Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The Python PDF Library


This article will demonstrate how to extract text elements from PDF documents with the help of the IronPDF for Python library.
Python is a programming language that makes it simple and quick for developers to create graphical user interfaces. Compared to other languages, Python is also much more dynamic for programmers. Because of this, adding the IronPDF library to Python is a simple process. A multitude of pre-installed tools, including PyQt, wxWidgets, Kivy, and many additional packages and Python libraries, can be used to rapidly and securely build a fully complete GUI. IronPDF incorporates Python and also allows integration of features from other frameworks, such as .NET Core.
IronPDF makes web development easier. The main reason for this is the widespread adoption of Python web development paradigms like Django, Flask, and Pyramid. Reddit, Mozilla, and Spotify are just a few of the websites and online services that have used these frameworks.
Make sure Python is set up on your computer. To download and install the most recent version of Python compatible with your operating system, go to the official Python website. Create a virtual environment once Python is installed to separate the needs for your project. Create and manage virtual environments with the venv module to give your conversion project a tidy, separate workplace.
For this demonstration, PyCharm is recommended as an IDE for developing Python code.
After starting the PyCharm IDE, select "New Project".
 PyCharm
PyCharm
A new window will open when you choose "New Project", allowing you to set the project's location and environment. This might be seen in the image below.
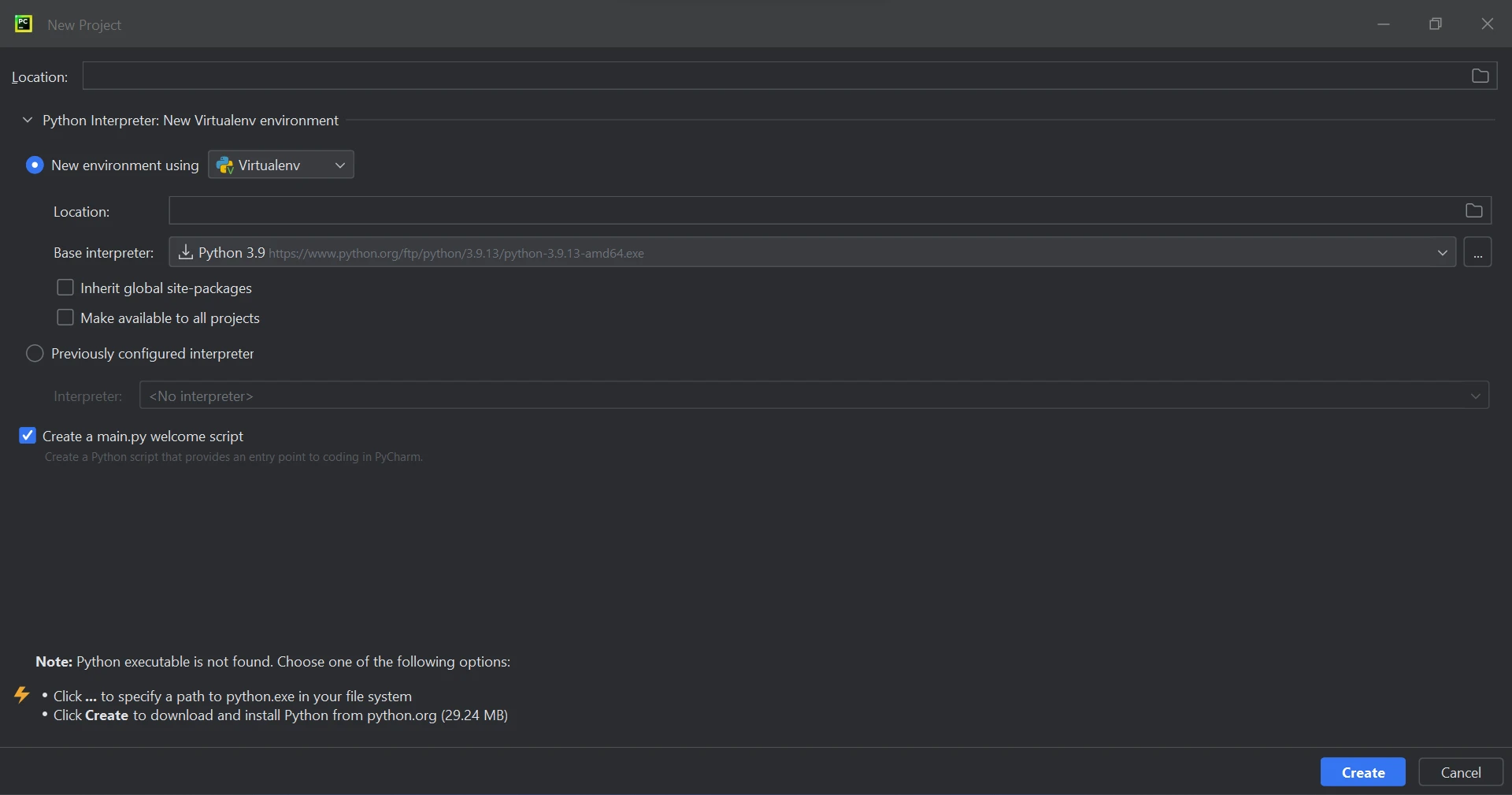 New Project
New Project
After choosing the project location and environment path, click the Create button to begin a new project. The program can then be created in a new window that will open as a result. For this lesson, Python 3.9 is being used.
