Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The Python PDF Library


Python has solidified its place as one of the most versatile and powerful programming languages in the world, largely due to its extensive ecosystem of libraries and frameworks. One such library making waves in the machine learning and natural language processing (NLP) space is WhisperX. In this article, we will explore what WhisperX is, its key features, and how it can be utilized in various applications. Additionally, we will introduce IronPDF, another powerful Python library, and demonstrate how to use it alongside WhisperX with a practical code example.
WhisperX is an advanced Python library designed for speech recognition and NLP tasks. It leverages state-of-the-art machine learning models to convert spoken language into written text with high-accuracy language detection and time-accurate speech transcription. WhisperX is particularly useful in applications where real-time translation is critical, such as virtual assistants, automated customer service systems, and transcription services.
To start using WhisperX, you need to install the library. This can be done via pip, the Python package installer. Assuming you have Python and pip installed, you can install WhisperX using the following command:
pip install whisperxHere is a basic example demonstrating how to use WhisperX to transcribe audio files:
import whisperx
# Initialize the WhisperX recognizer
recognizer = whisperx.Recognizer()
# Load your audio
audio_file = "path_to_your_audio_file.wav"
# Perform transcription
transcription = recognizer.transcribe(audio_file)
# Print the transcription
print("Transcription:", transcription)This simple example showcases how to initialize the WhisperX recognizer, load audio, and perform transcription to convert spoken words into text with high accuracy.

