Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The Python PDF Library


This article will demonstrate how to extract all the text from PDF files using IronPDF in Python, and provide you with the knowledge and the Python code snippets to accomplish this task efficiently.
FromFile method to import the PDF fileExtractText methodExtractTextFromPage methodIronPDF for Python is a powerful Python PDF library that allows developers to extract text from PDF documents. With IronPDF, you can automate the data extraction part of textual content from PDF files, making it easier to process data from and analyze the information contained within PDF documents.
IronPDF provides Python programmers with the ability to manipulate, extract data from, and interact with PDF files using Python, making it easier to automate various PDF-related tasks. Whether you need to generate PDFs, modify existing PDFs, extract data from content extracting images, or perform other PDF operations, IronPDF simplifies the process with its intuitive API and powerful capabilities.
Some features of the IronPDF for Python library include:
Before proceeding with text extraction using IronPDF, ensure that you have the following prerequisites in place:
IronPDF Library: Install the IronPDF library using pip, the Python package manager. Open your command-line interface and execute the following command:
pip install ironpdf
Note: Python must be added to the PATH environment variable, in order to use pip commands.
After installing PyCharm IDE, create a PyCharm Python project by following the below steps:
Create a New Project: Click on "Create New Project" or Open an existing Python project.
 PyCharm IDE
PyCharm IDE
Configure Project Settings: Provide a name for your project and choose the location to create the project directory. Select the Python interpreter for your project. Then click "Create".
 Create a new Python project in Pycharm
Create a new Python project in Pycharm
Now let's dive into the steps involved in extracting plain text from PDF files using IronPDF in Python programming language.
To begin, import the necessary libraries in your Python script. In this case, the code sample needs to import the IronPDF library, which provides the functionality for working with PDF files.
import ironpdfIn order to extract full text from a PDF file using IronPDF, we need to have IronPDF licensed. Apply the license or trial key using the following command:
# Apply your license key
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"Note: Without a license key, IronPDF extracting data is restricted to a few characters only from the PDF extension file. Obtain a license key by purchasing IronPDF or by signing up for a free trial.
Next, load the PDF file using the document using the PdfDocument.FromFile() method from IronPDF. Provide the path to the PDF file as the argument to this method. This will load the PDF file into a PdfDocument object.
pdf = ironpdf.PdfDocument.FromFile("path/to/your/pdf_file.pdf")To extract text from the input PDF file and print it on the screen, the following document is used:
 The input file
The input file
Once the PDF document is loaded, you can extract the text content using the ExtractText method. This method returns the extracted text as a string.
text = pdf.ExtractText()Now that you have extracted the text from the PDF, you can process and utilize it according to your requirements. You can perform tasks such as parsing the text, analyzing it, storing it in a database, or using it for further data processing.
# Process and utilize the extracted text
print(text)
# Perform other operations with the extracted text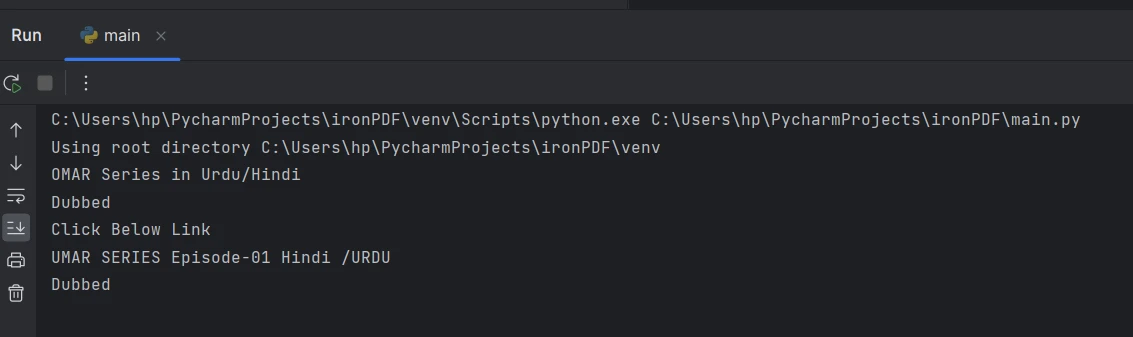 The extracted text from the console
The extracted text from the console
IronPDF also provides a convenient method to extract text from specific pages within a PDF file. This section will explore how to extract text from a specific page using the ExtractTextFromPage method provided by IronPDF.
The following code demonstrates how to extract text from a specific page:
# Extract text from specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)In the above sample code, pdf represents the PdfDocument object obtained after loading the PDF document. The ExtractTextFromPage() method is used to extract text from a specific page when reading PDFs, indicated by the page index passed as an argument. In this case, the text is extracted from the second page or page number 2, which corresponds to page index 1.
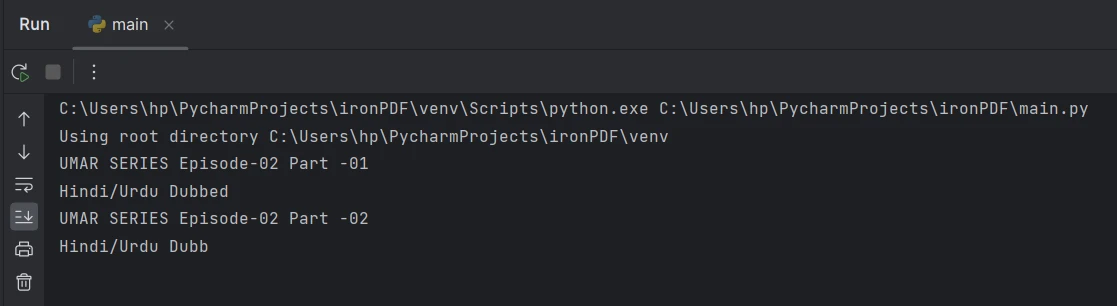 Extract text from page 2
Extract text from page 2
This article explored how to extract text from PDF files using IronPDF in Python. It covered the necessary steps, including importing the required library or libraries, loading the PDF document, extracting the text content, and processing the extracted text.
With IronPDF's powerful text extraction capabilities, you can automate the extraction and further processing of text from PDFs, enabling you to process and analyze the textual information within PDF documents easily. Its intuitive API and extensive capabilities make it an ideal choice for a wide range of PDF-related tasks in Python development.
IronPDF is free for development purposes, but it needs to be licensed for commercial use. To use it in production mode for testing, obtain a free trial. Download and install the latest version of IronPDF for Python and give it a try.

pip install ironpdf-2025.4-py37-none-win_amd64.whiNo credit card required
Your trial key should be in the email.![]() The trial form was submitted
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
No credit card required

Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial





![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.

Book a 30-minute, personal demo.
No contract, no card details, no commitments.


10 .NET API products for your office documents