Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The Python PDF Library


Working with PDF files in Python is a must-have skill for developers building CLI application(s) and data processing systems. Whether you need to extract text from documents, retrieve text and tables from complex layouts, or add custom data to existing PDFs, choosing the right Python library is crucial.
Python PDF files library helps developers convert HTML string to PDF, process or add custom data, and perform advanced operations like extracting tables and text with varying degrees of accuracy. This comprehensive guide explores five popular library options including IronPDF, each with distinct capabilities and use cases, to help you select the most suitable solution for your PDF manipulation needs.
IronPDF stands as a powerful PDF processing solution for Python developers. Built on the robust Chromium engine, it excels at converting HTML to PDF with exceptional accuracy and formatting preservation. It can convert HTML strings and files to PDF. You can use it for extracting text as well from the PDF files. The library was designed specifically for developers who need professional-grade PDF manipulation capabilities in production environments.
It offers seamless integration with existing Python applications and supports both synchronous and asynchronous operations. What sets IronPDF apart is its ability to handle complex layouts, dynamic content, and modern web technologies like CSS3 and JavaScript. The library includes built-in support for headers, footers, pagination, and watermarks. It is best for generating business documents, reports, invoices, and many other PDF-related operations.
ReportLab has established itself as the de facto standard for PDF generation in Python over the past two decades. It's the engine behind Wikipedia's PDF export functionality and is used by numerous Fortune 500 companies. The library offers two distinct versions: a commercial edition (ReportLab PLUS) and an open-source toolkit.
At its core, ReportLab provides a robust page layout engine and a powerful graphics canvas API. The library excels at programmatically generating complex documents, especially those requiring precise control over layout and design. It includes features like flowables (elements that can flow across pages), tables, charts, and vector graphics. ReportLab's architecture is designed to handle both small documents and large-scale batch processing of thousands of personalized documents.
PyPDF2 (and its fork PyPDF4) is a pure Python PDF library in the Python ecosystem. Originally developed as a fork of pypdf, it has evolved into a stable, reliable solution for basic PDF operations. The library is written entirely in Python. It's designed with a focus on PDF manipulation rather than creation. It is effective for tasks like merging, splitting, and transforming existing PDF documents.
It includes robust support for encrypted PDFs and can handle both the reading and writing of PDF metadata. PyPDF2's architecture is modular and it allows developers to work with PDF components at various levels of abstraction. You can install it by this command:
pip install pypdf
