Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The Python PDF Library


Python developers can now create dynamic PDFs and streamline web scraping thanks to the combination of Beautiful Soup and IronPDF. Developers may easily and precisely extract all the data from web sources with Beautiful Soup, which is well-known for its skill at parsing HTML and XML files. IronPDF, meanwhile, is a powerful tool with smooth integration and solid capabilities that can be used to generate PDF documents programmatically.
Combined, these two powerful tools enable developers to automate processes such as creating invoices, archiving content, and generating reports with unmatched efficiency. We'll delve into the nuances of the Beautiful Soup Python library and IronPDF in this introductory examination, highlighting both their separate merits and their revolutionary potential when combined. Come along as we explore the opportunities that await Python developers by fully utilizing web scraper and PDF creation.
Beautiful Soup is very good at parsing HTML tags and XML documents, turning them into manipulable parse trees that may be explored. It gently accommodates incorrect HTML elements, so developers may deal with incomplete data without worrying about parsing issues.
Beautiful Soup's user-friendly navigation techniques make it simple to find specific items on the HTML page. Using techniques like search, find_all, and select, developers can navigate the tree structure and precisely target elements based on tags, attributes, or CSS selectors.
Beautiful Soup provides easy methods to retrieve an element's characteristics and contents once it has been located inside the parse tree. Developers can obtain any custom attribute linked to the tag, as well as the href attribute and others such as class and id. For additional processing, they can also access the element's inner HTML element or text content.
Beautiful Soup has strong search and filtering features that let developers locate components according to different standards. They can also employ regular expressions for more intricate matching patterns. They can search for particular tags, and filter items based on characteristics or CSS classes. You can further streamline this with the requests library to fetch web pages for parsing. The ability to extract specific data from HTML/XML documents is facilitated by this flexibility.
Within the document structure, developers can move up, down, and sideways in the parse tree. Access to parent, sibling, and child elements is made possible by Beautiful Soup, which makes it easier to explore the document hierarchy in detail.
A fundamental function of Beautiful Soup is the ability to extract data from HTML and XML texts. Text, links, photos, tables, and other content items can be easily extracted by developers from web pages. From complicated documents, they can extract certain data points or entire chunks of content by integrating navigation, filtering, and traversal algorithms.
Beautiful Soup takes care of character encodings and HTML web entities automatically, making sure that text data is processed accurately despite encoding problems or special characters. This feature makes working with web material from various sources easier by doing away with the requirement for entity decoding or manual encoding conversion.
Beautiful Soup not only facilitates extraction but also allows developers to dynamically alter the parse tree. As required, they can restructure the document's structure, add, remove, or alter tags and attributes, or add new elements. This feature makes it possible to do operations within the document, like data cleansing, content augmentation, and structural alteration.
To process HTML or XML documents, Beautiful Soup needs a parser. It makes use of Python's built-in html.parser by default. For better efficiency or more compatibility with specific documents, you can specify different parsers like lxml or html5lib. In the process of constructing a BeautifulSoup object, you can provide the parser:
from bs4 import BeautifulSoup
# Specify the parser (e.g., 'lxml' or 'html5lib')
soup = BeautifulSoup(html_content, 'lxml')Beautiful Soup offers a few choices to alter the way parsing operates. You can, for instance, turn off functions that transform HTML entities to Unicode characters or activate a tighter parsing option. When a BeautifulSoup object is created, these settings are supplied as arguments. This is an illustration of how to turn off entity conversion:
from bs4 import BeautifulSoup
