Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The Python PDF Library


In the diverse environment of web development and data fetching, Python is an exceptional language. Its simplicity, coupled with powerful libraries, makes it an ideal choice for handling HTTP requests. Among these libraries, the Python Requests module stands out as a versatile and user-friendly tool for interacting with web services.
In this article, we'll look into the basics of HTTP requests and explore how the Requests library empowers Python developers to handle them efficiently. We'll also look into how HTTP requests can be used with a library such as IronPDF for Python, making producing and editing PDFs easy.
HTTP (Hypertext Transfer Protocol) is the foundation of data communication on the World Wide Web. It is a protocol that governs the transfer of hypertext, such as HTML, between clients (web browsers) and servers. HTTP operates as a request-response protocol, where a client sends a request to a server, and the server responds with the requested resource.
An HTTP request typically consists of several components:
The Requests library in Python simplifies the process of making HTTP requests. It provides an elegant and intuitive API for sending various types of requests and handling responses seamlessly.
Let's walk through some basic usage examples, but first, let's see the process of installing the Requests module.
Before using the Requests library, ensure it's installed. You can install it via pip:
pip install requestsUse the requests.get() method to make a GET request to a specified URL here:
import requests
response = requests.get('https://api.example.com/data')
print(response.text)This code sends a GET request to the specified URL https://api.example.com/data and prints the response body.
To make POST requests with data, use the requests.post() method:
import requests
data = {'key': 'value'}
response = requests.post('https://api.example.com/post', data=data)
print(response.json())Here, we're sending a POST request with JSON data to https://api.example.com/post and printing the JSON response data.
The response object returned by an HTTP request provides various attributes and methods to access different aspects of the response, such as HTTP headers, status code, content, etc. For example:
import requests
response = requests.get('https://api.example.com/data')
print(response.status_code) # Print the status code