 Create Python Project
Create Python Project
The Python library IronPDF largely uses .NET 6.0. As a result, the .NET 6.0 runtime must be installed on your computer in order to use IronPDF for Python. It might be necessary to install .NET before this Python module can be used by Linux and Mac users. Visit this download page from Microsoft to get the needed runtime environment.
To generate, modify, and open files with the ".pdf" extension, the "ironpdf" package must be installed. Open a terminal window and enter the following command to install the package in PyCharm:
:PackageInstallThe installation of the ironpdf package is shown in the screenshot below.
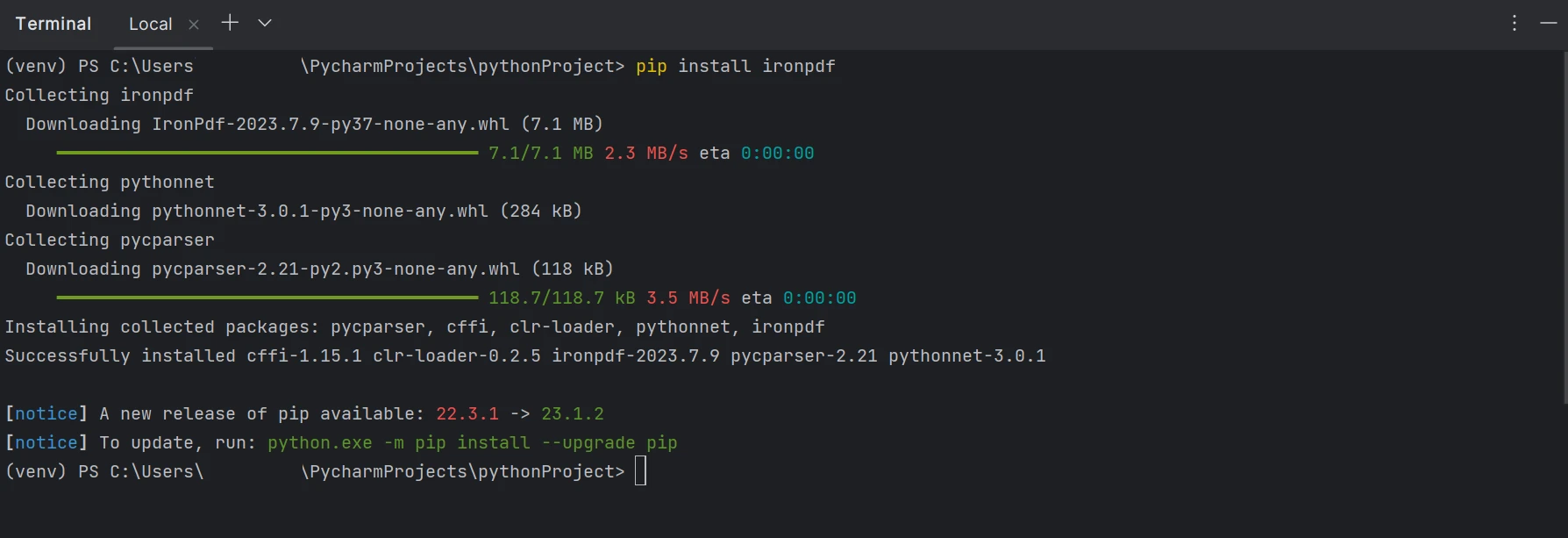 Install IronPDF
Install IronPDF
It is possible to extract text from PDF files with the help of the IronPDF libraries. IronPDF offers a number of text extraction methods. The first method entails retrieving the entire page's content as a single string. The second strategy entails going over the content page by page, beginning with the first page. Existing PDF files can be investigated using the IronPDF library. The snippet of code that follows shows how to use IronPDF to inspect live PDF files.
