
在實際環境中測試
在生產環境中測試,無水印。
在任何需要的地方都能運行。
C# PDF 庫
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


文字操作是任何 .NET 開發人員的重要技能。 無論您是為用戶輸入清理字串、格式化數據以供分析,還是處理從文件中提取的文本,擁有合適的工具都會產生不同的效果。 在處理PDF時,由於其結構不規則,如何高效管理和處理文本是一項挑戰。 這就是IronPDF這個強大的 C# PDF 處理庫的特長。
在本文中,我們將探討如何利用C# 的 Trim() 方法結合 IronPDF 有效清理和處理 PDF 文件中的文字。
Trim() 方法從字串的開頭和結尾刪除空白或指定的字符。 例如:
string text = " Hello World! ";
string trimmedText = text.Trim(); // Output: "Hello World!" string text = " Hello World! ";
string trimmedText = text.Trim(); // Output: "Hello World!" Dim text As String = " Hello World! "
Dim trimmedText As String = text.Trim() ' Output: "Hello World!"您也可以針對特定字符,例如從字串中移除#符號:
string text = "###Important###";
string trimmedText = text.Trim('#'); // Output: "Important" string text = "###Important###";
string trimmedText = text.Trim('#'); // Output: "Important" Dim text As String = "###Important###"
Dim trimmedText As String = text.Trim("#"c) ' Output: "Important"C# 提供了 TrimStart() 和 TrimEnd() 用於從字串的開頭或結尾移除字符。 例如:
string str = "!!Hello World!!";
string trimmedStart = str.TrimStart('!'); // "Hello World!!"
string trimmedEnd = str.TrimEnd('!'); // "!!Hello World" string str = "!!Hello World!!";
string trimmedStart = str.TrimStart('!'); // "Hello World!!"
string trimmedEnd = str.TrimEnd('!'); // "!!Hello World" Dim str As String = "!!Hello World!!"
Dim trimmedStart As String = str.TrimStart("!"c) ' "Hello World!!"
Dim trimmedEnd As String = str.TrimEnd("!"c) ' "!!Hello World"在空字符串上調用 Trim() 會拋出一個錯誤。 為了避免這種情況,請使用空合併運算符或條件檢查:
string text = null;
string safeTrim = text?.Trim() ?? string.Empty; string text = null;
