
在實際環境中測試
在生產環境中測試,無水印。
在任何需要的地方都能運行。
C# PDF 庫
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


Parallel.ForEach是一個 C# 方法,允許您對集合或資料來源執行平行迭代。 平行迴圈不是依序處理集合中的每個項目,而是可以同時執行,透過減少整體執行時間來顯著提升效能。平行處理透過將工作分配到多個核心處理器上來運作,允許任務同時運行。 這在處理彼此獨立的任務時特別有用。
與普通的 foreach 迴圈按順序處理項目不同,並行方法可以通過並行使用多個執行緒來處理大型數據集,速度要快得多。
IronPDF是一個功能強大的.NET PDF處理庫,能夠將 HTML 轉換為 PDF, 從 PDF 中提取文本, 合併和拆分文件,以及更多。 在處理大量 PDF 任務時,使用 Parallel.ForEach 進行並行處理可以顯著減少執行時間。無論是生成數百個 PDF 還是同時從多個文件中提取數據,利用 IronPDF 的數據並行性能確保任務更快且更有效率地完成。
此指南適用於希望使用 IronPDF 和 Parallel.ForEach 來優化其 PDF 處理任務的 .NET 開發人員。 建議具備 C# 的基本知識和對 IronPDF 函式庫的熟悉。 在本指南結束時,您將能夠實現並行處理,以同時處理多個 PDF 任務,從而改善性能和擴展性。
使用IronPDF在您的專案中,您需要通過 NuGet 安裝該庫。
要安裝 IronPDF,請按照以下步驟操作:
在 Visual Studio 中打開您的專案。
前往 工具 → NuGet 套件管理員 → 管理解決方案的 NuGet 套件。
或者,您可以通過 NuGet 套件管理器控制台安裝它:
Install-Package IronPdfInstall-Package IronPdf'INSTANT VB TODO TASK: The following line uses invalid syntax:
'Install-Package IronPdf安裝 IronPDF 後,您就可以開始使用它進行 PDF 生成和操作任務。
Parallel.ForEach 是 System.Threading.Tasks 命名空间的一部分,提供了一种简单有效的方式来同时执行迭代。 Parallel.ForEach 的語法如下:
Parallel.ForEach(collection, item =>
{
// Code to process each item
});Parallel.ForEach(collection, item =>
{
// Code to process each item
});Parallel.ForEach(collection, Sub(item)
' Code to process each item
End Sub)集合中的每個項目都會並行處理,系統會決定如何將工作負載分配到可用的執行緒中。 您也可以指定選項來控制並行度,例如使用的最大執行緒數。