# Disable entity conversion
soup = BeautifulSoup(html_content, 'html.parser', convert_entities=False)Beautiful Soup makes an automatic effort to determine the document's encoding. But occasionally, especially when the content is unclear or has encoding problems, you might have to state the encoding explicitly. When creating the BeautifulSoup object, you have the option to define the encoding:
from bs4 import BeautifulSoup
# Specify the encoding (e.g., 'utf-8')
soup = BeautifulSoup(html_content, 'html.parser', from_encoding='utf-8')By default, Beautiful Soup adds line breaks and indentation to the parsed content to make it easier to read. On the other hand, when constructing the BeautifulSoup object, you can give the formatter option to alter the output formatting. As an illustration, to turn off pretty-printing:
from bs4 import BeautifulSoup
# Disable pretty-printing
soup = BeautifulSoup(html_content, 'html.parser', formatter=None)NavigableString and Tag SubclassesYou can change which classes Beautiful Soup uses for NavigableString and Tag objects. This could help expand Beautiful Soup's capabilities or integrate it with other libraries. When constructing the BeautifulSoup object, you can pass in subclasses of NavigableString and Tag as parameters.
For producing, editing, and modifying PDF documents programmatically in C#, VB.NET, and other .NET languages, IronPDF is a potent .NET library. It is a popular option for many apps since it offers developers an extensive feature set for dynamically creating high-quality PDFs.
IronPDF and Beautiful Soup must be installed first. Pip, the package manager for Python, can be used for this.
pip install beautifulsoup4
pip install ironpdfThen, import your Python script using the required libraries.
from bs4 import BeautifulSoup
from ironpdf import IronPdfUtilize Beautiful Soup to extract information from a website. Imagine that we wish to retrieve an article's title and content from a webpage.
# HTML content of the article
html_content = """
<html>
<head>
<title>Hello</title>
</head>
<body>
<h1>IronPDF</h1>
<p></p>
</body>
</html>
"""
# Create a BeautifulSoup object
soup = BeautifulSoup(html_content, 'html.parser')
# Extract title and content
title = soup.find('title').text
content = soup.find('body').text
print('Title:', title)
print('Content:', content)Let's now utilize IronPDF to create a PDF document with the data that was extracted.
from ironpdfpdf import IronPdf, ChromePdfRenderer
# Initialize IronPDF
# Create a new PDF document
pdf = IronPdf()
# Add title and content to the PDF document
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(
"<html><head><title>{}</title></head><body><h1>{}</h1><p>{}, {}!</p></body></html>"
.format(title, title, content)
)
# Save the PDF document to a file
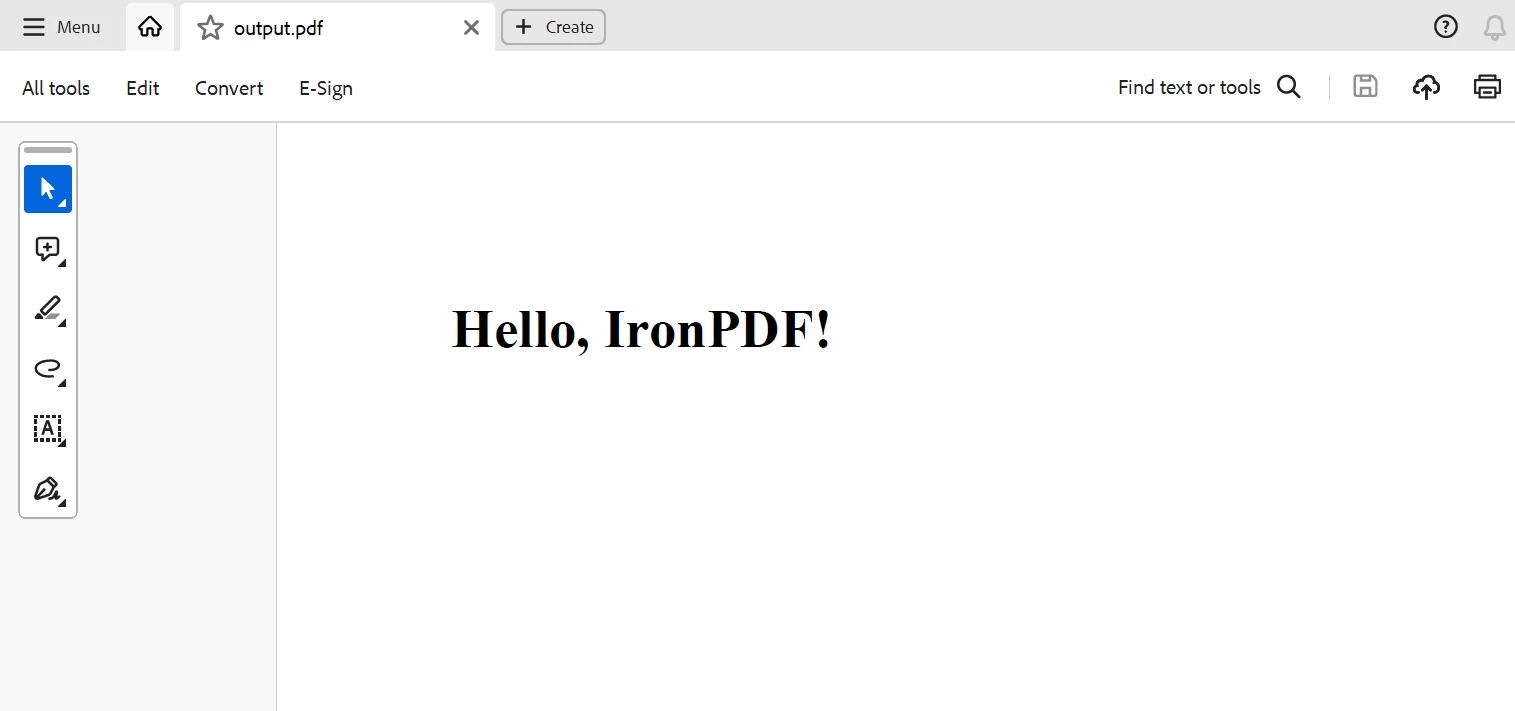
pdf.SaveAs("sample_article.pdf")This script will take the sample article's title and text, scrape it, and store the HTML data as a PDF file called sample_article.pdf that will be saved in the current directory.
In conclusion, developers looking to optimize their data extraction and document creation workflow will find a powerful combination of Beautiful Soup Python and IronPDF. IronPDF's robust features enable the dynamic generation of professional-grade PDF documents, while Beautiful Soup's easy parsing skills enable the extraction of useful data from web sources.
When combined, these two libraries give developers the resources they need to automate a variety of operations, including creating invoices, reports, and web scraping. The collaboration between Beautiful Soup and IronPDF enables developers to achieve their objectives quickly and effectively, whether they include extracting data from intricate HTML code or instantly creating customized PDF publications.
IronPDF is reasonably priced when purchased in a bundle and comes with a lifetime license. Since the package only costs $749, which is a one-time payment for multiple systems, it delivers excellent value. License holders can access online engineering support around the clock. For additional information on the charge, please visit the website. To find out more about Iron Software's offerings, go to this website.

pip install ironpdf-2025.4-py37-none-win_amd64.whiNo credit card required
Your trial key should be in the email.![]() The trial form was submitted
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
No credit card required

Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial





![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.

Book a 30-minute, personal demo.
No contract, no card details, no commitments.


10 .NET API products for your office documents