Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The Python PDF Library


PyArrow is a powerful library that provides a Python interface to the Apache Arrow framework. Apache Arrow is a cross-language development platform for in-memory data. It specifies a standardized language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware.PyArrow is basically Apache Arrow Python Bindings realized as a python package. PyArrow enables efficient data interchange and interoperability between different data processing systems and programming languages. Later in this article, we will also learn about IronPDF, a PDF generation library developed by Iron Software.
Columnar Memory Format:
PyArrow uses a columnar memory format, which is highly efficient for, in memory analytics operations. This format allows for better CPU cache utilization and vectorized operations, making it ideal for data processing tasks. PyArrow can read write efficiently parquet file structures due to its columnar nature.
To install PyArrow, you can use either pip or conda:
pip install pyarrowor
conda install pyarrow -c conda-forgeWe are using Visual Studio Code as the code editor. Begin by creating a new file, pyarrowDemo.py.
Here is a simple example of how to use PyArrow to create a table and perform some basic operations:
import pyarrow as pa
import pyarrow.dataset as pt
# Create a PyArrow table
data = [
pa.array([1, 2, 3]),
pa.array(['a', 'b', 'c']),
pa.array([1.1, 2.2, 3.3])
]
table = pa.Table.from_arrays(data, names=['col1', 'col2', 'col3'])
# Display the table
print(table)The Python code uses PyArrow to create a table (`pa.Table`) from three arrays (`pa.array`). It then prints the table, displaying columns named 'col1', 'col2', and 'col3', each containing corresponding data of integers, strings, and floats.

PyArrow can be seamlessly integrated with Pandas to enhance performance, especially when dealing with large datasets. Here’s an example of converting a Pandas DataFrame to a PyArrow Table:
import pandas as pd
import pyarrow as pa
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)The Python code converts a Pandas DataFrame into a PyArrow table (`pa.Table`) and then prints the table. The DataFrame consists of three columns (`col1`, `col2`, `col3`) with integer, string, and float data.

PyArrow supports reading and writing various file formats such as Parquet and Feather. These formats are optimized for performance and are widely used in data processing pipelines.
PyArrow supports memory-mapped file access, which allows for efficient reading and writing of large datasets without loading the entire dataset into memory.
PyArrow provides tools for interprocess communication, enabling efficient data sharing between different processes.
IronPDF is a library for Python that facilitates working with PDF files, enabling tasks such as creating, editing, and manipulating PDF documents programmatically. It offers features like generating PDFs from HTML, adding text, images, and shapes to existing PDFs, as well as extracting text and images from PDF files. Here are some of the key features
IronPDF can easily convert HTML files, HTML strings, and URLs into PDF documents. Utilize the Chrome PDF renderer to render webpages directly into PDF format.
IronPDF is compatible with Python 3+ and operates seamlessly across Windows, Mac, Linux, and Cloud Platforms. It is also supported in .NET, Java, Python, and Node.js. environments.
Enhance PDF documents by setting properties, adding security features like passwords and permissions, and applying digital signatures.
With IronPDF, you can tailor PDFs with customizable headers, footers, page numbers, and adjustable margins. It supports responsive layouts and allows for setting custom paper sizes.
IronPDF is compliant with PDF standards, including PDF/A and PDF/UA. Supports UTF-8 character encoding and seamlessly handles assets such as images, CSS styles, and fonts.
Install necessary libraries:
pip install pyarrow
pip install ironpdfThen add below code to demonstrate the usage of IronPDF and pyarrow python packages
import pandas as pd
import pyarrow as pa
from ironpdf import *
# Apply your license key
License.LicenseKey = "license"
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)
renderer = ChromePdfRenderer()
# Create a PDF from a HTML string using Python
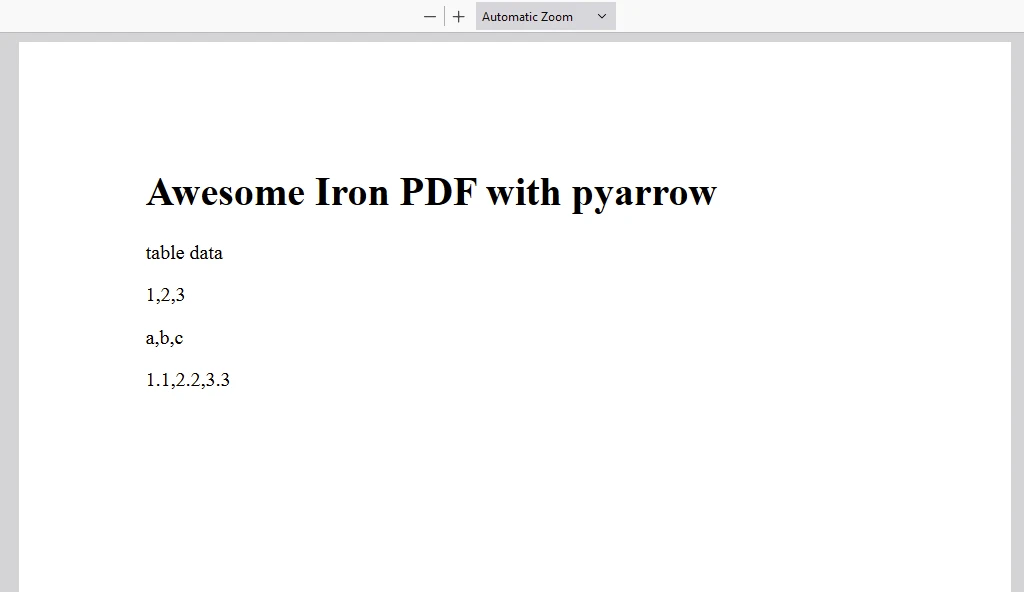
content = "<h1>Awesome Iron PDF with pyarrow</h1>"
content += "<p>table data</p>"
for row in table:
# Access specific values in a row
value_in_column1 = row[0]
value_in_column2 = row[1]
value_in_column3 = row[2]
content += "<p>"+str(value_in_column1)+","+str(value_in_column2)+","+str(value_in_column3)+"</p>"
pdf = renderer.RenderHtmlAsPdf(content)
# Export to a file or Stream
pdf.SaveAs("DemoPyarrow.pdf")The script demonstrates integrating Pandas, PyArrow, and IronPDF libraries to create a PDF document from data stored in a Pandas DataFrame:
Pandas DataFrame Creation:
Conversion to PyArrow Table:
PDF Generation with IronPDF:

Place the License Key at the start of the script before using IronPDF package:
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"PyArrow is a versatile and powerful library that enhances the capabilities of Python for data processing tasks. Its efficient memory format, interoperability features, and integration with Pandas make it an essential tool for data scientists and engineers. Whether you are working with large datasets, performing complex data manipulations, or building data processing pipelines, PyArrow offers the performance and flexibility needed to handle these tasks effectively. On the other hand, IronPDF is a robust Python library that simplifies the creation, manipulation, and rendering of PDF documents directly from Python applications. It seamlessly integrates with existing Python frameworks, allowing developers to generate and customize PDFs dynamically. Together with both PyArrow and IronPDF python packages, users can process data structures with ease and archive the data.
IronPDF also provides comprehensive documentation to aid developers in getting started, accompanied by numerous code examples that showcase its powerful capabilities. For further details, please visit the documentation and code examples pages.

pip install ironpdf-2025.3-py37-none-win_amd64.whiNo credit card required
Your trial key should be in the email.![]() The trial form was submitted
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
No credit card required

Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial





![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.

Book a 30-minute, personal demo.
No contract, no card details, no commitments.


10 .NET API products for your office documents