相比之下,傳統的 foreach 迴圈依次處理每一項,而平行迴圈可以同時處理多個項目,在處理大型集合時提高效能。
首先,確保已按照「入門指南」部分的說明安裝了IronPDF。 接下來,您可以開始編寫平行 PDF 處理邏輯。
string[] htmlPages = { "page1.html", "page2.html", "page3.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
});string[] htmlPages = { "page1.html", "page2.html", "page3.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
});Dim htmlPages() As String = { "page1.html", "page2.html", "page3.html" }
Parallel.ForEach(htmlFiles, Sub(htmlFile)
' Load the HTML content into IronPDF and convert it to PDF
Dim renederer As New ChromePdfRenderer()
Dim pdf As PdfDocument = renederer.RenderHtmlAsPdf(htmlFile)
' Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf")
End Sub)此程式碼演示如何並行將多個 HTML 頁面轉換為 PDF。
在處理平行任務時,錯誤處理是至關重要的。 在 Parallel.ForEach 迴圈中使用 try-catch 區塊來管理任何例外狀況。
Parallel.ForEach(pdfFiles, pdfFile =>
{
try
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractAllText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {pdfFile}: {ex.Message}");
}
});Parallel.ForEach(pdfFiles, pdfFile =>
{
try
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractAllText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {pdfFile}: {ex.Message}");
}
});Parallel.ForEach(pdfFiles, Sub(pdfFile)
Try
Dim pdf = IronPdf.PdfDocument.FromFile(pdfFile)
Dim text As String = pdf.ExtractAllText()
