

C# PDF 解析器

2023年1月25日
已更新 2024年12月11日
This article was translated from English: Does it need improvement?
Translated
View the article in English
擁有適當的工具,您可以輕鬆地在 C# 中處理 PDF 檔案,並使用所有適用於 .NET 應用程式所需的功能,包括使用 C# 解析 PDF 檔案的能力。 本教程將使用 IronPDF 這個 C# 函式庫,只需幾個簡單的步驟即可完成。



開始使用 IronPDF
立即在您的專案中使用IronPDF,並享受免費試用。
在 C# 中如何解析 PDF 檔案
- 下載 C# PDF 解析庫
- 在您的 Visual Studio 中安裝
- 使用
ExtractAllText方法提取每一行文本 - 使用
ExtractTextFromPage方法從單個頁面提取所有文本 - 查看解析的 PDF 內容
C#解析 PDF 文件
解析 PDF 文件相當容易。 在以下程式碼中,我們使用 ExtractAllText 方法從整個 PDF 文件中提取每一行文本。 稍後您可以看到提取的PDF內容的並排輸出。
:path=/static-assets/pdf/content-code-examples/how-to/csharp-parse-pdf-parse-pdf.csusing IronPdf;
// Select the desired PDF File
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract all text from an pdf
string allText = pdf.ExtractAllText();
// Extract all text from page 1
string page1Text = pdf.ExtractTextFromPage(0);Imports IronPdf
' Select the desired PDF File
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract all text from an pdf
Private allText As String = pdf.ExtractAllText()
' Extract all text from page 1
Private page1Text As String = pdf.ExtractTextFromPage(0)
$vbLabelText
$csharpLabel
查看解析的 PDF 內容
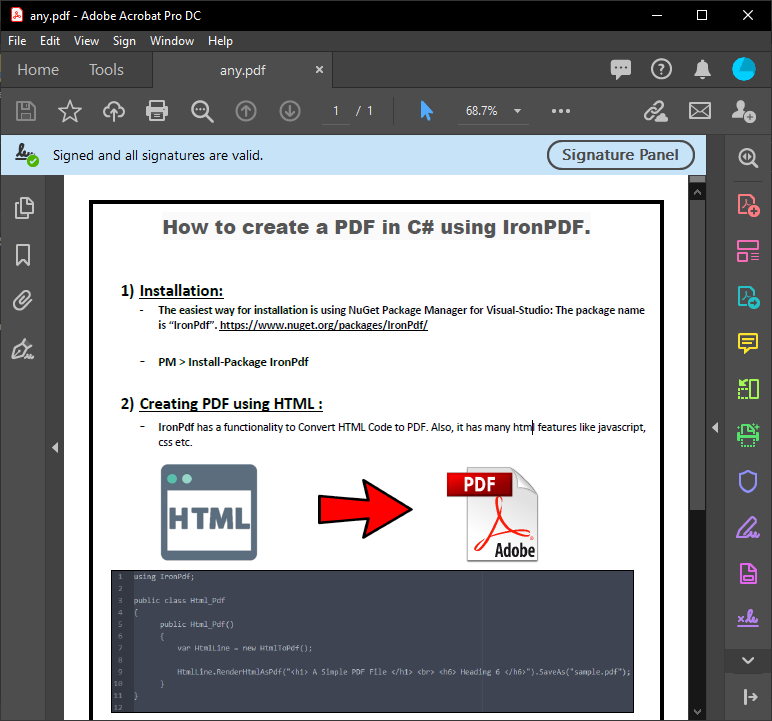
我們使用了一個 C# 表單來顯示上述代碼執行中解析的 PDF 內容。 此輸出提供了 PDF 中的確切文字,因此您可以將其用於個人或客戶的文件需求。
~ PDF ~
~ C# Form ~
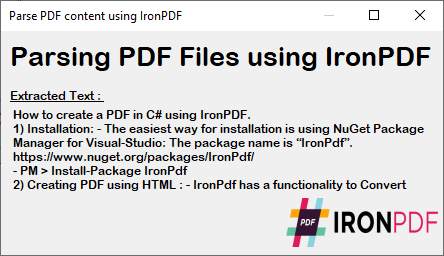
資料庫快速訪問

Chaknith 致力於 IronXL 和 IronBarcode。他在 C# 和 .NET 方面擁有豐富的專業知識,協助改進軟體並支持客戶。他從用戶互動中獲得的洞察力有助於提高產品、文檔和整體體驗。








