Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The Python PDF Library


PDF (Portable Document Format) is the most popular file format for transferring data over the internet, as it preserves content formatting and helps secure the data with security permissions. There are scenarios where we need to convert PDF files to JPG images or any other image format such as PNG, BMP, TIFF, or GIF. There are plenty of online resources available for JPG conversion, but how cool would it be to create our own PDF to Image conversion tool in Python?
Python is a high-level programming language that is used to build software applications, websites, automate tasks, conduct data analysis, and perform Artificial Intelligence and Machine Learning tasks. It is also a scripting language as it is interpreted, which makes it more powerful in terms of rapid development and testing.
To create a PDF to image converter, we need to have Python 3+ installed on the computer. Download and install the latest version from the official website.
In this article, we will create our own image conversion application using Python PDF to image libraries. For this purpose, we will be using two of Python's most popular libraries: PDF2Image and PyMuPDF.
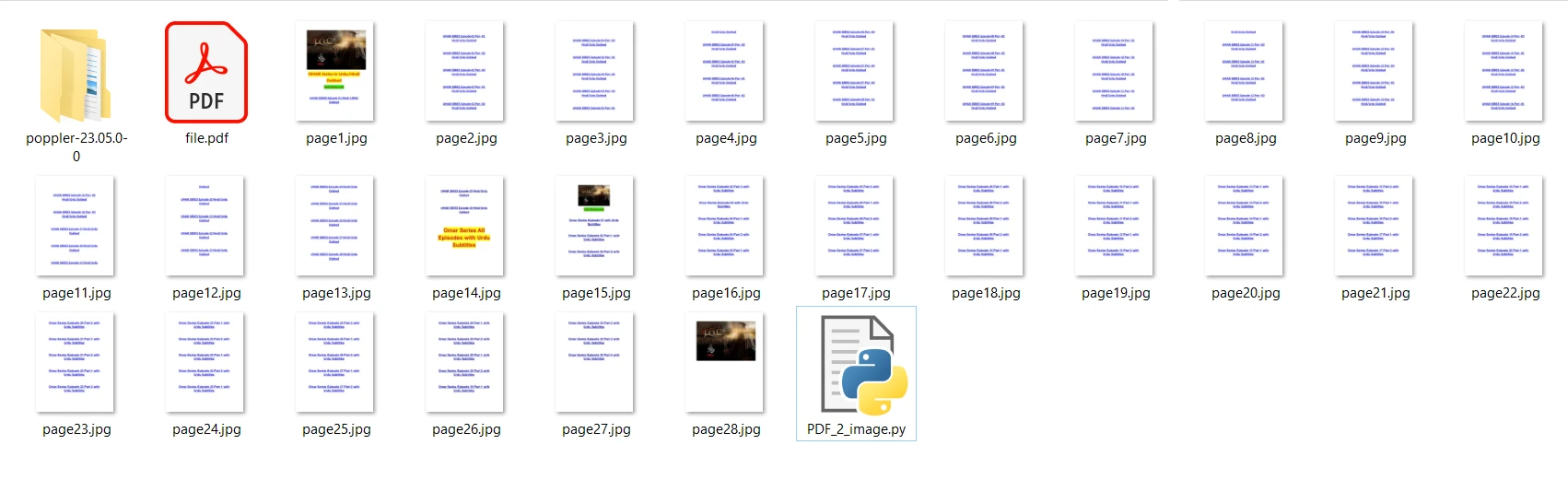
The input PDF file which we are going to use contains 28 pages and is as follows:

PDF2Image is a module that wraps pdftocairo and pdftoppm. It works on Python 3.7+ to convert PDF to a PIL image object. Its previous release history shows that it only wraps pdftoppm to convert PDF to images and worked only on Python 3+.
To install the pdf2image package, open your Windows command prompt or Windows PowerShell and use the following pip command:
pip install pdf2imagePip (Preferred Installer Program) is the package manager for Python. It downloads and installs third-party software packages that offer features and functionality not found in the Python standard library.
Note: To execute this command from anywhere on the command line, Python must be added to the PATH. For Python 3+, it is recommended to use pip3 as it is the updated version of pip.
Poppler is a free and open-source library for working with PDF files. It is used to render PDF files, read content, and modify the content within PDF files. It is commonly used by Linux users. However, for Windows, we will need to download the latest version of Poppler.
Windows users can download the latest up-to-date version of Poppler here: @oschwartz10612 version. You will then have to add the bin/folder to the PATH Environment variable.
Mac users will also have to install Poppler. It can be installed using Brew:
brew install popplerMost Linux distributions come with the pdftoppm and pdftocairo command-line utilities. If these utilities are not installed, you can use the package manager to install poppler-utils.
conda)Install poppler:
conda install -c conda-forge poppler
Install pdf2image:
pip install pdf2image
Now everything is ready, let's start with the code to convert PDFs to images.
The following code will perform image conversion of the input PDF file:
from pdf2image import convert_from_path
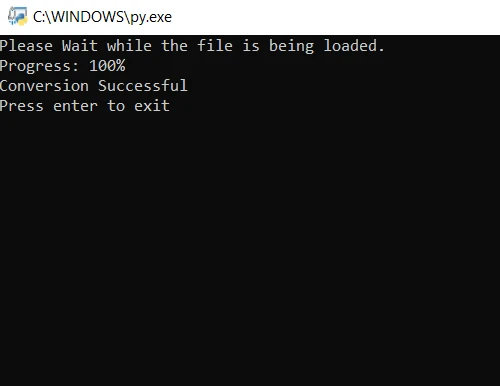
print("Please Wait while the file is being loaded.")
file = convert_from_path('file.pdf')
for i in range(len(file)):
# save pdf as jpg
print("Progress: " + str(round(i/len(file) * 100)) + "%")
file [i].save('page'+ str(i+1) +'.jpg', 'JPEG')
print("Conversion Successful")In the above code, we first open the file using the convert_from_path method. This method opens the file located at the specified path. Then, we loop through each page of the PDF file to be converted to JPG images. Finally, the save method is used to save each converted page as a JPG image file. Now, execute the program and wait for the conversion to complete.
The output image files are saved in the same folder as the program.
PyMuPDF is an extended Python binding to MuPDF, which is a lightweight e-book, PDF, and XPS viewer, renderer, and toolkit. It can be used to convert PDF to other formats like JPG or PNG. PyMuPDF works on Python 3.7+ versions.
To install the PyMuPDF package, open your Windows command prompt or Windows PowerShell and use the following pip command:
pip3 install pymupdfNote that PyMuPDF doesn't require any additional libraries as the PDF2Image package does.
The following code will import the fitz module from PyMuPDF, so we can convert the PDF to images:
import fitz
doc = fitz.open("file.pdf")
for x in range(len(doc)):
page = doc.load_page(x) # number of page
pix = page.get_pixmap()
output = "output/pdfpage"+str(x+1)+".png" # first create the output folder in the destination
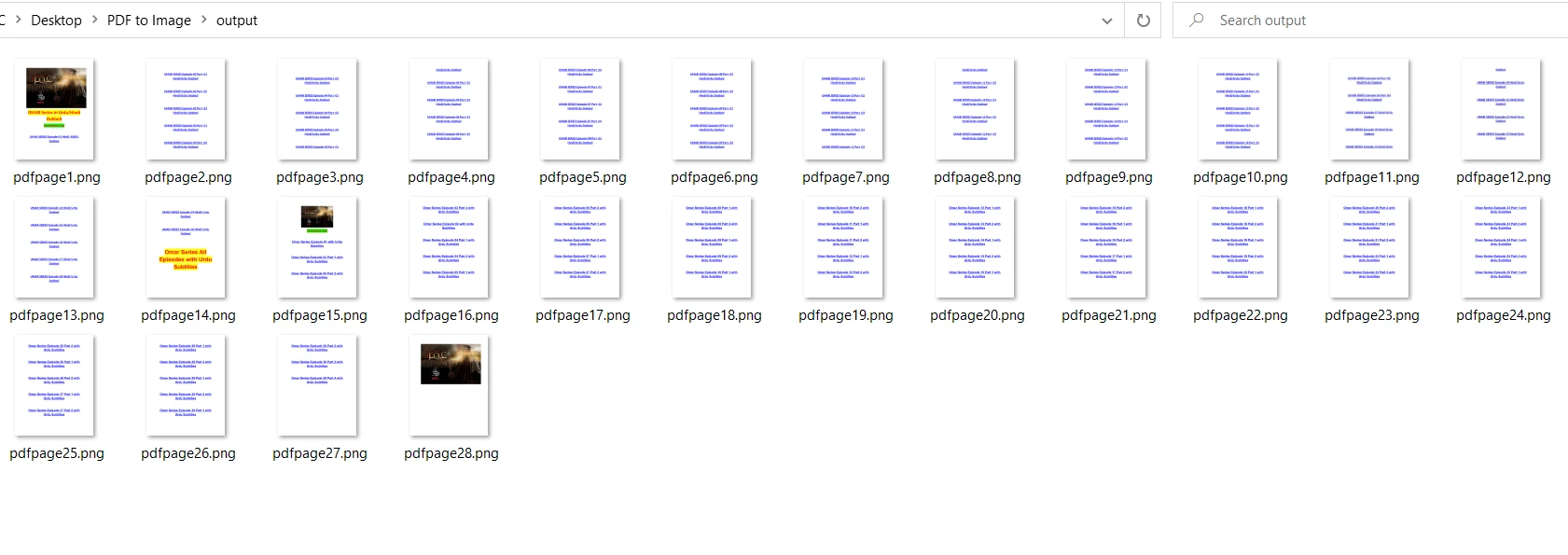
pix.save(output)
doc.close()In the above code, the filename is passed as an argument to the fitz.open method to open the file. Next, I loop through the entire document and load each page separately. The get_pixmap method is used to convert each document page to image pixels, and the resulting image is saved in the output folder using the save method. Finally, the opened document is closed to release memory.
When compared to PDF2Image, PyMuPDF is faster when converting PDF to PNG. PDF2Image can be slow for PNG format due to its compression ratio.
The output is the same as that of PDF2Image:
IronPDF is a library used to generate, read, and manipulate PDF files. Its specialty lies in rendering HTML to PDF with the help of the Chromium Engine. This feature makes it popular among developers who need to convert HTML files or URLs to PDF documents. Additionally, it provides conversion from various formats to PDF files.
You can also rasterize a PDF file to images using just two lines of code. The following code demonstrates how to convert PDFs to different image formats:
from ironpdf import *
# One or more images as a list. This example selects all JPEG images in a specific 'assets' folder.
image_files = [os.path.join("assets", f) for f in os.listdir("assets") if f.lower().endswith(('.jpg', '.jpeg'))]
directory_list = List [str]()
for i in range(len(image_files)):
directory_list.Add(image_files [i])
# Converts the images to a PDF and save it.
ImageToPdfConverter.ImageToPdf(directory_list).SaveAs("composite.pdf")
# Also see PdfDocument.RasterizeToImageFiles() method to flatten a PDF to images or thumbnails
pip install ironpdf-2025.4-py37-none-win_amd64.whiNo credit card required
Your trial key should be in the email.![]() The trial form was submitted
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
No credit card required

Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial





![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.

Book a 30-minute, personal demo.
No contract, no card details, no commitments.


10 .NET API products for your office documents