Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The Python PDF Library


XGBoost stands for eXtreme Gradient Boosting, a powerful and accurate machine-learning algorithm. It has been primarily applied in regression analysis, classification, and ranking problems. It involves features like regulation that help avoid overfitting, parallelism, and missing data processing.
IronPDF is a Python library for creating, modifying, and reading PDF files. It makes it easy to convert HTML, images, or text into PDFs, and it can also add headers, footers, and watermarks. Although primarily concerned with its use in Python, it is noteworthy that the NET tool can be implemented in this programming language with the help of interoperability tools such as Python.
The combination of XGBoost and IronPDF provides broader applications. Through IronPDF, the forecasting outcome can be combined with creating interactive PDF documents. This combination is especially helpful in generating precise corporate documents and figures and the results obtained from the applied predictive models.
XGBoost is a powerful machine-learning library for Python based on ensemble learning, which is highly efficient and flexible. XGBoost is an implementation of a gradient gradient-boosting algorithm by Tianqi Chen that includes additional optimizations. The effectiveness has been proved in many application domains with corresponding tasks that can be solved by this method, such as classification, regression, ranking tasks, etc. XGBoost has several unique features: The absence of missing values is not a problem for it; There is an opportunity to use L1 and L2 norms to fight against overfitting;
Training is performed in parallel, which significantly speeds up the training process. Tree pruning is also done depth-first in XGBoost, which helps manage model capacity. One of its features is the cross-validation of hyperparameters and built-in functions for assessing the model's performance. The library interacts well with other data science utilities built in a Python environment, such as NumPy, SciPy, and sci-kit-learn, making it possible to incorporate into a confirmed environment. Still, owing to its speed, simplicity, and high performance, XGBoost has become the essential tool in the ‘arsenal’ of many data analysts, machine learning specialists, and aspiring neural networks data scientists.
XGBoost is famous for its many features that make it advantageous in various machine learning tasks and machine learning algorithms, as well as making it more accessible to implement. Here are the key features of XGBoost in Python. Here are the key features of XGBoost in Python:
Regularization:
Applies L1 and L2 regularization techniques to reduce the overfitting and increase the model’s performance.
Parallel Processing:
The pre-train model uses all CPU cores during the training, thus enhancing the training of models by a massive margin.
Handling Missing Data:
An algorithm that, when the model is trained, automatically decides the best way to work with missing values.
Tree Pruning:
In tree pruning, depth-first on the trees is achieved using the parameter “max_depth,” which reduces overfitting.
Built-in Cross-Validation:
It includes methods of cross-validation built-in for model assessment and hyperparameter optimization, as it supports and perform cross validation natively, the implementation is less complicated.
Scalability:
It is optimized for scalability; thus, it can analyze big data and handle feature space data appropriately.
Support for Multiple Languages:
XGBoost was initially developed in Python; however, to improve its scope, it also supports R, Julia, and Java.
Distributed Computing:
The package is designed to be distributed, meaning it can be executed on multiple computers to process large amounts of data.
Custom Objective and Evaluation Functions:
It enables users to set up objective functions and performance measurements for their specific requirements. Furthermore, it supports both binary and multi-class classification.
Feature Importance:
It helps identify the value of various features, can assist in selecting features for a given data set, and provides interpretations of multiple models.
Sparse Aware:
It performs well with sparse data formats, which is very useful when working with data that contains many NULL values or zeros.
Integration with Other Libraries:
It complements the short-gained popularity of data science libraries such as NumPy, SciPy, and sci-kit-learn, which are easy to integrate into data science workflows.
In Python, there are multiple processes involved in creating and configuring an XGBoost model: the process of data collection and preprocessing, creation of the model, management of the model, and evaluation of the model. Below is a detailed guide that will help you get started:
Install XGBoost
First, check if the Xgboost package is on your system. You can install it on your computer with pip:
pip install xgboostImport Libraries
import xgboost as xgb
import numpy as np
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_errorPrepare the Data
In this example, we are going to use the Boston housing dataset:
# Load the Boston housing dataset
boston = load_boston()
#load default value from the package
X = boston.data
y = boston.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Create DMatrix
XGBoost uses a self-defined data structure called DMatrix for training.
# Create DMatrix for training and testing sets
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)Set Parameters
Configure the model parameters. A sample configuration is as follows:
# Set parameters
params = {
'objective': 'reg:squarederror', # Objective function
'max_depth': 4, # Maximum depth of a tree
'eta': 0.1, # Learning rate
'subsample': 0.8, # Subsample ratio of the training instances
'colsample_bytree': 0.8, # Subsample ratio of columns when constructing each tree
'seed': 42 # Random seed for reproducibility
}Train the Model
Use the train method to train an XGBoost model.
# Number of boosting rounds
num_round = 100
# Train the model
bst = xgb.train(params, dtrain, num_round)Make Predictions
Now, use this trained model and make predictions on the test set.
# Make predictions
preds = bst.predict(dtest)Evaluate the Model
Check the performance of the machine learning model using an appropriate metric measure — for instance, root mean squared error:
# Calculate mean squared error
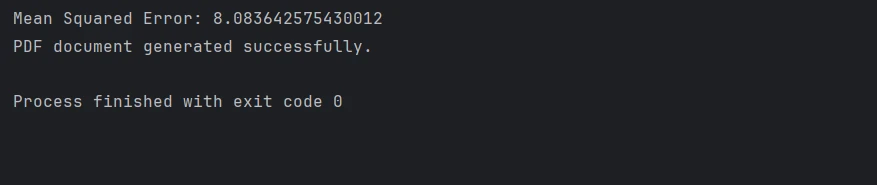
mse = mean_squared_error(y_test, preds)
print(f"Mean Squared Error: {mse}")Save and Load the Model
You can save the trained model to a file and load it later if needed:
# Save the model
bst.save_model('xgboost_model.json')
# Load the model performance
bst_loaded = xgb.Booster()
bst_loaded.load_model('xgboost_model.json')Below is the generated JSON file.