string safeTrim = text?.Trim() ?? string.Empty; Dim text As String = Nothing
Dim safeTrim As String = If(text?.Trim(), String.Empty)由於 C# 中的字串是不可變的,在迴圈中重複執行 Trim() 操作會降低效能。 對於大型數據集,考慮使用 Span\<T> 或重複使用變數。
意外刪除必要的字符是一個常見的錯誤。 在處理非空白內容時,務必指定要刪除的確切字元。
默認的 Trim() 方法無法處理某些 Unicode 空白字元(例如,\u2003)。 為了解決此問題,將它們明確地包含在修剪參數中。
對於複雜的模式,將 Trim() 與正則表達式結合使用。 例如,要替換多個空格:
string cleanedText = Regex.Replace(text, @"^\s+
\s+$", ""); string cleanedText = Regex.Replace(text, @"^\s+
\s+$", ""); Dim cleanedText As String = Regex.Replace(text, "^\s+
\s+$", "")處理大型文本時,避免重複的修剪操作。 使用 StringBuilder 進行預處理:
var sb = new StringBuilder(text);
sb.Trim(); // Custom extension method to trim once var sb = new StringBuilder(text);
sb.Trim(); // Custom extension method to trim once Dim sb = New StringBuilder(text)
sb.Trim() ' Custom extension method to trim once雖然 Trim() 對文化不敏感,但在極少數情況下,你可以使用 CultureInfo 進行對區域設定敏感的修剪。
從 PDF 中提取文本時,常常會遇到前置和尾隨字符,例如特殊符號、不必要的空格或格式工件。 例如:
在 OCR 生成的內容中,符號(例如,*、-)的開頭和結尾經常出現。
使用 Trim() 可讓您清理當前的字串物件並準備其進行進一步的操作。
IronPDF 是一個強大的 .NET PDF 操作庫,旨在讓操作 PDF 文件變得簡單。 它提供功能,使您能以最少的設置和編程努力生成、編輯和從 PDF 中提取內容。 以下是IronPDF提供的一些主要功能:
IronPDF 擅長處理非結構化的 PDF 數據,使其易於提取、清理和高效處理文本。 使用案例包括:
首先透過 NuGet 安裝 IronPDF:
在 Visual Studio 中打開您的專案。
Install-Package IronPDFInstall-Package IronPDF'INSTANT VB TODO TASK: The following line uses invalid syntax:
'Install-Package IronPDF這是一個完整的例子,說明如何從 PDF 提取文字,並使用 Trim() 來刪除指定的字符:
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("trimSample.pdf");
// Extract text from the PDF
string extractedText = pdf.ExtractAllText();
// Trim whitespace and unwanted characters
string trimmedText = extractedText.Trim('*');