There are two options for extracting information from a PDF:
Here is the sample PDF file for this article is available below.
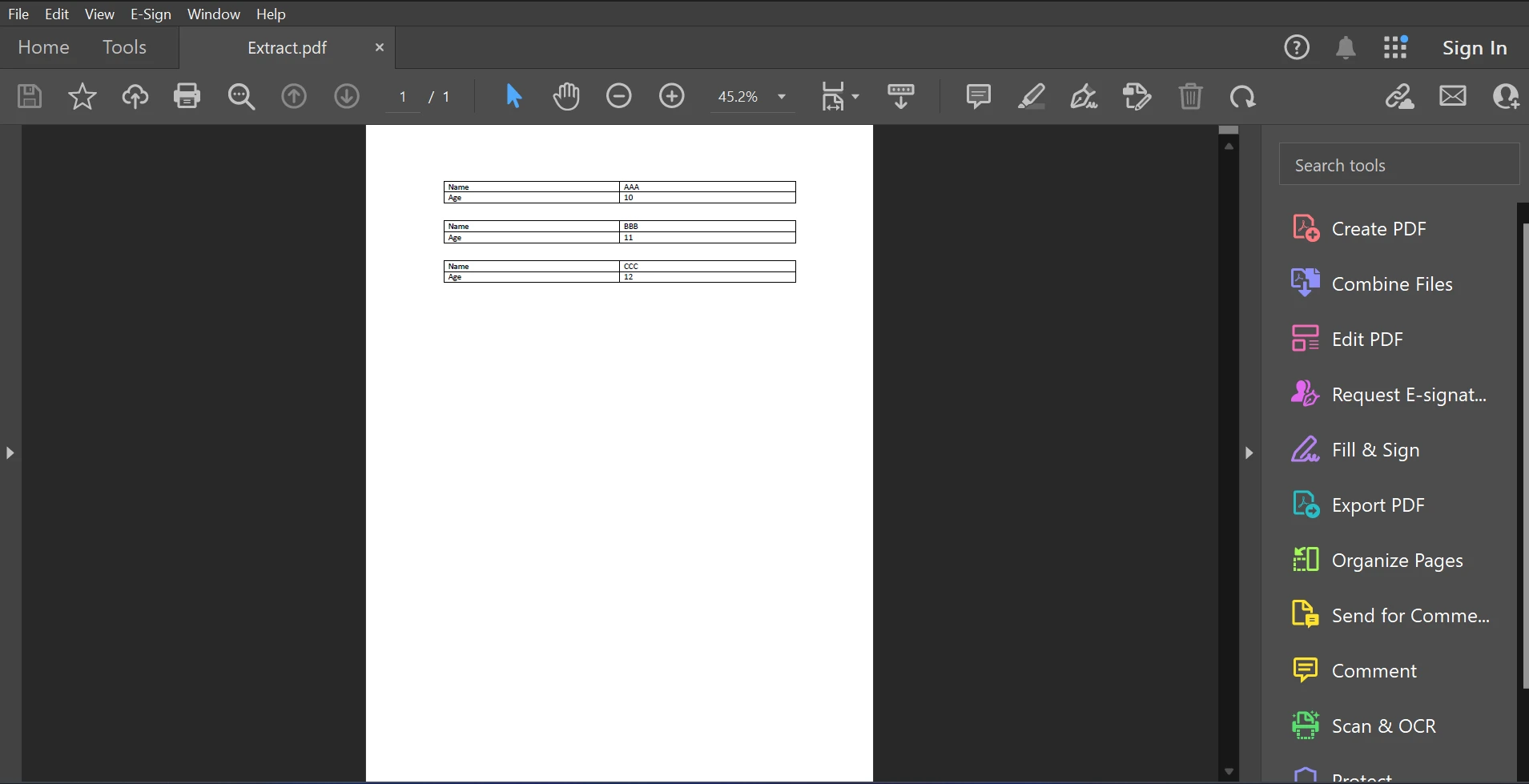 Input PDF
Input PDF
The example code supplied below shows how to obtain data from a PDF file using the page number.
