Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The Python PDF Library


In the era of digital transformation, the indispensability of PDF documents for sharing and preserving information cannot be overstated.
However, the prevalence of scanned PDFs, which often contain images rather than searchable text, presents a significant challenge when it comes to extracting valuable data.
This is where Python emerges as a versatile and potent solution, establishing itself as a go-to programming language for automating diverse tasks, with information extraction from scanned documents being a prime example.
Python's flexibility and robust capabilities empower users to efficiently navigate through the complexities of scanned content, providing a streamlined approach to accessing and utilizing data from image-based PDFs.
Python is one of the most used programming languages with its advanced functionality, visit the Python Wikipedia page to learn about Python programming language and its structured format.
In this article, we will discuss how to read scanned PDFs in Python Programming Language with the help of IronPDF for Python PDF Library.
IronPDF for Python is a robust library developed by Iron Software, enabling seamless integration of PDF generation and manipulation capabilities into Python applications.
This versatile tool empowers developers to effortlessly create, modify, and interact with PDF documents, supporting tasks such as dynamic report generation, HTML-to-PDF conversion, and content extraction from existing PDF files.
With a user-friendly API, comprehensive documentation, and a range of features, IronPDF simplifies the process of incorporating advanced PDF functionality into Python projects, making it an invaluable resource for developers looking to enhance their applications with professional-grade document natural language processing capabilities.
IronPDF for Python comes equipped with a range of features that make it a powerful tool for PDF generation and text file structure manipulation.
Some of its key features include:
Before getting started with the code tutorial first let's see how you can Install IronPDF for Python.
First, make sure Python is installed in the system, and you have a good Python compiler in hand like PyCharm, also PIP should be installed to install IronPDF for Python.
First, create a new Python Project or open an existing one.
pip install ironpdf
In this section, we will see how you can extract text from scanned PDF files using IronPDF.
from ironpdf import * License.LicenseKey = " Your License Ket "
# Load Scanned PDF document
pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")
# Extract text from PDF document
all_text = pdf.ExtractAllText()
print(all_text)The above code example extracts text from scanned PDF files. below is the breakdown of the above code.
Import the IronPDF Module:
from ironpdf import *This line imports the necessary modules and classes from the IronPDF library. The asterisk (*) indicates that all classes and functions from the module should be imported.
Set the License Key:
License.LicenseKey = " Your License Key "This line sets the license key for IronPDF. You need to replace "Your License Key" with the actual license key you obtained from Iron Software.
The license key is necessary for using IronPDF and is typically provided when you purchase the product.
Load a Scanned PDF Document:
pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")This line loads a scanned PDF document located at the specified file path ("C:/Users/buttw/INV_2023_00008.pdf"). The PdfDocument.FromFile method is used to create a PdfDocument object from the given file.
Extract Text from PDF Document:
all_text = pdf.ExtractAllText()This line extracts all text content from the loaded PDF document using the ExtractAllText method from all the pages. The extracting text is then stored in the all_text variable.
Print Extracted Text:
print(all_text)Finally, this line prints the extracted text to the console. The all_text variable contains the text content of the scanned PDF document.
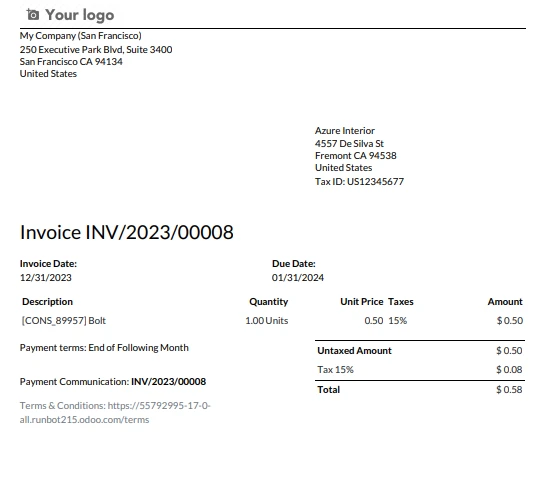
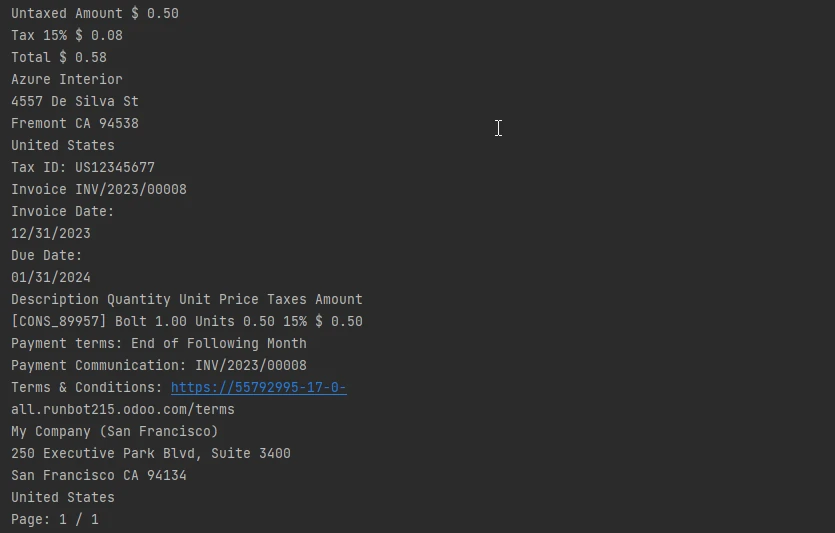
In the realm of digital document processing, the Python programming language emerges as a versatile solution for overcoming the challenges posed by scanned PDFs containing images instead of searchable text.
The synergy between Python's flexibility and IronPDF for Python's robust capabilities provides a compelling avenue for developers to seamlessly integrate PDF generation, manipulation, and extraction functionalities into their projects.
IronPDF, developed by Iron Software, proves instrumental in this regard, offering features like converting PDF files from various document types, HTML to PDF page conversion, text and image manipulation, and OCR-based text extraction from scanned PDFs.
The showcased code example demonstrates the straightforward implementation of IronPDF to read text from a scanned PDF page, showcasing the potential for efficient data extraction and enhancing document processing capabilities in Python applications.
As the demand for sophisticated PDF handling continues to rise, IronPDF for Python stands as a valuable tool empowering developers to navigate the intricacies of scanned content with ease.
IronPDF for Python offers a trial license for developers which is a great opportunity to get to know the features of IronPDF.
The complete tutorial on extracting text from scanned PDFs can be found here.

pip install ironpdf-2025.4-py37-none-win_amd64.whiNo credit card required
Your trial key should be in the email.![]() The trial form was submitted
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
No credit card required

Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial





![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.

Book a 30-minute, personal demo.
No contract, no card details, no commitments.


10 .NET API products for your office documents