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text)
Catch ex As Exception
Console.WriteLine($"Error processing {pdfFile}: {ex.Message}")
End Try
End Sub)平行處理的另一個用例是從一批 PDF 中提取文本。 在處理多個 PDF 檔案時,同時執行文本提取可以節省大量時間。以下示例演示了如何實現這一點。
using IronPdf;
using System.Linq;
using System.Threading.Tasks;
class Program
{
static void Main(string[] args)
{
string[] pdfFiles = { "doc1.pdf", "doc2.pdf", "doc3.pdf" };
Parallel.ForEach(pdfFiles, pdfFile =>
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
});
}
}using IronPdf;
using System.Linq;
using System.Threading.Tasks;
class Program
{
static void Main(string[] args)
{
string[] pdfFiles = { "doc1.pdf", "doc2.pdf", "doc3.pdf" };
Parallel.ForEach(pdfFiles, pdfFile =>
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
});
}
}Imports IronPdf
Imports System.Linq
Imports System.Threading.Tasks
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim pdfFiles() As String = { "doc1.pdf", "doc2.pdf", "doc3.pdf" }
Parallel.ForEach(pdfFiles, Sub(pdfFile)
Dim pdf = IronPdf.PdfDocument.FromFile(pdfFile)
Dim text As String = pdf.ExtractText()
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text)
End Sub)
End Sub
End Class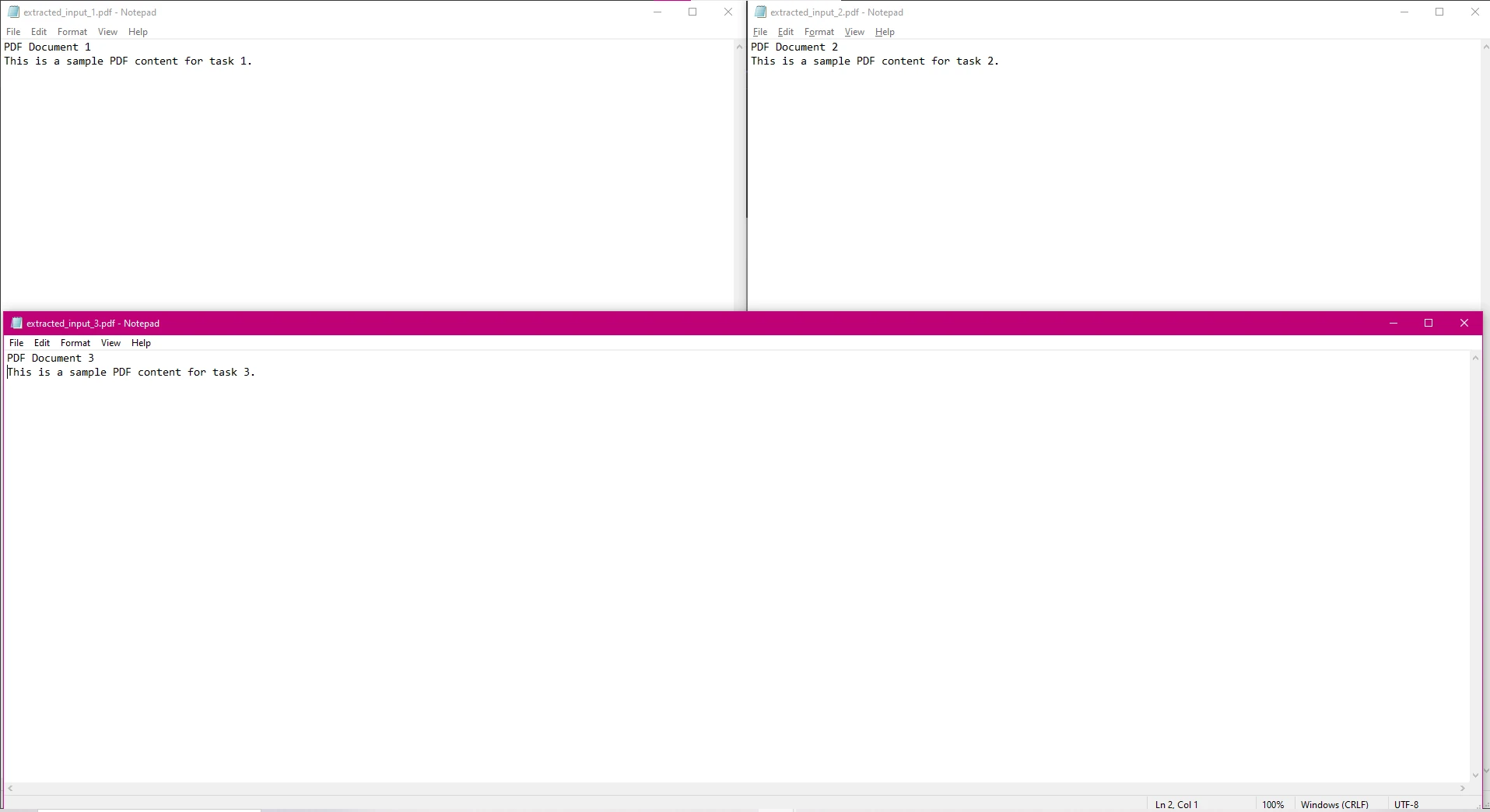
在這段程式碼中,每個 PDF 檔案會被平行處理以提取文本,並將提取的文本儲存在單獨的文本檔案中。
在此範例中,我們將從多個 HTML 文件中平行生成多個 PDF,這可能是當您需要將多個動態 HTML 頁面轉換為 PDF 文件時的典型情況。
using IronPdf;
