
在實際環境中測試
在生產環境中測試,無水印。
在任何需要的地方都能運行。
C# PDF 庫
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


在當今的開發世界中,處理PDF是需要處理文件、表單或報告的應用程式的一項常見要求。 無論您是在建立電子商務平台、文件管理系統,還是僅需處理發票,從 PDF 中提取和搜尋文字都可能是至關重要的。 本文將指導您如何使用C# string.Contains()與IronPDF在您的 .NET 專案中搜尋並提取 PDF 文件中的文本。
在進行搜尋時,您可能需要根據特定的字串子字串要求來執行字串比較。 在這種情況下,C# 提供了像 string.Contains 這樣的選項。(),這是最簡單的比較形式之一。
如果您需要指定是否忽略大小寫,您可以使用 StringComparison 列舉。 這可以讓您選擇所需的字串比較類型,例如序數比較或不區分大小寫比較。
如果您想在字串中處理特定位置,例如第一個字元位置或最後一個字元位置,您可以始終使用 Substring 來隔離字串的某些部分以進行進一步處理。
如果您正在尋找空字串檢查或其他極端情況,請確保在您的邏輯中處理這些情況。
如果您正在處理大型文件,則最好優化文本提取的起始位置,以僅提取相關部分而不是整個文件。 這在您嘗試避免記憶體和處理時間過載時特別有用。
如果您不確定比較規則的最佳方法,請考慮特定方法的執行效果以及希望搜索在不同情況下的行為。(例如,匹配多個術語、處理空格等。).
如果您的需求超出簡單的子字串檢查並需要更高級的模式匹配,請考慮使用正則表達式,這在處理PDF時提供了顯著的靈活性。
如果您還沒有的話,請嘗試使用IronPDF免費試用今天就來探索其功能,看看它如何簡化您的 PDF 處理任務。 無論您是在構建文檔管理系統、處理發票,還是僅需要從 PDF 中提取數據,IronPDF 都是完成這項工作的理想工具。
IronPDF 是一個強大的函式庫,旨在幫助在 .NET 生態系統中處理 PDF 的開發人員。 它使您能夠輕鬆建立、讀取、編輯和操作 PDF 文件,無需依賴外部工具或複雜的配置。
IronPDF為C#應用程式提供了廣泛的PDF操作功能。 一些主要功能包括:
表單處理:提取或填入互動式 PDF 表單中的欄位。
IronPDF 被設計成簡單易用,但也足夠靈活以處理涉及 PDF 的複雜情境。 它能與 .NET Core 和 .NET Framework 無縫協作,成為任何基於 .NET 的專案的完美選擇。
使用IronPDF,通過 Visual Studio 中的 NuGet 套件管理器安裝:
Install-Package IronPdfInstall-Package IronPdf'INSTANT VB TODO TASK: The following line uses invalid syntax:
'Install-Package IronPdf在深入搜尋 PDF 之前,我們先了解如何使用 IronPDF 從 PDF 中提取文本。
IronPDF 提供一個簡單的 API 從 PDF 文件中提取文本。 這讓您可以輕鬆搜尋PDF中的特定內容。
以下範例演示如何使用IronPDF從PDF中提取文本:
using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
PdfDocument pdf = PdfDocument.FromFile("invoice.pdf");
string str = pdf.ExtractAllText();
}
}using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
PdfDocument pdf = PdfDocument.FromFile("invoice.pdf");
string str = pdf.ExtractAllText();
}
}Imports IronPdf
Imports System
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim pdf As PdfDocument = PdfDocument.FromFile("invoice.pdf")
Dim str As String = pdf.ExtractAllText()
End Sub
