
在實際環境中測試
在生產環境中測試,無水印。
在任何需要的地方都能運行。
C# PDF 庫
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


在數位文件管理的動態環境中,能夠輕鬆地從PDF文件中提取數據是一項基礎任務,支撐著多種應用程序。 提取文本的過程對於全面數據分析、內容索引、商業用途和文本處理等目的至關重要。 在眾多可用工具中,iTextSharp 作為一個備受推崇的 C# 庫,成為從 PDF 文件中提取文本的卓越解決方案。
在這篇綜合文章中,我們將深入探索使用 iTextSharp 的豐富功能,探討這個強大且多功能的解析庫如何使開發人員能夠使用 C# 程式語言高效地從 PDF 文件中提取文本內容。 我們將揭示關鍵的方法、範例技術和最佳實踐,為開發人員提供利用iTextSharp進行文本提取所需的知識。 我們還將在這篇文章中討論並比較最好的和最強大的 PDF 函式庫 IronPDF。
下載用於從 PDF 提取文本的 C# 程式庫。
透過實例化PdfReader物件來載入現有的PDF。
使用GetTextFromPage方法從PdfDocument物件中提取文本。
實例化foreach循環以迭代這些行。
WriteLine方法將這些行寫入文件。IronPDF概述,這是一個在.NET開發領域中具有顯著功能的豐富庫,徹底改變了PDF的生成和操作。 為開發者提供全面的工具套件,IronPDF 促進在 C# 應用程式中的無縫整合,允許輕鬆創建、修改和渲染 PDF 文件。 憑藉直觀的 API 和強大的功能,此多功能庫為從 HTML、圖片和內容生成高品質 PDF 打開了無限可能的世界。 在本文中,我們將探討IronPDF的功能,深入研究其主要特性,並演示如何利用它來有效處理C#中的PDF相關任務。
iTextSharp,一個在使用 C# 操作 PDF 的領域中著名且強大的函式庫,已徹底改變了開發者處理 PDF 文件的方式。 它是一個多功能且強大的工具,用於創建、修改和提取 PDF 文件中的內容。 iTextSharp 為開發人員提供生成高級 PDF、提取圖像、操作現有文件和提取數據的功能,使其成為廣泛應用程序的首選解決方案。 在本文中,我們將深入探討 iTextSharp 的功能和特性,探索如何在 C# 編程環境中有效地使用它來管理和操作 PDF。
安裝 IronPDF 是一個簡單的過程,以下是在您的 C# 項目中安裝和整合 IronPDF 的步驟。
打開 Visual Studio,建立一個新專案或開啟現有專案。
前往工具並從下拉選單中選擇NuGet套件管理員。
在新的側邊選單中,選擇方案的 NuGet 封裝管理器。
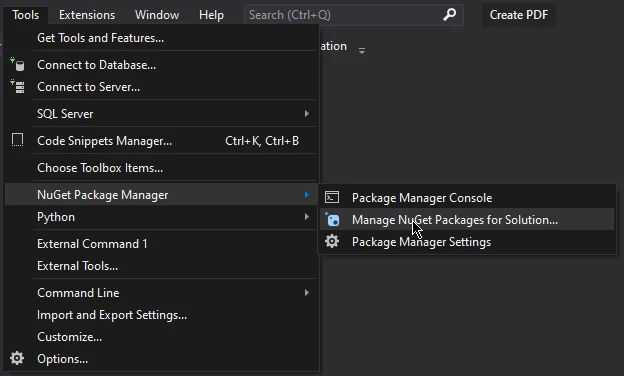
在「NuGet 套件管理員」視窗中,選擇「瀏覽」標籤。
在搜索欄中輸入 "IronPDF" 並按 Enter。
IronPDF 實例列表將出現,選擇最新版本並按下安裝。
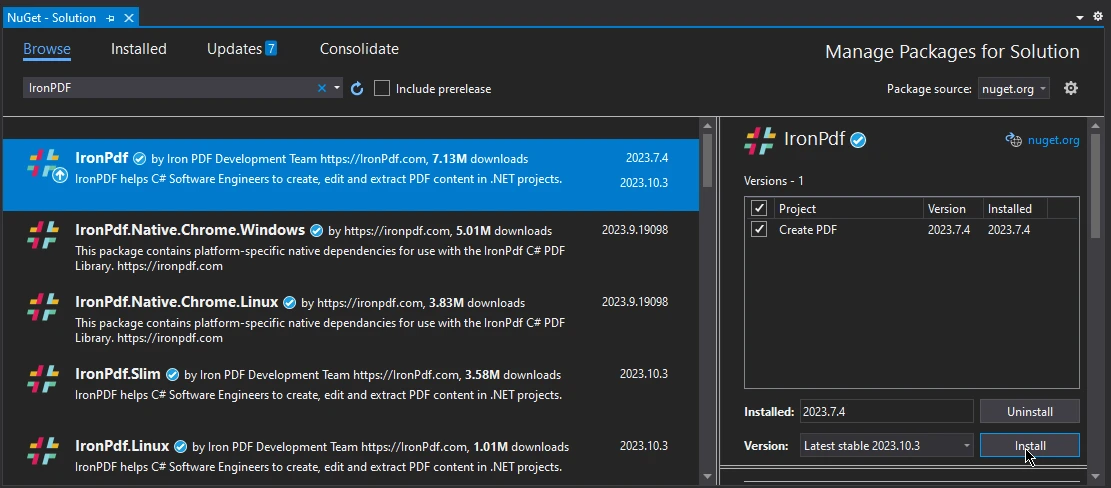
就這樣,IronPDF 安裝完畢,可以在你的 C# 專案中使用了。
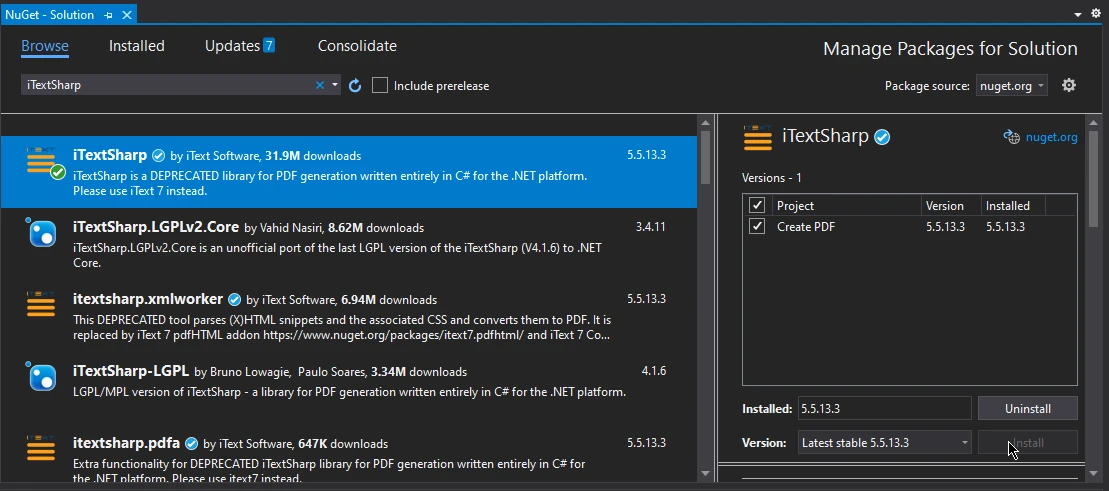
安裝 iTextSharp PDF 庫與安裝 IronPDF 是相同的。 重複以上所有步驟,只需在瀏覽視窗中搜尋「iTextSharp」而非IronPDF,從套件列表中選擇並點擊安裝,即可在您的專案中整合iTextSharp PDF庫。
IronPDF 提供從 PDF 檔案中提取文本的功能,可以根據特定頁面自動提取文本或從所有 PDF 中提取文本。 在下面的程式碼範例中,我們將看到如何從範例 PDF 文件的特定頁面中提取文字。
using IronPdf;