string[] htmlFiles = { "example.html", "example_1.html", "example_2.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
try
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlFileAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
Console.WriteLine($"PDF created for {htmlFile}");
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {htmlFile}: {ex.Message}");
}
});using IronPdf;
string[] htmlFiles = { "example.html", "example_1.html", "example_2.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
try
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlFileAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
Console.WriteLine($"PDF created for {htmlFile}");
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {htmlFile}: {ex.Message}");
}
});Imports IronPdf
Private htmlFiles() As String = { "example.html", "example_1.html", "example_2.html" }
Parallel.ForEach(htmlFiles, Sub(htmlFile)
Try
' Load the HTML content into IronPDF and convert it to PDF
Dim renederer As New ChromePdfRenderer()
Dim pdf As PdfDocument = renederer.RenderHtmlFileAsPdf(htmlFile)
' Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf")
Console.WriteLine($"PDF created for {htmlFile}")
Catch ex As Exception
Console.WriteLine($"Error processing {htmlFile}: {ex.Message}")
End Try
End Sub)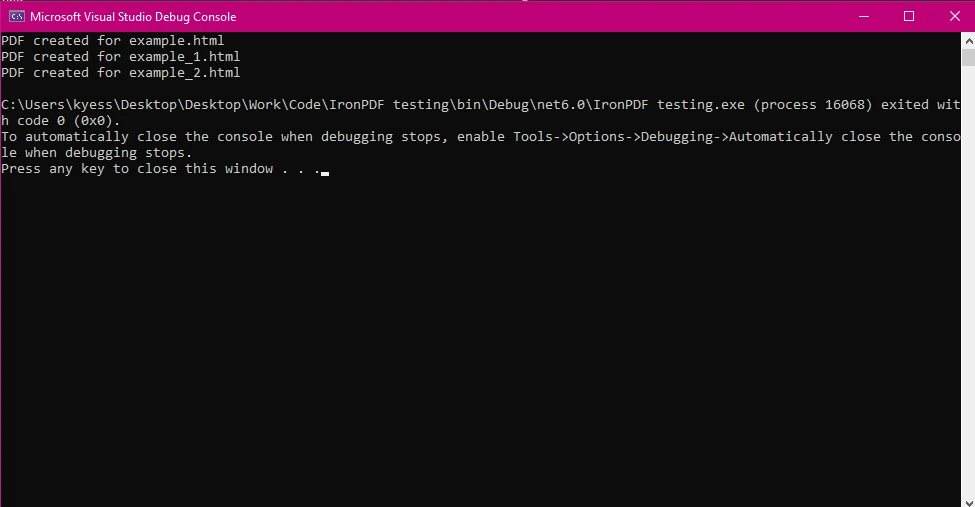
