
在實際環境中測試
在生產環境中測試,無水印。
在任何需要的地方都能運行。
C# PDF 庫
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


在 .NET 開發中,轉換不同的數據類型是一項重要的技能,尤其是在處理像字符串和整數這樣的常見類型時。 您最常執行的操作之一是將字串變數轉換為整數值。 無論是處理來自用戶輸入、文件或數據庫的數字字串,能夠高效地將字串變量轉換為整數是至關重要的。 幸運的是,C# 提供了多種方法來有效執行這些轉換,多虧了int.Parse()和int.TryParse()方法。
另一方面,在處理 PDF 時,擷取和操作文本資料的能力變得更加重要,尤其是在處理像發票、報告或表單這類經常包含整數字串的文件時。 這就是IronPDF出現了一個強大且易於使用的庫,用於在 .NET 中處理 PDF。 在本文中,我們將演示如何將字串轉換為C#中的整數,以及如何使用IronPDF來幫助您處理.NET專案中的PDF相關任務。
字串轉整數是許多應用程式中的關鍵步驟,尤其在數據以字串形式提供時。 以下是一些常見的使用案例:
在C#中,有幾種方法可以將字串變量轉換為整數值。 最常見的方法包括Parse 方法、TryParse 方法和convert 類別。
int.Parse()方法是一種將字串轉換為整數的簡單方法。 但是,它假設輸入字串的格式是正確的。(即有效數字)如果轉換失敗,將拋出 FormatException。
int number = int.Parse("123");int number = int.Parse("123");Dim number As Integer = Integer.Parse("123")優點:
對於有效的字串輸入,簡單明瞭。
缺點:
為了更安全的轉換,通常使用 TryParse 方法。 它嘗試進行轉換並返回一個布林值,指示轉換是否成功。 如果轉換失敗,則不會拋出異常,只是簡單地返回 false。 結果存儲在一個輸出參數中。
bool success = int.TryParse("123", out int result);bool success = int.TryParse("123", out int result);Dim result As Integer
Dim success As Boolean = Integer.TryParse("123", result)在這裡,success 是一個布林值,表示轉換是否成功,而 number 是轉換後的整數,存儲在輸出參數中。
優點:
適用於您不確定字串是否為有效數字的情況。
缺點:
另一種將字串變數轉換為整數值的方法是使用 convert 類別。 Convert 類別包含可以轉換不同資料類型的方法,包括將字串轉換為整數。
int number = Convert.ToInt32("123");int number = Convert.ToInt32("123");Dim number As Integer = Convert.ToInt32("123")優點:
Convert 類別能夠處理比僅限於字串和整數更廣泛的資料類型。
缺點:
在處理 PDF 時,您可能需要提取並處理嵌入文檔中的任何整數字串。 IronPDF簡化 PDF 操作,讓您能夠無縫地提取文本和數字。 這在需要提取並轉換發票號碼、數量或其他重要數據的情況下特別有用。
IronPDF 提供了全面的功能集來處理 PDF,包括:
PDF 版本支援:可以支援 PDF 版本 1.2-1.7
這些功能使 IronPDF 成為任何需要 PDF 功能的應用程式的強大工具,從簡單的報告到複雜的文件處理系統。
字串轉整數轉換和 PDF 處理結合在一起的關鍵場景之一是當您需要從 PDF 中提取數據時。 例如,您可能希望從 PDF 文件中提取發票號碼、訂單 ID 或數量,這些通常以字串形式出現。 在下一個範例中,我們將展示如何使用IronPDF從PDF中提取文字,並使用TryParse方法將任何整數字符串轉換為整數值。
使用 IronPDF,您可以從 PDF 中提取文字,然後使用 int.TryParse 將任何數字字串轉換為整數。(). 以下是方法:
public static void Main(string[] args)
{
PdfDocument pdf = PdfDocument.FromFile("invoice.pdf");
// Extract text from the PDF
string extractedText = pdf.ExtractAllText();
// Use regex to extract potential numbers from the text
var matches = Regex.Matches(extractedText, @"\d+");
if (matches.Count > 0)
{
Console.WriteLine("Extracted number(s) from PDF:");
foreach (Match match in matches)
{
if (int.TryParse(match.Value, out int num))
{
Console.WriteLine(num);
}
}
}
else
{
Console.WriteLine("Could not find any numbers in the extracted text.");
}
}public static void Main(string[] args)
{
PdfDocument pdf = PdfDocument.FromFile("invoice.pdf");
// Extract text from the PDF
string extractedText = pdf.ExtractAllText();
// Use regex to extract potential numbers from the text
var matches = Regex.Matches(extractedText, @"\d+");
if (matches.Count > 0)
{
Console.WriteLine("Extracted number(s) from PDF:");
foreach (Match match in matches)
{
if (int.TryParse(match.Value, out int num))
{
Console.WriteLine(num);
}
}
}
else
{
Console.WriteLine("Could not find any numbers in the extracted text.");
}
}Public Shared Sub Main(ByVal args() As String)
Dim pdf As PdfDocument = PdfDocument.FromFile("invoice.pdf")
' Extract text from the PDF
Dim extractedText As String = pdf.ExtractAllText()
' Use regex to extract potential numbers from the text
Dim matches = Regex.Matches(extractedText, "\d+")
If matches.Count > 0 Then
Console.WriteLine("Extracted number(s) from PDF:")
For Each match As Match In matches
Dim num As Integer
If Integer.TryParse(match.Value, num) Then
Console.WriteLine(num)
End If
Next match
Else
Console.WriteLine("Could not find any numbers in the extracted text.")