using System;
using PdfDocument PDF = PdfDocument.FromFile("Watermarked.pdf");
string Text = PDF.ExtractTextFromPage(1);
Console.Write(Text);using IronPdf;
using System;
using PdfDocument PDF = PdfDocument.FromFile("Watermarked.pdf");
string Text = PDF.ExtractTextFromPage(1);
Console.Write(Text);Imports IronPdf
Imports System
Private PdfDocument As using
Private Text As String = PDF.ExtractTextFromPage(1)
Console.Write(Text)上面的程式碼使用 IronPDF 庫在 C# 中從 PDF 檔案中提取文字並在控制台中顯示。 首先,導入必要的命名空間,包括 IronPDF 和 System。 然後程式碼使用FromFile方法將標題為「Watermarked.pdf」的 PDF 文件載入PdfDocument物件中。 隨後,它使用ExtractTextFromPage從 PDF 的第二頁提取文本,並將其存儲在名為 Text 的字串變數中。 最後,提取的文本使用Console.Write在控制台中顯示。

您也可以使用iTextSharp從PDF文件中提取文本,以下是一個iTextSharp庫的使用範例。
using System;
using System.Text;
using iTextSharp.text.pdf;
using iTextSharp.text.pdf.parser;
namespace PDFApp2
{
class Program
{
static void Main(string [] args)
{
string filePath = @"C:\Users\buttw\OneDrive\Desktop\highlighted PDF.pdf";
string outPath = @"C:\Users\buttw\OneDrive\Desktop\name.txt";
int pagesToScan = 2;
string strText = string.Empty;
try
{
PdfReader reader = new PdfReader(filePath);
for (int page = 1; page <= pagesToScan; page++)
{
ITextExtractionStrategy its = new iTextSharp.text.pdf.parser.LocationTextExtractionStrategy();
strText = PdfTextExtractor.GetTextFromPage(reader, page, its);
strText = Encoding.UTF8.GetString(ASCIIEncoding.Convert(Encoding.Default, Encoding.UTF8, Encoding.Default.GetBytes(strText)));
string [] lines = strText.Split('\n');
foreach (string line in lines)
{
using (System.IO.StreamWriter file = new System.IO.StreamWriter(outPath, true))
{
file.WriteLine(line);
}