End Class在此範例中,ExtractAllText() 方法從 PDF 文件中提取所有文本。 然後可以處理此文本以搜尋特定的關鍵字或短語。
一旦從 PDF 中提取出文字,您就可以使用 C# 內建的 string.Contains()搜尋特定字詞的方法。
string.Contains()** 方法返回一個布林值,用於指示指定的字串是否存在於字串中。 這對於基本文本搜索非常有用。
以下是您可以如何使用 string.Contains()在提取的文本中搜索關鍵詞:
bool isFound = text.Contains("search term", StringComparison.OrdinalIgnoreCase);bool isFound = text.Contains("search term", StringComparison.OrdinalIgnoreCase);Dim isFound As Boolean = text.Contains("search term", StringComparison.OrdinalIgnoreCase)讓我們用一個實際的例子來進一步分析。 假設您想查找特定的發票號碼是否存在於PDF發票文件中。
以下是一個完整的實例,說明您如何實現這一點:
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string searchTerm = "INV-12345";
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
string text = pdf.ExtractAllText();
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
if (isFound)
{
Console.WriteLine($"Invoice number: {searchTerm} found in the document");
}
else
{
Console.WriteLine($"Invoice number {searchTerm} not found in the document");
}
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string searchTerm = "INV-12345";
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
string text = pdf.ExtractAllText();
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
if (isFound)
{
Console.WriteLine($"Invoice number: {searchTerm} found in the document");
}
else
{
Console.WriteLine($"Invoice number {searchTerm} not found in the document");
}
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim searchTerm As String = "INV-12345"
Dim pdf As PdfDocument = PdfDocument.FromFile("exampleInvoice.pdf")
Dim text As String = pdf.ExtractAllText()
Dim isFound As Boolean = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase)
If isFound Then
Console.WriteLine($"Invoice number: {searchTerm} found in the document")
Else
Console.WriteLine($"Invoice number {searchTerm} not found in the document")
End If
End Sub
End Class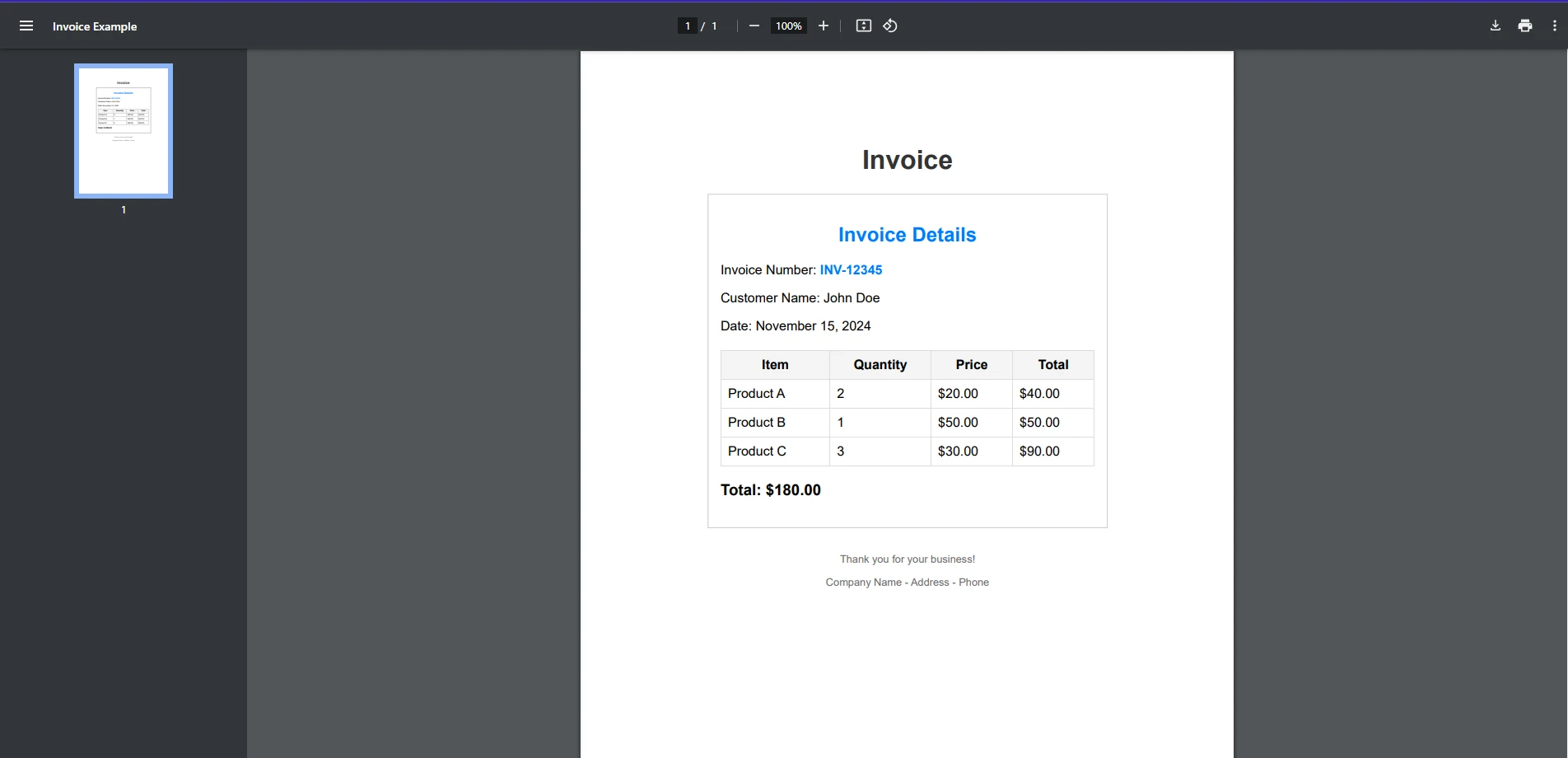
在此範例中:
雖然 string.Contains()適用於簡單的子字串搜尋,您可能希望執行更複雜的搜尋,例如尋找模式或一系列關鍵字。 為此,您可以使用正則表達式。
以下是一個使用正則表達式在PDF文本中搜索任何有效發票號格式的範例:
using IronPdf;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Define a regex pattern for a typical invoice number format (e.g., INV-12345)
string pattern = @"INV-\d{5}";
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
string text = pdf.ExtractAllText();
// Perform the regex search
Match match = Regex.Match(text, pattern);
}
}using IronPdf;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Define a regex pattern for a typical invoice number format (e.g., INV-12345)
string pattern = @"INV-\d{5}";
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
string text = pdf.ExtractAllText();
// Perform the regex search
Match match = Regex.Match(text, pattern);
}
}Imports IronPdf
Imports System.Text.RegularExpressions
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Define a regex pattern for a typical invoice number format (e.g., INV-12345)
Dim pattern As String = "INV-\d{5}"
Dim pdf As PdfDocument = PdfDocument.FromFile("exampleInvoice.pdf")
Dim text As String = pdf.ExtractAllText()
' Perform the regex search
Dim match As Match = Regex.Match(text, pattern)
End Sub
End Class此代碼將搜尋任何符合模式 INV-XXXXX 的發票號碼,其中 XXXXX 為一系列數字。
在處理 PDF 文件時,特別是大型或複雜的文件,有幾個最佳實踐需要注意:
IronPDF 輕鬆整合到 .NET 專案中。 在通過 NuGet 下載並安裝 IronPDF 庫後,只需將其匯入到您的 C# 程式碼庫中,如上面的範例所示。
IronPDF 的靈活性使您能夠構建複雜的文檔處理工作流程,例如:
IronPDF使處理 PDF 變得簡單高效,特別是在需要提取和搜尋 PDF 中的文字時。 通過結合 C# 的 string.Contains()使用 IronPDF 的文字提取功能,您可以在 .NET 應用程式中快速搜索和處理 PDF 文件。
如果您尚未嘗試過,請立即試用 IronPDF 的免費試用版,以探索其功能,看看它如何簡化您的 PDF 處理任務。 無論您是在構建文檔管理系統、處理發票,還是僅需要從 PDF 中提取數據,IronPDF 都是完成這項工作的理想工具。
要開始使用 IronPDF,下載免費試用親身體驗其強大的 PDF 操作功能。 參觀IronPDF 的網站立即開始。
不需要信用卡
您的試用金鑰應已發送至您的電子郵件。![]() 試用表格已
試用表格已
成功提交。
如果沒有收到,請聯絡
support@ironsoftware.com
免費開始
不需要信用卡
在生產環境中測試,無水印。
在任何需要的地方都能運行。
獲得 30 天的全功能產品。
在幾分鐘內上手運行。
試用產品期間完全訪問我們的支援工程團隊





預約30分鐘的個人演示。
無合約,無卡片信息,無承諾。

