 中提取嵌入的文本和圖像

提取嵌入的文本和圖像涉及檢索文檔內的文字內容和圖形元素。 此過程允許用戶訪問並重新利用內容進行編輯、搜索或將文本轉換為其他格式並保存圖像以便重用或分析。
要從PDF中提取文字和圖像,請使用IronPdf。 提取出的影像可以保存到磁盤上,或轉換成另一種影像格式並嵌入到新渲染的文件中。
開始使用 IronPDF
立即在您的專案中使用IronPDF,並享受免費試用。
如何從 PDF 中提取嵌入的文本和圖像
- 下載 IronPdf C# 庫
- 準備 PDF 文件以進行文字和圖像提取
- 使用
ExtractAllText方法提取文本 - 使用
ExtractAllImages方法提取圖片 - 指定要從中提取文字和圖片的特定頁面
提取文字範例
可以對新生成的和現有的PDF文件進行文本提取。 使用ExtractAllText方法從文件中提取嵌入文字。 此方法將返回一個字符串,包含給定PDF中的所有文字。 頁面由四個連續的 Environment.NewLinesPages 分隔。 讓我們使用我從維基百科網站渲染的範例 PDF。
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text.csusing IronPdf;
using System.IO;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text
string text = pdf.ExtractAllText();
// Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text);Imports IronPdf
Imports System.IO
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text
Private text As String = pdf.ExtractAllText()
' Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text)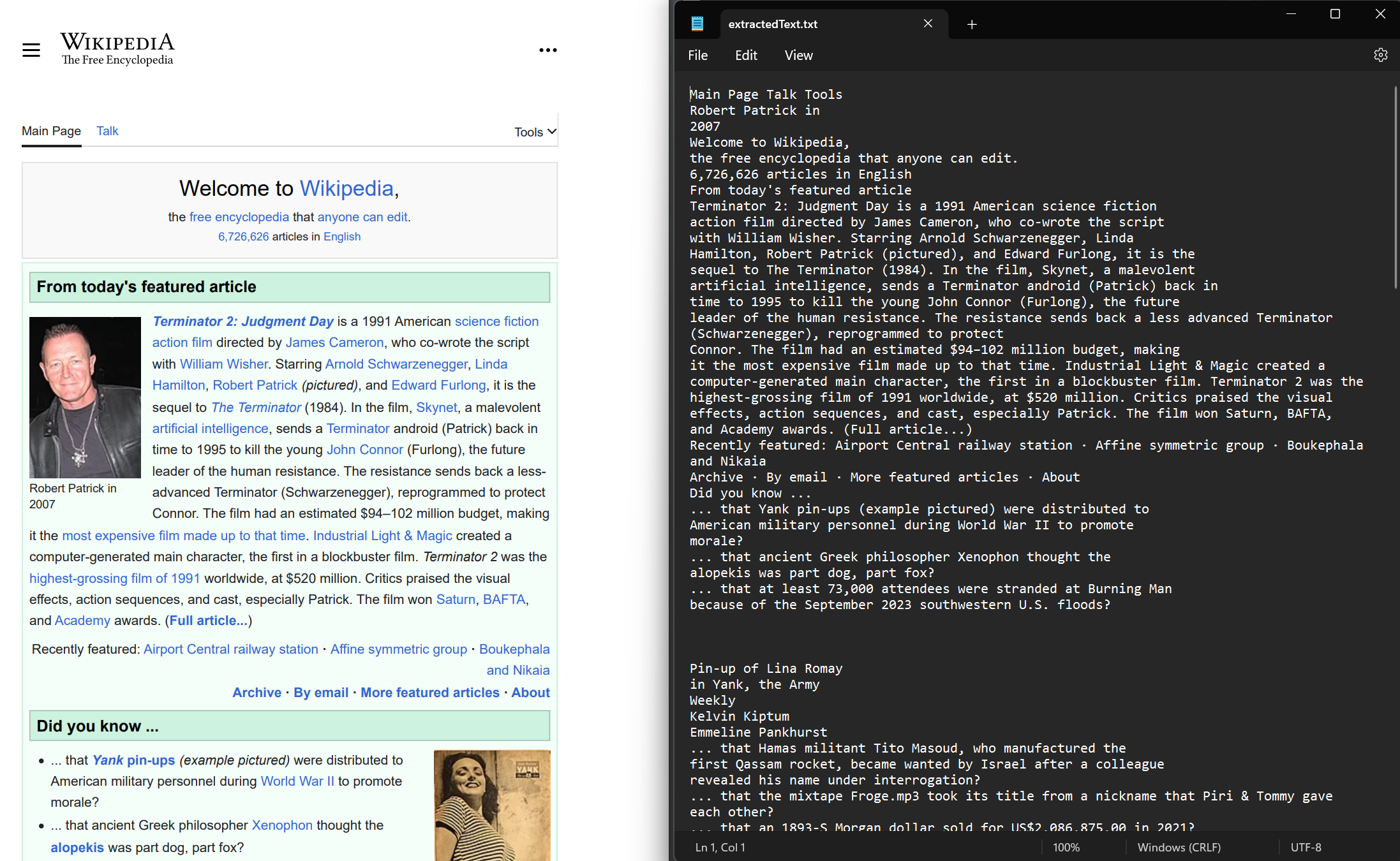
按行和字符提取文本
在每個PDF頁面中,可以檢索文本行和字符的坐標。 首先,從 PDF 中選擇一個頁面,然後訪問行和字符屬性。 座標按照上、右、下和左的值排列,代表文字的位置。
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-by-line-character.csusing IronPdf;