}
}
reader.Close();
}
catch (Exception ex)
{
Console.Write(ex);
}
}
}
}using System;
using System.Text;
using iTextSharp.text.pdf;
using iTextSharp.text.pdf.parser;
namespace PDFApp2
{
class Program
{
static void Main(string [] args)
{
string filePath = @"C:\Users\buttw\OneDrive\Desktop\highlighted PDF.pdf";
string outPath = @"C:\Users\buttw\OneDrive\Desktop\name.txt";
int pagesToScan = 2;
string strText = string.Empty;
try
{
PdfReader reader = new PdfReader(filePath);
for (int page = 1; page <= pagesToScan; page++)
{
ITextExtractionStrategy its = new iTextSharp.text.pdf.parser.LocationTextExtractionStrategy();
strText = PdfTextExtractor.GetTextFromPage(reader, page, its);
strText = Encoding.UTF8.GetString(ASCIIEncoding.Convert(Encoding.Default, Encoding.UTF8, Encoding.Default.GetBytes(strText)));
string [] lines = strText.Split('\n');
foreach (string line in lines)
{
using (System.IO.StreamWriter file = new System.IO.StreamWriter(outPath, true))
{
file.WriteLine(line);
}
}
}
reader.Close();
}
catch (Exception ex)
{
Console.Write(ex);
}
}
}
}Imports Microsoft.VisualBasic
Imports System
Imports System.Text
Imports iTextSharp.text.pdf
Imports iTextSharp.text.pdf.parser
Namespace PDFApp2
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim filePath As String = "C:\Users\buttw\OneDrive\Desktop\highlighted PDF.pdf"
Dim outPath As String = "C:\Users\buttw\OneDrive\Desktop\name.txt"
Dim pagesToScan As Integer = 2
Dim strText As String = String.Empty
Try
Dim reader As New PdfReader(filePath)
For page As Integer = 1 To pagesToScan
Dim its As ITextExtractionStrategy = New iTextSharp.text.pdf.parser.LocationTextExtractionStrategy()