from ironpdf import *
# PDF object
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract text from PDF document
all_text = pdf.ExtractTextFromPage(0)
for _data in all_text.split('\n'):
if('Name' in _data):
print(_data)The code snippet shows how to read a PDF file and build a PDF object using the FromFile function. This object can be used to access the PDF's text and images. By passing the page number as a parameter to the ExtractTextFromPage function, the text can be retrieved from a specific page. A string containing all the words on the chosen page will be returned by this method. Then, use the split function in Python to split all the new lines from the extracted text. After that, check whether each line in the extracted text contains the required keywords. If the keyword matches, it will display the specific line in the command prompt. Otherwise, it will ignore that line and move on to the next line. The output for text extraction will appear as shown below.
The following code sample demonstrates the first method for quickly and simply getting all the PDF content as a string.
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extracting texts from PDF document
all_text = pdf.ExtractAllText()
for _data in all_text.split('\n'):
if('Name' in _data):
print(_data)The example code above demonstrates how to use the FromFile function to read a PDF from an existing file path and convert it into a PDF file object. As a result, we can use this PDF reader object to see the text and images in the PDF. The object's ExtractAllText function will be used to extract data from PDF into plain text, convert it to a string, and use the similar logic like the above to find the specific keyword to display the result in the terminal. Results are displayed as follows.
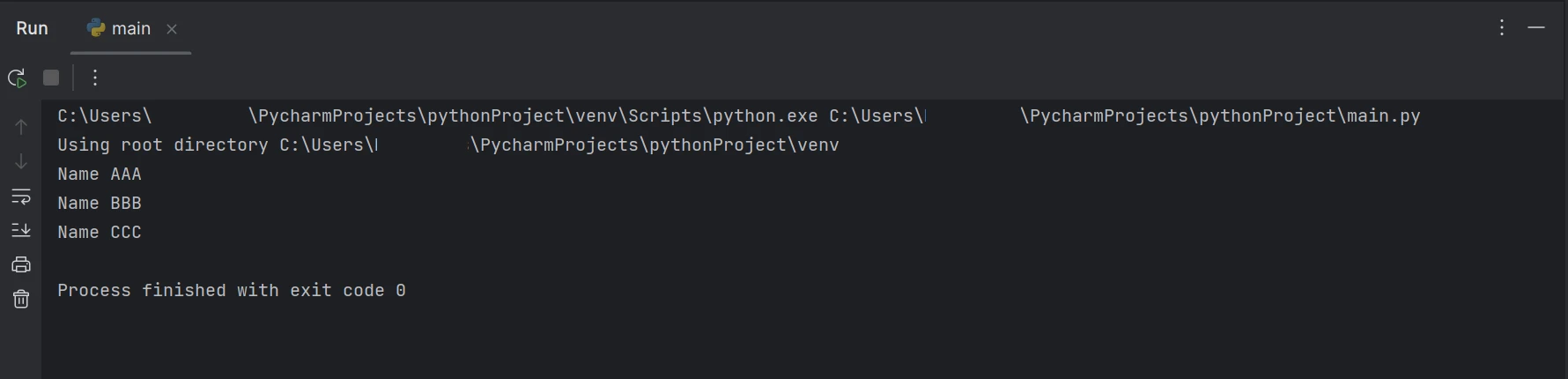 Output
Output
The above code/output shows that the given PDF document contains both the name and age, but the result shows only the name available in the PDF document.
Strong security mechanisms are offered by the IronPDF library to reduce threats and guarantee data safety. It is not restricted to any one browser and is compatible with all widely used ones. With just a few lines of code, programmers can quickly produce and read PDF files using IronPDF. The IronPDF library offers a range of licensing options, including a free developer license and extra development licenses that are available for purchase, to meet the diverse demands of developers.
A perpetual license, a 30-day money-back guarantee, a year of software maintenance, and upgrade options are included in the Lite package. These licenses can be used in all environments. Additionally, IronPDF provides free licenses with some redistribution restrictions. A trial license allows users to evaluate the product without a watermark.
Please view the available IronPDF Licenses for more information about commercial licensing.

pip install ironpdf-2025.4-py37-none-win_amd64.whiNo credit card required
Your trial key should be in the email.![]() The trial form was submitted
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
No credit card required

Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial





![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.

Book a 30-minute, personal demo.
No contract, no card details, no commitments.


10 .NET API products for your office documents