End If
End Sub輸入 PDF
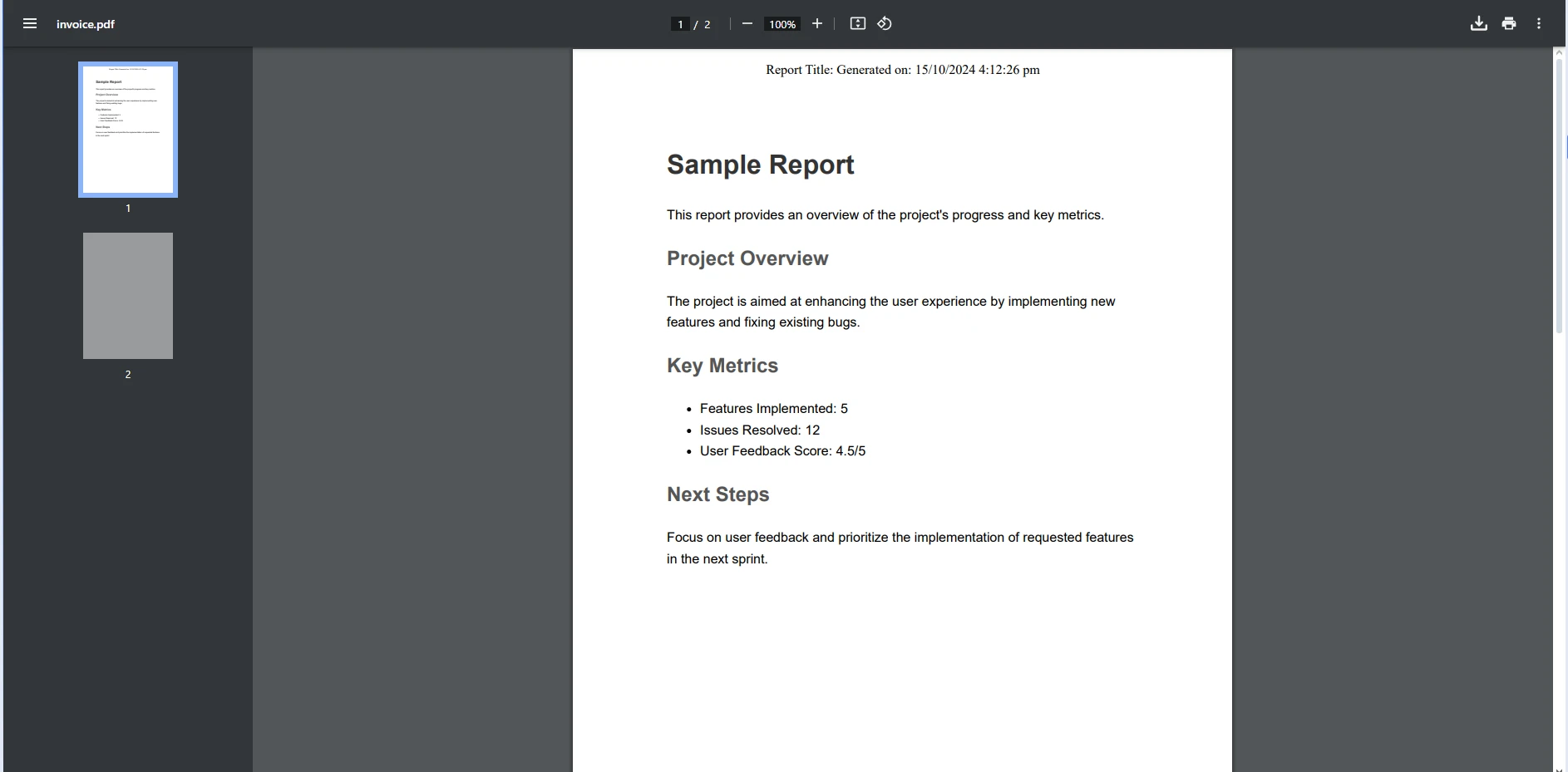
控制台輸出
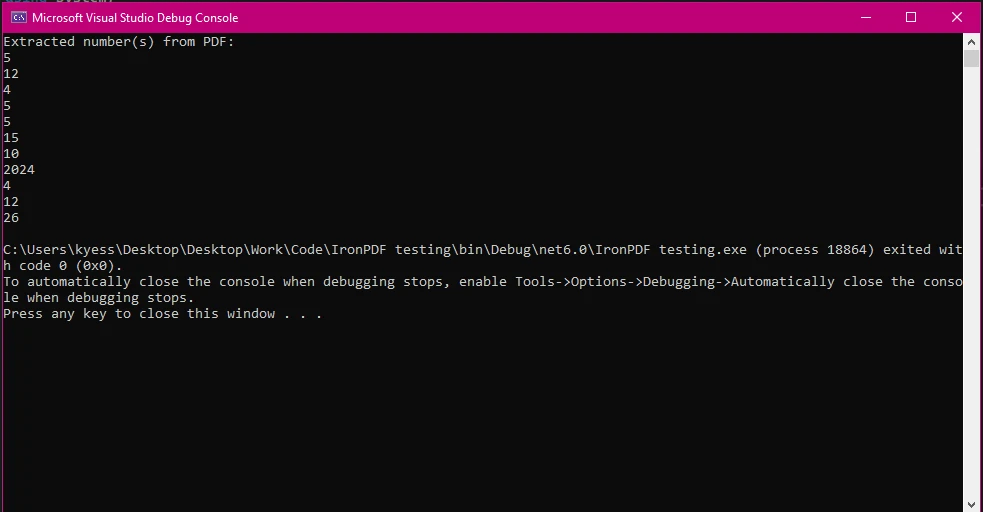
在此程式碼範例中,我們首先載入名為「invoice.pdf」的 PDF 檔案,然後使用 ExtractAllText 擷取文件中的所有文字。() 方法。 為了識別提取文本中的潛在數字,代碼應用了一個正則表達式(正則表達式) \d+,用於匹配數字序列。
匹配項已儲存,如果發現任何數字,將在控制台上顯示。 每個匹配項都使用 int.TryParse 單獨解析為整數。()**,確保僅處理有效的數值。 如果未找到數字,則會顯示一條訊息,指出未提取任何數字。 此方法適用於處理包含數據的 PDF,例如發票,提取和轉換數字是必要的。
以下是一些將提取的 PDF 文本轉換為整數可能有價值的場景:
在 C# 中,將字串轉換為整數是一項基本技能,特別是在處理外部數據來源時。 int.Parse()和 int.TryParse()方法提供靈活的方式來處理這些轉換,確保簡單性和安全性。
同時,IronPDF使 .NET 開發人員能夠輕鬆處理複雜的 PDF 工作流程。 無論您是提取文字、創建動態報告,還是將 PDF 資料轉換為可用格式,IronPDF 都是您開發工具包中的寶貴補充。
想親自嘗試IronPDF嗎? 立即開始您的免費試用體驗 IronPDF 如何改變您在 .NET 應用程式中處理 PDF 的方式!
不需要信用卡
您的試用金鑰應已發送至您的電子郵件。![]() 試用表格已
試用表格已
成功提交。
如果沒有收到,請聯絡
support@ironsoftware.com
免費開始
不需要信用卡
在生產環境中測試,無水印。
在任何需要的地方都能運行。
獲得 30 天的全功能產品。
在幾分鐘內上手運行。
試用產品期間完全訪問我們的支援工程團隊





預約30分鐘的個人演示。
無合約,無卡片信息,無承諾。