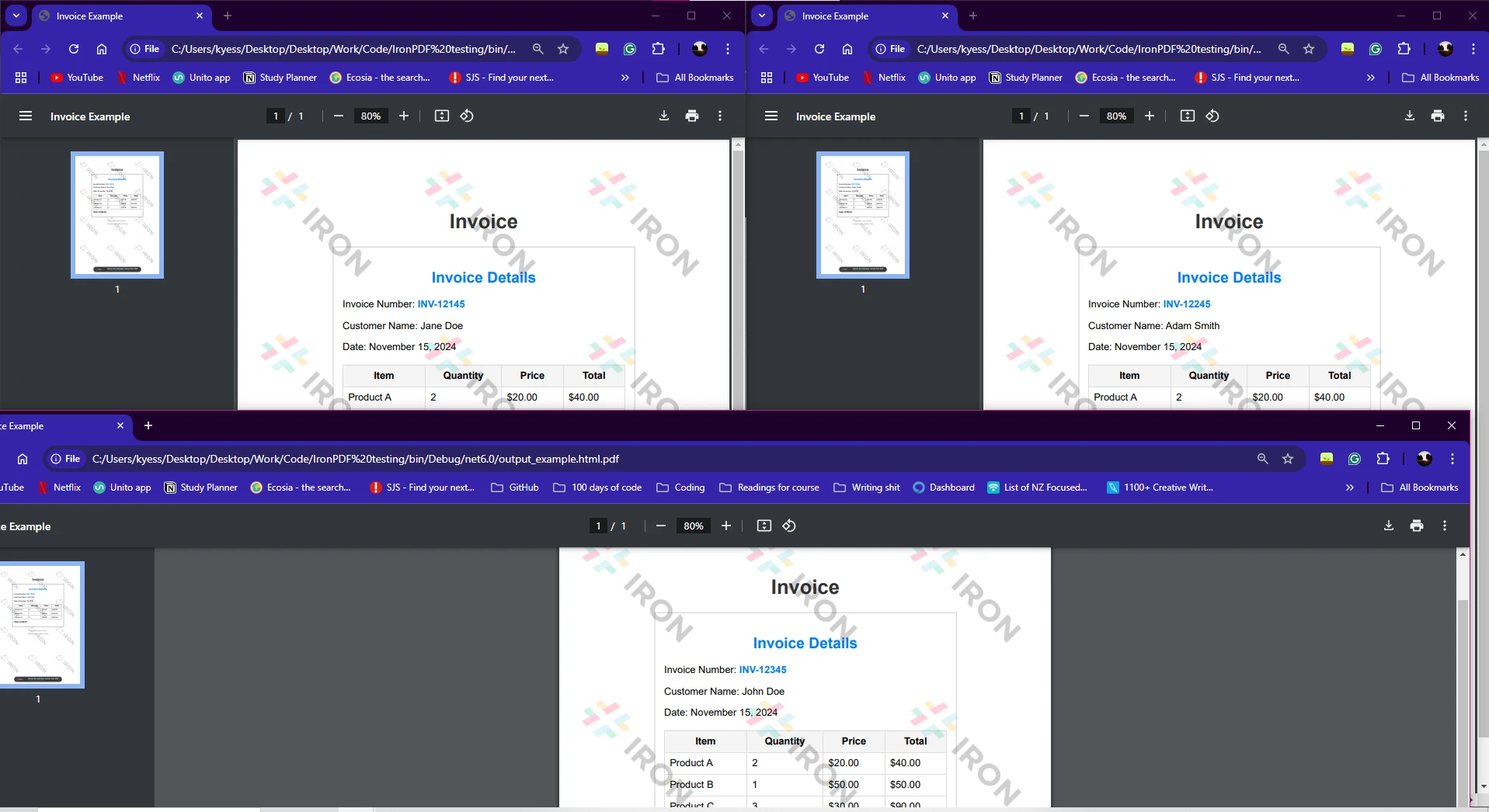
HTML 檔案: 陣列 htmlFiles 包含您想要轉換成 PDF 的多個 HTML 檔案路徑。
並行處理:
儲存 PDF: 生成 PDF 之後,使用 pdf.SaveAs 方法將其儲存,並將輸出檔案名稱附加上原始 HTML 檔案的名稱。
IronPDF 在大多數操作中是執行緒安全的。 然而,一些操作如并行写入相同檔案可能會導致問題。 請務必確保每個平行任務在不同的輸出檔或資源上運行。
為了優化效能,建議考慮控制並行度。 對於大型資料集,您可能需要限制同時執行的執行緒數量以防止系統過載。
var options = new ExecutionDataflowBlockOptions
{
MaxDegreeOfParallelism = 4
};var options = new ExecutionDataflowBlockOptions
{
MaxDegreeOfParallelism = 4
};Dim options = New ExecutionDataflowBlockOptions With {.MaxDegreeOfParallelism = 4}在處理大量 PDF 時,要注意記憶體的使用。 儘快釋放像 PdfDocument 這樣的資源,一旦它們不再需要。
擴充方法是一種特殊的靜態方法,它允許您在不修改源代碼的情況下為現有類型添加新功能。 這在使用像 IronPDF 這樣的庫時非常有用,您可能希望添加自訂處理方法或擴展其功能,以便在 PDF 上的操作更為便利,特別是在並行處理場景中。
通過使用擴充方法,您可以創建簡潔、可重用的代碼,從而簡化並行迴圈中的邏輯。 此方法不僅能減少重複,還有助於在處理複雜的 PDF 工作流和資料平行處理時維持乾淨的代碼庫。
使用平行迴圈,例如 Parallel.ForEach 與IronPDF在處理大量 PDF 文件時提供顯著的性能提升。 無論是將 HTML 轉換為 PDF、提取文本,還是操作文件,數據並行性都可以通過同時運行任務來實現更快的執行。 平行方法確保操作可以在多個核心處理器上執行,這就減少了整體執行時間並提高了批量處理任務的性能。
雖然並行處理可以加快任務速度,但要注意執行緒安全和資源管理。 IronPDF 在大多數操作中是執行緒安全的,但當訪問共享資源時,處理潛在的衝突很重要。 考慮錯誤處理和記憶體管理以確保穩定性,尤其是在您的應用程式擴展時。
如果您準備好深入了解IronPDF並探索進階功能,這 官方文件,讓您能在自己的專案中測試該庫,然後再決定是否購買。
不需要信用卡
您的試用金鑰應已發送至您的電子郵件。![]() 試用表格已
試用表格已
成功提交。
如果沒有收到,請聯絡
support@ironsoftware.com
免費開始
不需要信用卡
在生產環境中測試,無水印。
在任何需要的地方都能運行。
獲得 30 天的全功能產品。
在幾分鐘內上手運行。
試用產品期間完全訪問我們的支援工程團隊





預約30分鐘的個人演示。
無合約,無卡片信息,無承諾。