Below is the base installation of both libraries, with an example of how to get started using XGBoost for data analysis and IronPDF for generating PDF reports.
Use the powerful Python pack IronPDF to generate, manipulate, and read PDFs. This enables programmers to perform many programming-based operations on PDFs, such as working with pre-existing PDFs and converting HTML into PDF files. IronPDF is an efficient solution for applications requiring dynamic generation and processing of PDFs since it provides an adaptive and friendly way of generating high-quality PDF documents.
IronPDF can create PDF documents from any HTML content, new or existing. It allows the creation of beautiful, artistic PDF publications from web content that capture the power of modern HTML5, CSS3, and JavaScript in all their forms.
It can add text, pictures, tables, and other content in new programmatically generated PDF documents. Using IronPDF, existing PDF documents can be opened and edited for further modification. In a PDF, you can edit/add content and delete specific content in the document as required.
It uses CSS to stylize the content in PDFs.It supports complex layouts, fonts, colors, and all those design components. Moreover, the ways of rendering HTML material that may be used with JavaScript allow dynamic content creation in PDFs.
IronPDF can be installed via Pip. Use the following command to install it:
pip install ironpdfImport all relevant libraries and load your dataset. In our case, we will use the Boston housing dataset:
import xgboost as xgb
import numpy as np
from ironpdf import * from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Load data
boston = load_boston()
X = boston.data
y = boston.target
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create DMatrix
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
# Set parameters
params = {
'objective': 'reg:squarederror',
'max_depth': 4,
'eta': 0.1,
'subsample': 0.8,
'colsample_bytree': 0.8,
'seed': 42
}
# Train model
num_round = 100
bst = xgb.train(params, dtrain, num_round)
# Make predictions
preds = bst.predict(dtest)
# Create a PDF document
iron_pdf = ChromePdfRenderer()
# Create HTML content
html_content = f"""
<html>
<head>
<title>XGBoost Model Report</title>
</head>
<body>
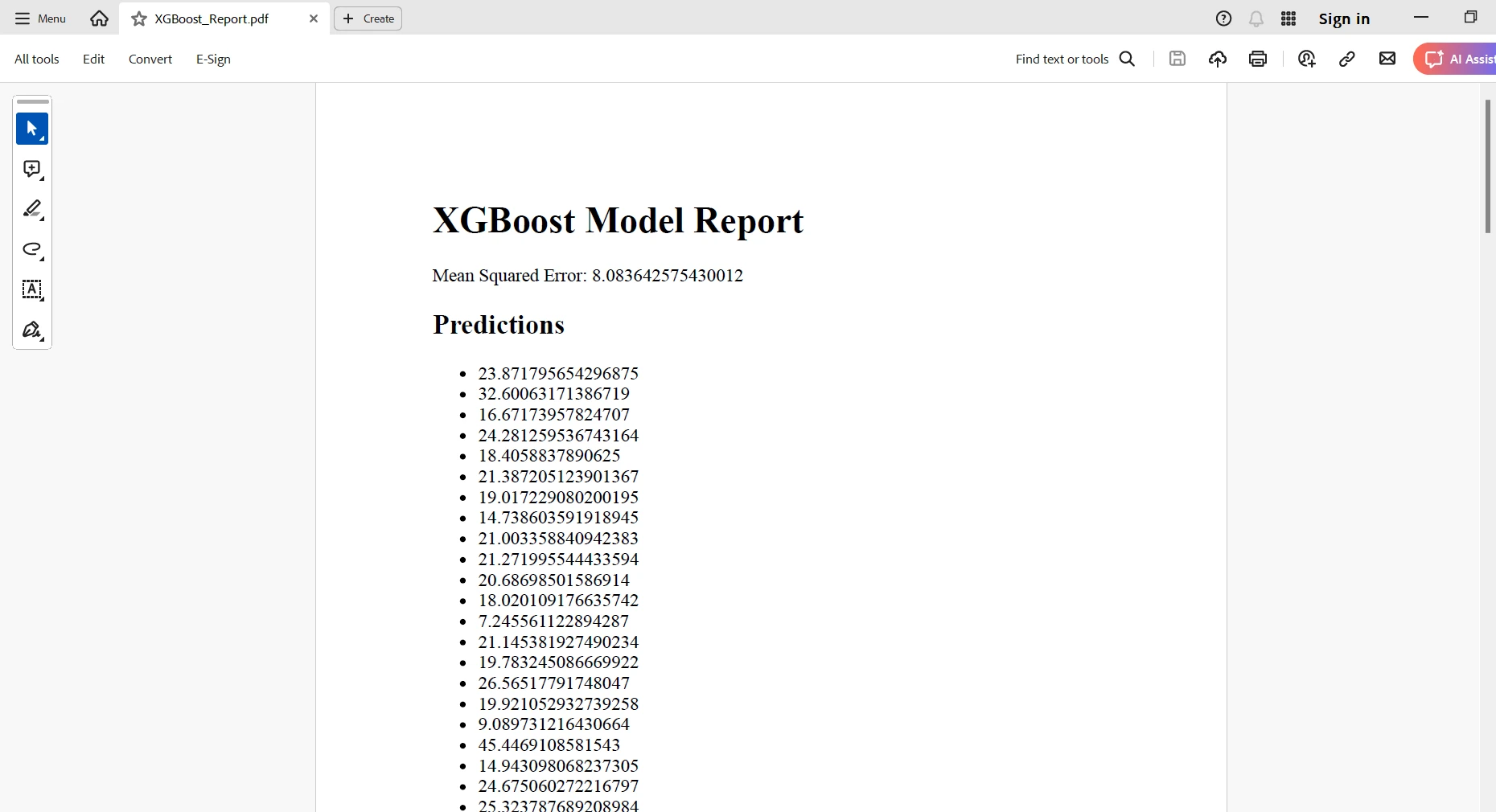
<h1>XGBoost Model Report</h1>
<p>Mean Squared Error: {mse}</p>
<h2>Predictions</h2>
<ul>
{''.join([f'<li>{pred}</li>' for pred in preds])}
</ul>
</body>
</html>
"""
pdf=iron_pdf.RenderHtmlAsPdf(html_content)
# Save the PDF document
pdf.SaveAs("XGBoost_Report.pdf")