print(response.headers) # Print response headersWhen making HTTP requests, it's crucial to handle errors gracefully. The Requests library simplifies error-handling by raising exceptions for common errors, such as connection errors and timeouts. For example:
import requests
try:
response = requests.get('https://api.example.com/data')
response.raise_for_status() # Raise an exception for HTTP errors
except requests.exceptions.HTTPError as err:
print(err)In the requests library, you can disable SSL certificate verification by setting the verify parameter to False in your request:
import requests
# Disable SSL certificate verification
response = requests.get('https://api.example.com/data', verify=False)
# Process the response
print(response.text)You can also include query parameters in your URL by appending them using the params parameter:
import requests
# Define query parameters
params = {'key': 'value', 'param2': 'value2'}
# Make a GET request with query parameters
response = requests.get('https://api.example.com/data', params=params)
# Process the response
print(response.text)In this example, the params dictionary contains query parameters. When making the GET request, these parameters are automatically appended to the URL, resulting in a request URL like https://api.example.com/data?key=value¶m2=value2.
Before diving into the implementation, let's briefly understand IronPDF.
IronPDF for Python is a popular Python library for generating, reading, editing, and manipulating PDF documents. It provides a rich set of features for creating professional-looking PDFs programmatically.
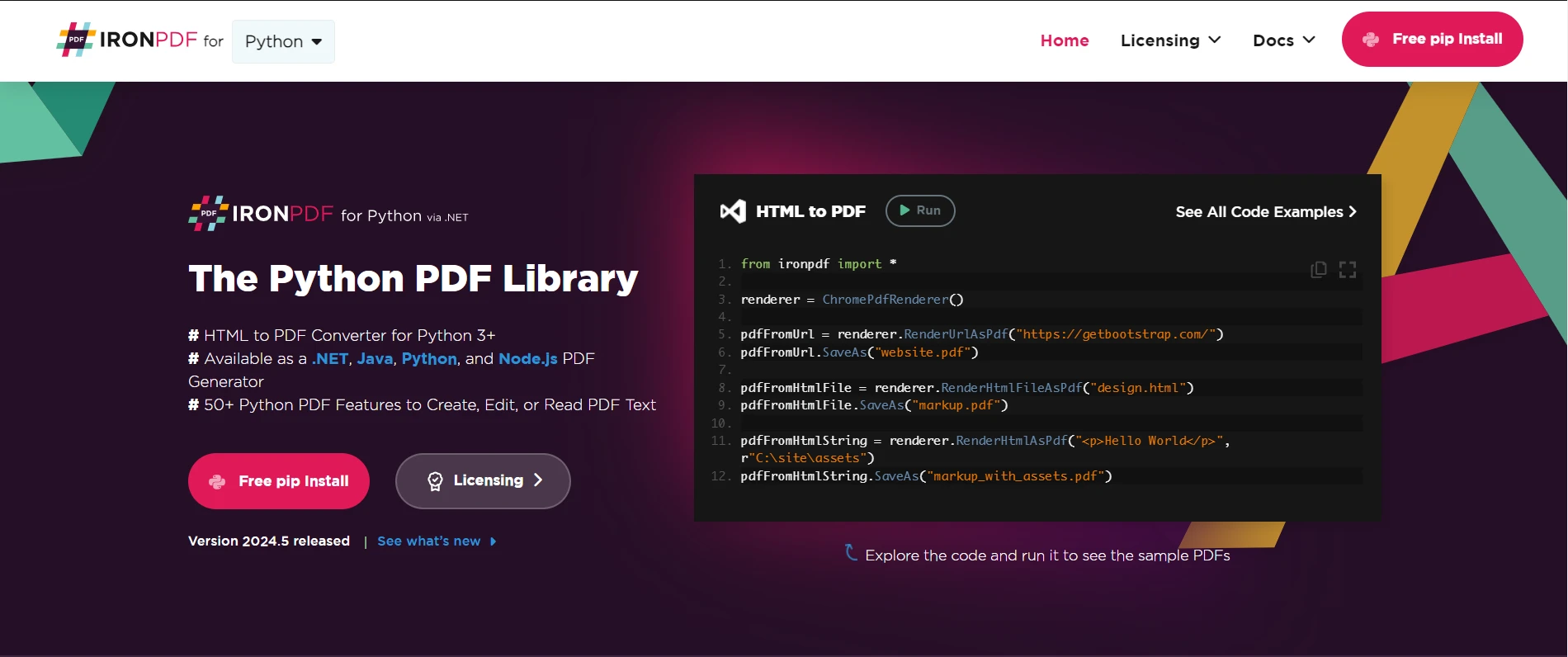
To generate PDFs with IronPDF using content fetched via Requests, follow these steps:
First, ensure that you have IronPDF installed in your Python environment. You can install it via pip:
pip install ironpdfUse the Requests library to fetch the content you want to include in the PDF. For example:
import requests
response = requests.get('https://api.example.com/data')
data = response.textOnce you have the content, use IronPDF to generate the PDF. Here's a basic example:
from ironpdf import *
# Instantiate Renderer
renderer = ChromePdfRenderer()
# Create a PDF from the data received from requests
pdf = renderer.RenderHtmlAsPdf(data)
# Export to a file
pdf.SaveAs("output.pdf")In this example, data contains the HTML content fetched via Requests. IronPDF's RenderHtmlAsPdf() method converts this HTML content into a PDF document. Finally, the PDF is saved to a file using the SaveAs() method.