// Display the cleaned text
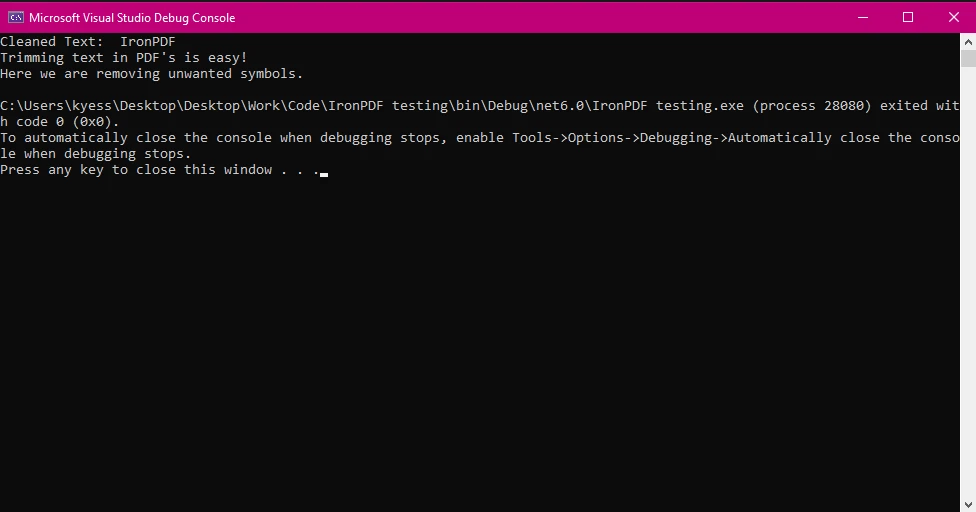
Console.WriteLine($"Cleaned Text: {trimmedText}");
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("trimSample.pdf");
// Extract text from the PDF
string extractedText = pdf.ExtractAllText();
// Trim whitespace and unwanted characters
string trimmedText = extractedText.Trim('*');
// Display the cleaned text
Console.WriteLine($"Cleaned Text: {trimmedText}");
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile("trimSample.pdf")
' Extract text from the PDF
Dim extractedText As String = pdf.ExtractAllText()
' Trim whitespace and unwanted characters
Dim trimmedText As String = extractedText.Trim("*"c)
' Display the cleaned text
Console.WriteLine($"Cleaned Text: {trimmedText}")
End Sub
End Class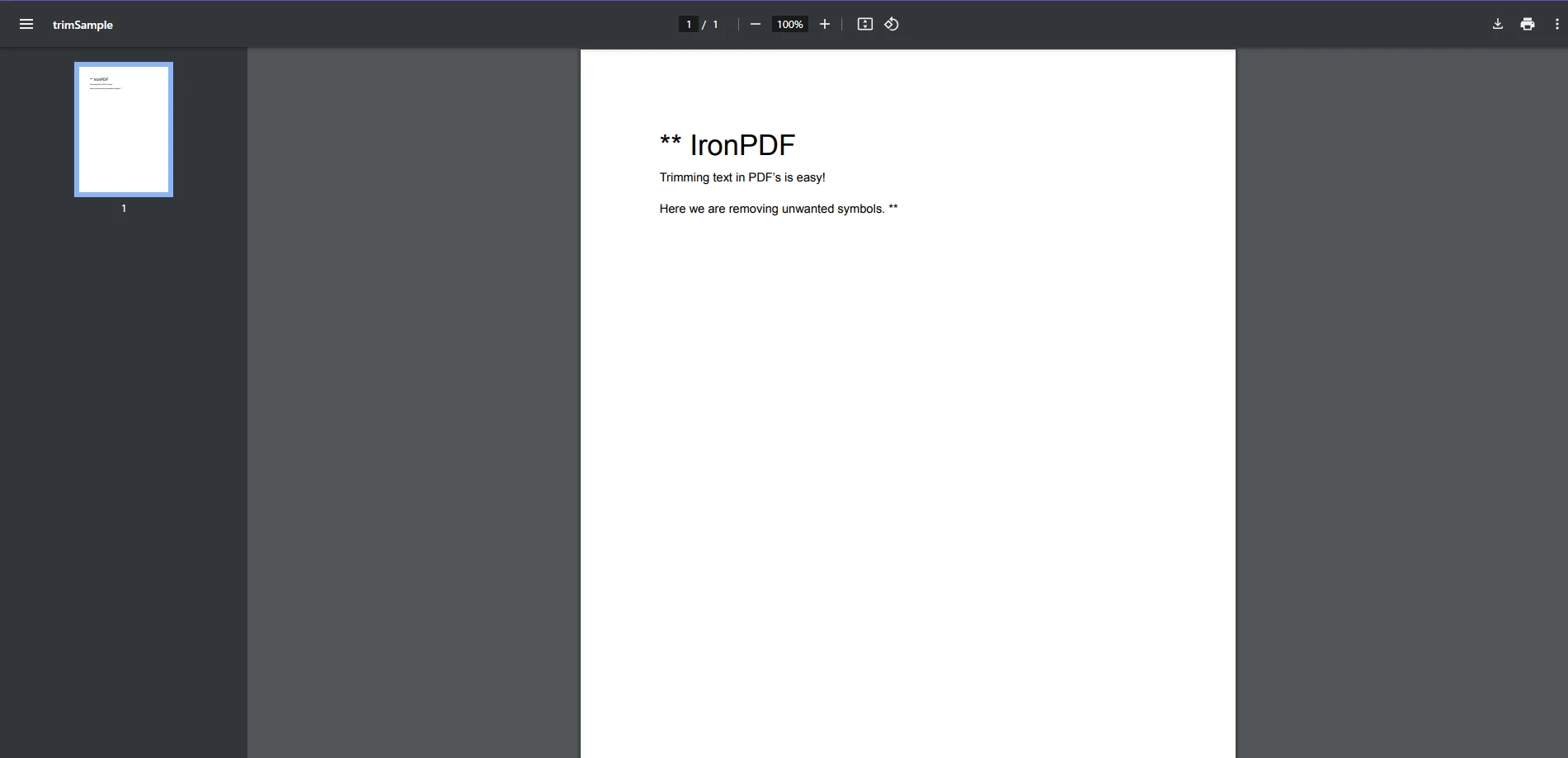
從 PDF 發票中提取文本,修剪不必要的內容,並解析總計或發票編號等重要細節。 範例:
光學字元識別 (OCR) 經常會產生噪音文字。 通過使用IronPDF的文字提取和C#修整功能,您可以整理輸出以便進一步處理或分析。
高效的文本處理對於 .NET 開發人員來說是一項關鍵技能,尤其是在處理來自 PDF 的非結構化數據時。 Trim() 方法,特別是 public string Trim,結合 IronPDF 的功能,提供了一種可靠的方法來清理和處理文本,通過移除前導和尾隨空格、指定字符,甚至是 Unicode 字符。
透過應用像 TrimEnd() 這樣的方法來移除尾隨字元,或執行尾端修剪操作,您可以將雜亂的文字轉換為可用於報告、自動化和分析的內容。 上述方法允許開發人員精確地清理現有字串,提升涉及 PDF 的工作流程。
通過將IronPDF強大的 PDF 操作功能與 C# 多功能的 Trim() 方法相結合,您可以在開發需要精確文字格式的解決方案時節省時間和精力。 以往需要數小時完成的任務,如去除不必要的空白、清理 OCR 生成的文本或標準化提取的數據,現在可以在幾分鐘內完成。
今天就將您的 PDF 處理能力提升到新的水平—下載 IronPDF 的免費試用版,親眼見證它如何改變您的 .NET 開發體驗。 無論您是新手還是有經驗的開發者,IronPDF都是您構建更智能、更快速和更高效解決方案的夥伴。
不需要信用卡
您的試用金鑰應已發送至您的電子郵件。![]() 試用表格已
試用表格已
成功提交。
如果沒有收到,請聯絡
support@ironsoftware.com
免費開始
不需要信用卡
在生產環境中測試,無水印。
在任何需要的地方都能運行。
獲得 30 天的全功能產品。
在幾分鐘內上手運行。
試用產品期間完全訪問我們的支援工程團隊





預約30分鐘的個人演示。
無合約,無卡片信息,無承諾。