strText = PdfTextExtractor.GetTextFromPage(reader, page, its)
strText = Encoding.UTF8.GetString(ASCIIEncoding.Convert(Encoding.Default, Encoding.UTF8, Encoding.Default.GetBytes(strText)))
Dim lines() As String = strText.Split(ControlChars.Lf)
For Each line As String In lines
Using file As New System.IO.StreamWriter(outPath, True)
file.WriteLine(line)
End Using
Next line
Next page
reader.Close()
Catch ex As Exception
Console.Write(ex)
End Try
End Sub
End Class
End Namespace所提供的程式是使用 iTextSharp 函式庫的 C# 程式,用於從 PDF 檔案的特定頁面提取文字,並將其保存到文字檔案。首先,引入了必要的名稱空間,包括 System.Text、iTextSharp.text.pdf 和 iTextSharp.text.pdf.parser。 該程式指定檔案名稱、輸入 PDF 檔案路徑、輸出文字檔案路徑,以及要掃描的頁數。 然後,它使用 iTextSharp 的 PdfReader 來讀取 PDF 文件。對於每個指定頁面,它使用 iTextSharp 的新 LocationTextExtractionStrategy 來提取文本,並將編碼轉換為 UTF-8。提取的文本被分割成多行,並且新的 StringBuilder 從 PDF 代碼中生成的文本按正確的方向工作。 在過程中遇到的任何例外情況都會被捕獲並顯示在控制台中。 該程式最後透過關閉PdfReader來結束。
在 C# 中使用 iTextSharp 提取 PDF 文本 VS IronPDF 圖5 - 使用 iTextSharp 提取文本
iTextSharp,是一個功能強大且多用途的 C# 庫,革新了 PDF 操作,實現了無縫的內容創建、修改和提取。 其強大的功能使其成為開發人員的首選解決方案,使他們能夠生成複雜的PDF並有效管理PDF內的文本內容。 此外,IronPDF 是 .NET 領域的另一個重要庫,提供了一套完整的工具來進行 PDF 生成和圖像處理,增強了開發人員能夠輕鬆從各種來源創建、修改和呈現高品質 PDF 的能力。 在比較這兩個 PDF 庫時,由於 IronPDF 擁有完善的文檔和易於使用的 API,因此佔據了領先地位。它只需幾行代碼就能完成所有文本提取,而使用 iTextSharp 則需要撰寫冗長且複雜的代碼,並需要對該庫和 C# 有深入的了解。
欲了解更多關於IronPDF 的功能及其特色,請訪問官方網頁。 完整的 IronPDF 提取文本教學可在這裡找到:IronPDF 教學課程:從 PDF 提取文本。 有關 IronPDF 和 iTextSharp 的完整教程,請訪問IronPDF 與 iTextSharp 比較。
不需要信用卡
您的試用金鑰應已發送至您的電子郵件。![]() 試用表格已
試用表格已
成功提交。
如果沒有收到,請聯絡
support@ironsoftware.com
免費開始
不需要信用卡
在生產環境中測試,無水印。
在任何需要的地方都能運行。
獲得 30 天的全功能產品。
在幾分鐘內上手運行。
試用產品期間完全訪問我們的支援工程團隊





預約30分鐘的個人演示。
無合約,無卡片信息,無承諾。