WhisperX also offers advanced features such as speaker identification, which can be crucial in multi-speaker environments. Here’s an example of how to use this feature:
import whisperx
# Initialize the WhisperX recognizer with speaker identification enabled
recognizer = whisperx.Recognizer(speaker_identification=True)
# Load your audio file
audio_file = "path_to_your_audio_file.wav"
# Perform transcription with speaker identification
transcription, speakers = recognizer.transcribe(audio_file)
# Print the transcription with speaker labels
for i, segment in enumerate(transcription):
print(f"Speaker {speakers[i]}: {segment}")In this example, WhisperX not only transcribes the audio but also identifies different speakers, labeling each segment accordingly.
While WhisperX handles the transcription of audio to text, there is often a need to present this data in a structured and professional format. This is where IronPDF for Python comes into play. IronPDF is a robust library for generating, editing, and manipulating PDF documents programmatically. It enables developers to generate PDFs from scratch, convert HTML to PDF, and more.
IronPDF can be installed using pip:
pip install ironpdf
Let’s now create a practical example that demonstrates how to use WhisperX for transcribing an audio file and then use IronPDF to generate a PDF document with the transcription.
import whisperx
from ironpdf import IronPdf
# Initialize the WhisperX recognizer
recognizer = whisperx.Recognizer()
# Load your audio file
audio_file = "path_to_your_audio_file.wav"
# Perform transcription
transcription = recognizer.transcribe(audio_file)
# Create a PDF document using IronPDF
renderer = IronPdf.ChromePdfRenderer()
pdf_from_html = renderer.RenderHtmlAsPdf(f"<h1>Transcription</h1><p>{transcription}</p>")
# Save the PDF to a file
output_file = "transcription_output.pdf"
pdf_from_html.save(output_file)
print(f"Transcription saved to {output_file}")Transcription with WhisperX:
transcribe method processes the audio and returns the transcription.PDF Creation with IronPDF:
IronPdf.ChromePdfRenderer.RenderHtmlAsPdf method, add an HTML-formatted string containing the transcription text to the PDF.save method writes the PDF to a file.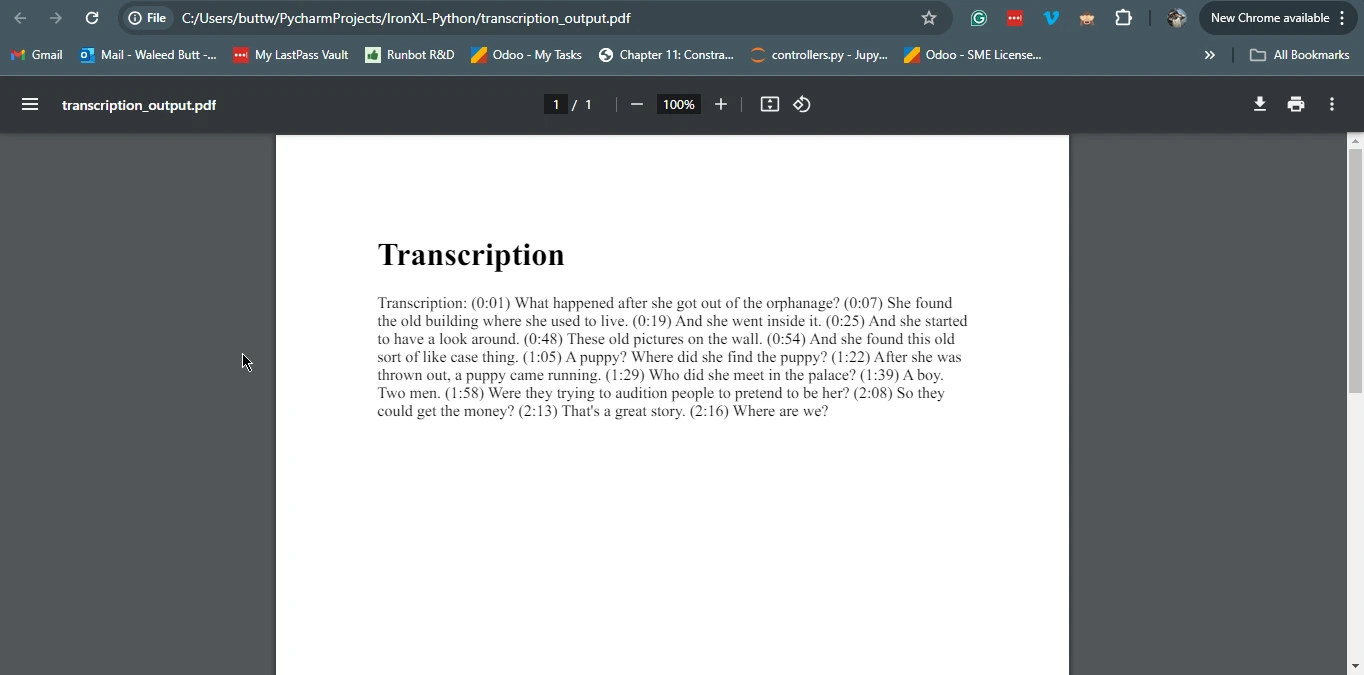
This combined example showcases how to leverage the strengths of both WhisperX and IronPDF to create a complete solution that transcribes audio and generates a PDF document containing the transcription.
WhisperX is a powerful tool for anyone looking to implement speech recognition, speaker diarization, and transcription in their applications. Its high accuracy, real-time processing capabilities, and support for multiple languages make it a valuable asset in the realm of NLP. On the other hand, IronPDF offers a seamless way to create and manipulate PDF documents programmatically. By combining WhisperX and IronPDF, developers can create comprehensive solutions that not only transcribe audio but also present the transcriptions in a polished, professional format.
Whether you are building a virtual assistant, a customer service chatbot, or a transcription service, WhisperX and IronPDF provide the tools necessary to enhance your application's capabilities and deliver high-quality results to your users.
To get more details on IronPDF licensing, visit the IronPDF license page. Additionally, our detailed tutorial on HTML to PDF Conversion is available for further exploration.

pip install ironpdf-2025.4-py37-none-win_amd64.whiNo credit card required
Your trial key should be in the email.![]() The trial form was submitted
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
No credit card required

Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial





![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.

Book a 30-minute, personal demo.
No contract, no card details, no commitments.


10 .NET API products for your office documents