PyFPDF is a Python port of the popular PHP PDF library of the same name. It provides a straightforward approach to PDF generation, focusing on simplicity and ease of use. The library was designed with the philosophy of making PDF creation as simple as writing plain text files. It handles all the low-level PDF operations while providing a high-level interface for common tasks. PyFPDF includes built-in support for multiple fonts, including TrueType and Type1, and can embed fonts directly into PDF documents. The library also offers basic HTML support through its HTMLMixin class.
PyMuPDF, also known as Fitz, is a high-performance Python binding for the MuPDF library. It stands out for its versatility in handling multiple document formats beyond just PDFs, including XPS, EPUB, and various image formats. PyMuPDF provides comprehensive document manipulation capabilities, including advanced text extraction with precise positioning information, image extraction and insertion, and annotation handling. The library's architecture is designed to provide both high-level convenience functions and low-level access to PDF structures when needed.
| Feature | IronPDF | ReportLab | PyPDF2 | FPDF | PyMuPDF |
| PDF Creation | ✓ | ✓ | Limited | ✓ | ✓ |
| Text Extraction | Advanced | Basic | Basic | No | Advanced |
| Form Filling | ✓ | ✓ | Limited | No | ✓ |
| HTML Support | Advanced | Basic | No | Limited | Basic |
| Image Handling | ✓ | ✓ | Limited | ✓ | ✓ |
| Dependencies | .NET | Minimal | None | None | C libs |
| License | Commercial | Dual | MIT | LGPL | GPL/Commercial |
After analyzing these Python PDF libraries, IronPDF emerges as a comprehensive solution for professional PDF development needs. While each library has its strengths, IronPDF's combination of features, performance, and enterprise-grade capabilities makes it suitable for production environments. The library's Chromium-based engine ensures superior HTML-to-PDF conversion accuracy, while its extensive API provides developers with tools for complex PDF manipulations.
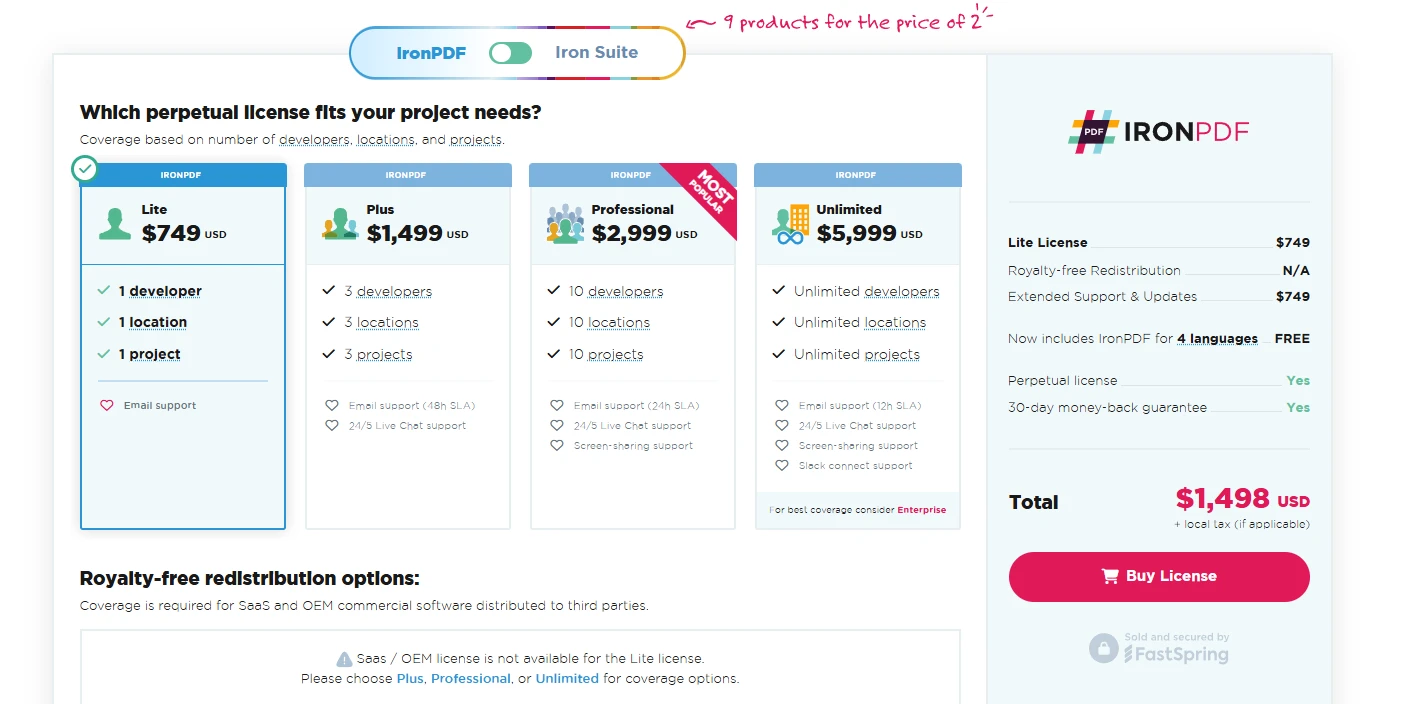
For businesses requiring reliable PDF processing capabilities, IronPDF's robust feature set and professional support justify its commercial investment. IronPDF offers a free trial. The commercial license starts at $749 per developer, which includes comprehensive support and regular updates. IronPDF provides the reliability, features, and support needed to deliver professional-grade solutions. While free alternatives exist, IronPDF's complete feature set and enterprise-ready capabilities make it a better choice.
Consider these key factors when choosing:
Whether you're building a document management system, generating reports, or processing forms, IronPDF provides the tools and stability needed for successful implementation.

pip install ironpdf-2025.4-py37-none-win_amd64.whiNo credit card required
Your trial key should be in the email.![]() The trial form was submitted
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
No credit card required

Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial





![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.

Book a 30-minute, personal demo.
No contract, no card details, no commitments.


10 .NET API products for your office documents