print("PDF document generated successfully.")Now, you will create objects of class DMatrix for efficiently handling your data, then set up the model parameters concerning the objective function and hyperparameters. After training the XGBoost model, predict on the test set; you can use Mean Squared Error or similar metrics to evaluate the performance. Then, use IronPDF to create a PDF with all the results.
You create an HTML representation with all your results; then, you will use IronPDF's RenderHtmlAsPdf class to turn this HTML content into a PDF document. Finally, you can save this generated PDF report to a desired location. In other words, this integration will enable you to automate the creation of very elaborate, professional reports in which one encapsulates the insights derived from his Machine Learning models.
In summary, XGBoost and IronPDF are integrated for advanced data analysis and professional report generation. The efficiency and scalability of XGBoost provide the best solution in streaming through complicated machine-learning tasks with robust predictive capabilities and excellent tools for model optimization. You can use Python to link these big guns together in Python with IronPDF seamlessly, turning rich insights gained from XGBoost into highly detailed PDF reports.
These integrations will thus considerably enable the production of attractive and information-rich documents with respect to the results, making them communicable to the stakeholders or suitable for further analysis. Business analytics, academic research, or any data-driven project would not have been possible without an inbuilt synergy between XGBoost and IronPDF for processing data efficiently and communicating the findings with ease.
Integrate IronPDF and IronSoftware products to ensure your clients and end users get feature-rich, premium software solutions. This will also help optimize your projects and processes.
Comprehensive documentation, active community, and frequent updates—all go hand in glove with IronPDF functionality. Iron Software is the name of a trustworthy partner for modern software development projects. IronPDF is available for a free trial to all developers. They can try out all of its features. License rates of $749 are available to get the most value out of this product.

pip install ironpdf-2025.3-py37-none-win_amd64.whiNo credit card required
Your trial key should be in the email.![]() The trial form was submitted
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
No credit card required

Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial





![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.

Book a 30-minute, personal demo.
No contract, no card details, no commitments.


10 .NET API products for your office documents