using System.IO;
using System.Linq;
// Open PDF from file
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text by lines
var lines = pdf.Pages[0].Lines;
// Extract text by characters
var characters = pdf.Pages[0].Characters;
File.WriteAllLines("lines.txt", lines.Select(l => $"at Y={l.BoundingBox.Bottom:F2}: {l.Contents}"));Imports IronPdf
Imports System.IO
Imports System.Linq
' Open PDF from file
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text by lines
Private lines = pdf.Pages(0).Lines
' Extract text by characters
Private characters = pdf.Pages(0).Characters
File.WriteAllLines("lines.txt", lines.Select(Function(l) $"at Y={l.BoundingBox.Bottom:F2}: {l.Contents}"))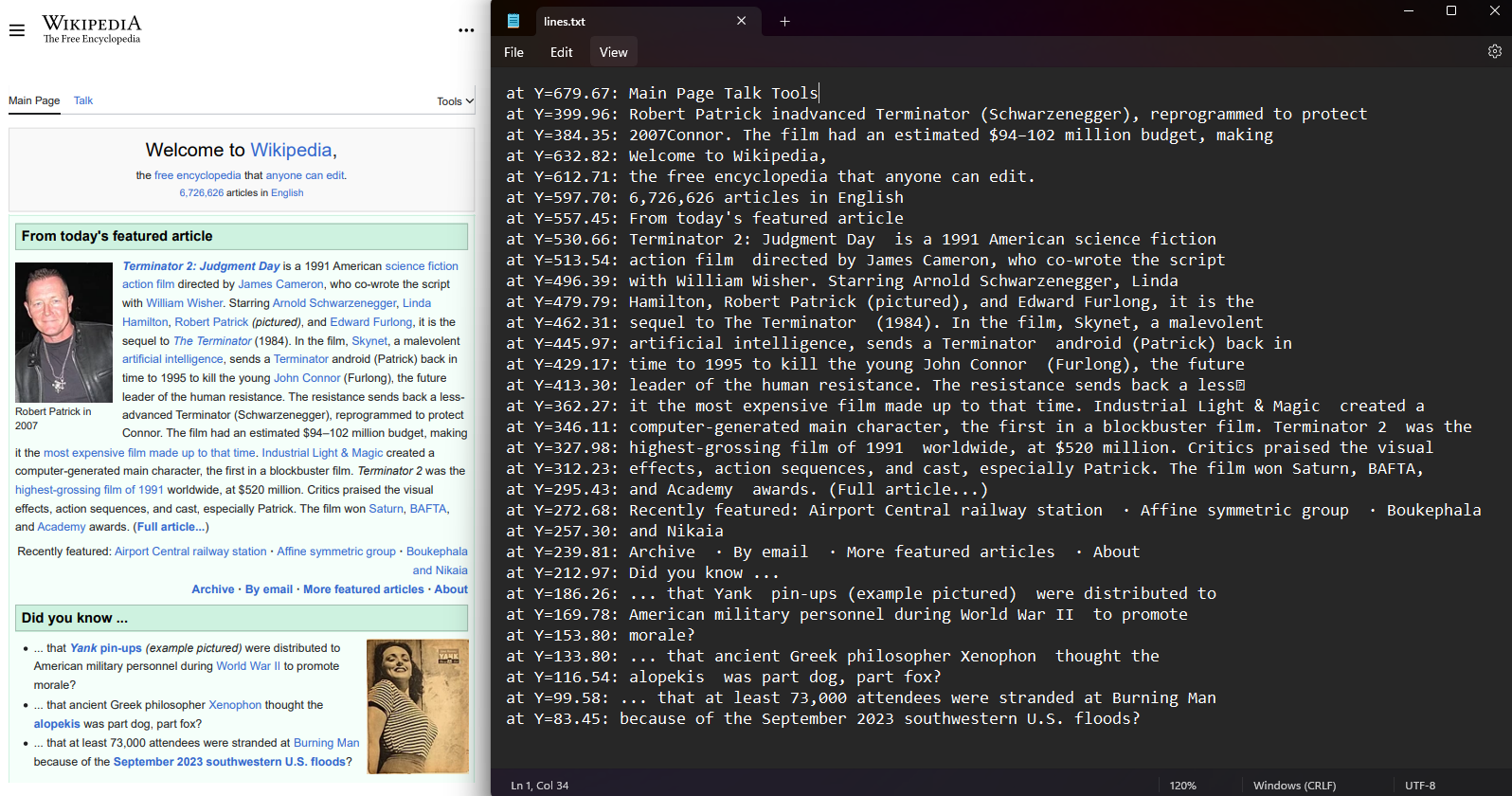
提取圖像示例
使用ExtractAllImages方法提取文檔中嵌入的所有圖片。 該方法將返回一個包含多個AnyBitmap對象的列表。 在我們先前的範例中使用同一份文件,我們提取了圖片並將其匯出至「images」資料夾。
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-image.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract images
var images = pdf.ExtractAllImages();
for(int i = 0; i < images.Count; i++)
{
// Export the extracted images
images[i].SaveAs($"images/image{i}.png");
}Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract images
Private images = pdf.ExtractAllImages()
For i As Integer = 0 To images.Count - 1
' Export the extracted images
images(i).SaveAs($"images/image{i}.png")
Next i
除了上面顯示的ExtractAllImages方法之外,用戶還可以使用ExtractAllBitmaps和ExtractAllRawImages方法從文檔中提取圖像信息。 ExtractAllBitmaps 方法將返回一個 AnyBitmap 的列表,如代碼範例所示,而 ExtractAllRawImages 方法則會從 PDF 文件中提取所有圖像,並以字節數組(byte [])的原始數據形式返回它們。
提取特定頁面的文字和圖像
可以對單一或多個指定頁面進行文本和圖像提取。 使用ExtractTextFromPage和ExtractTextFromPages方法來分別從單個頁面或多個頁面提取文本。 要提取圖像,使用ExtractImagesFromPage和ExtractImagesFromPages方法。
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-single-multiple.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text from page 1
string textFromPage1 = pdf.ExtractTextFromPage(0);
int[] pages = new[] { 0, 2 };
// Extract text from pages 1 & 3
string textFromPage1_3 = pdf.ExtractTextFromPages(pages);Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text from page 1
Private textFromPage1 As String = pdf.ExtractTextFromPage(0)
Private pages() As Integer = { 0, 2 }
' Extract text from pages 1 & 3
Private textFromPage1_3 As String = pdf.ExtractTextFromPages(pages)