With the Requests library, Python makes interacting with the web a breeze, enabling developers to focus more on building great applications rather than dealing with the complexities of HTTP communication.
You can further enhance the PDF generation process by customizing the PDF settings, margins, orientation, images, CSS, JavaScript, and more using IronPDF's extensive capabilities. For example:
renderer.RenderingOptions.MarginTop = 40 # millimeters
renderer.RenderingOptions.MarginLeft = 20 # millimeters
renderer.RenderingOptions.MarginRight = 20 # millimeters
renderer.RenderingOptions.MarginBottom = 40 # millimeters
# Example with HTML Assets
# Load external html assets: Images, CSS, and JavaScript.
# An optional BasePath 'C:\\site\\assets\\' is set as the file location to load assets from
my_advanced_pdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", "C:\\site\\assets")
my_advanced_pdf.SaveAs("html-with-assets.pdf")Here, we're setting page margins and adding images from the base directory before saving it to a file.
For more information on IronPDF functionality and capabilities, please visit the documentation page and check out these ready-to-use code examples to integrate with Python.
The Requests library in Python provides a powerful yet simple interface for making HTTP requests. Whether you're fetching data from APIs, interacting with web services, or scraping web pages, Requests streamline the HTTP request process with its intuitive API and robust features.
Combining IronPDF for Python with Requests in Python opens up a world of possibilities for generating PDF documents dynamically from fetched content. By following the steps outlined in this article and exploring the advanced features of both IronPDF and Requests, Python developers can streamline their PDF generation workflow and produce high-quality documents tailored to their specific requirements.
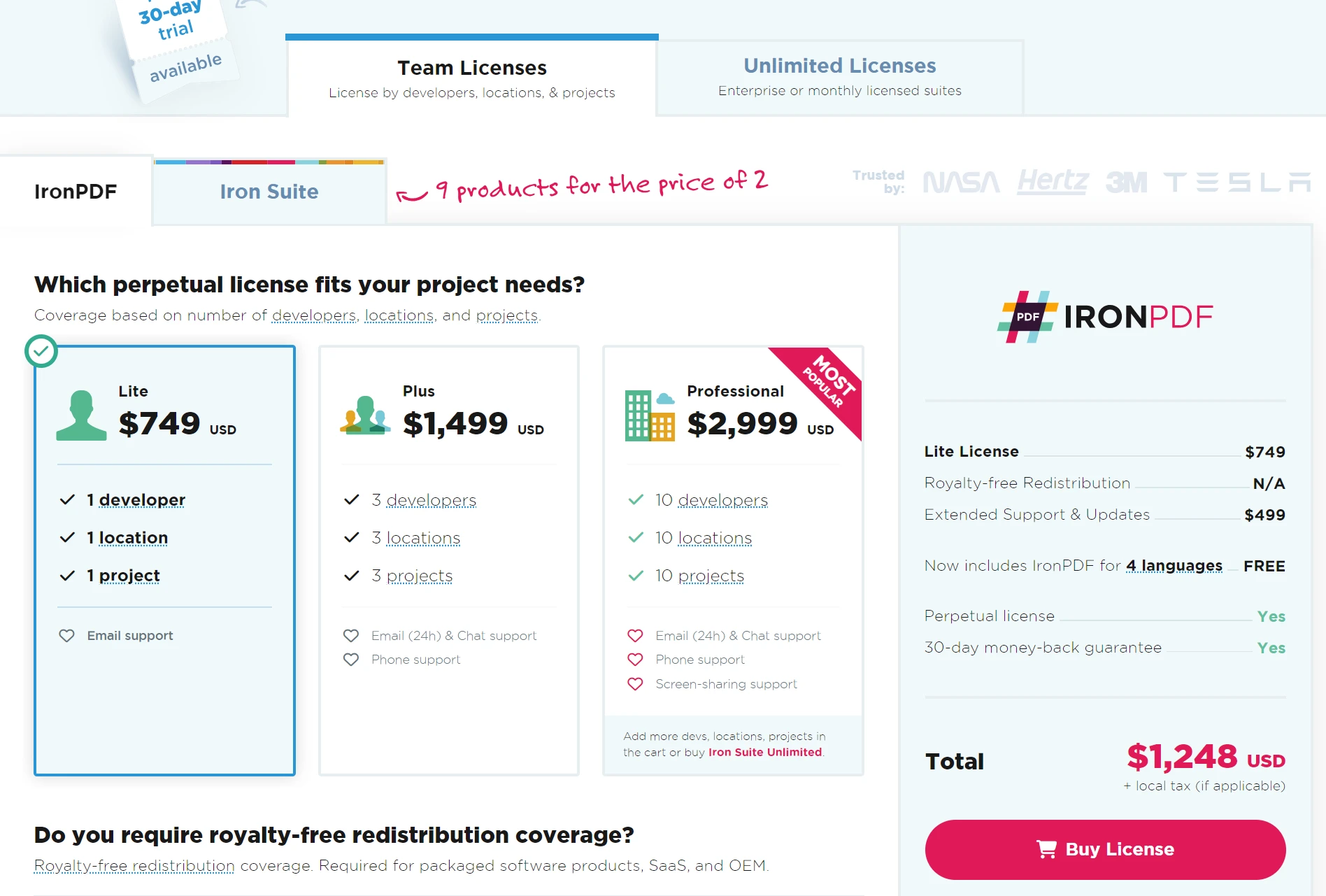
IronPDF is perfect for businesses. Give IronPDF's free trial starting at $749 a try, and with a money-back guarantee, it's a safe choice for managing your documents. Download IronPDF now and experience seamless PDF integration!

pip install ironpdf-2025.3-py37-none-win_amd64.whiNo credit card required
Your trial key should be in the email.![]() The trial form was submitted
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
No credit card required

Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial





![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.

Book a 30-minute, personal demo.
No contract, no card details, no commitments.


10 .NET API products for your office documents