
Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The Java PDF Library


This article will demonstrate how PDF files are read in Java using the PDF Library for the demo Java project, named IronPDF Java Library Overview, to read text and metadata-type objects in PDF files along with creating encrypted documents.
PdfDocument.fromFile method documentation.To streamline the process of reading PDF files in Java, developers often turn to third-party libraries that provide comprehensive and efficient solutions. One such standout library is IronPDF for Java.
IronPDF is designed to be developer-friendly, providing a straightforward API that abstracts the complexities of PDF page manipulation. With IronPDF, Java developers can seamlessly integrate PDF reading capabilities into their projects, reducing development time and effort. This library supports a wide range of PDF functionalities, making it a versatile choice for various use cases.
The main features include the ability to create a PDF file from different formats including HTML, JavaScript, CSS, XML documents, and various image formats. In addition, IronPDF offers the ability to add headers and footers to PDFs, create tables within PDF documents, and much more.
To set up IronPDF, ensure you have a reliable Java compiler. This article recommends utilizing IntelliJ IDEA.
Once the project is established, access the pom.xml file. Insert the following Maven dependencies to integrate IronPDF:
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>com.ironsoftware</artifactId>
<version>2025.4.4</version>
</dependency>
Let's explore a simple Java code example that demonstrates how to use IronPDF to read the content of a PDF file. In this example, let's focus on the method of extracting text from a PDF document.
// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument pdf = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Extracting all text content from the PDF document
String text = pdf.extractAllText();
// Printing the extracted text to the console
System.out.println(text);
}
}This Java code utilizes the IronPDF library to extract text from a specified PDF file. It will import the Java library as well as set the license key, a prerequisite for using the library. The code then loads a PDF document from the file "html_file_saved.pdf" and extracts all of its text content from the file as an internal string buffer. The extracted text is stored in a variable and subsequently printed to the console.
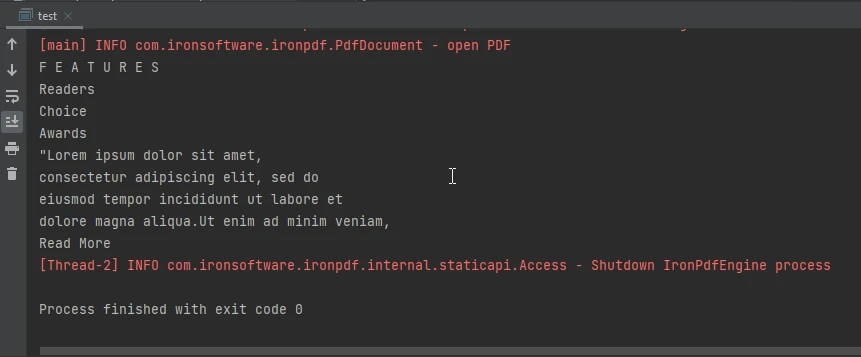 The console output
The console output
Expanding on its capabilities beyond text extraction, IronPDF extends support to the extraction of metadata from PDF files. To illustrate this functionality, let's delve into a Java code example that showcases the process of retrieving metadata from a PDF document.
// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import com.ironsoftware.ironpdf.metadata.MetadataManager;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument document = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Creating a MetadataManager object to access document metadata
MetadataManager metadata = document.getMetadata();
// Extracting the author information from the document metadata
String author = metadata.getAuthor();
// Printing the extracted author information to the console
System.out.println(author);
}
}This Java code utilizes the IronPDF library to extract metadata, specifically the author information, from a PDF document. It begins by loading a PDF document from the file "html_file_saved.pdf." The code retrieves the document's metadata using the MetadataManager class documentation, specifically fetching the author information. The extracted author details are stored in a variable and printed to the console.
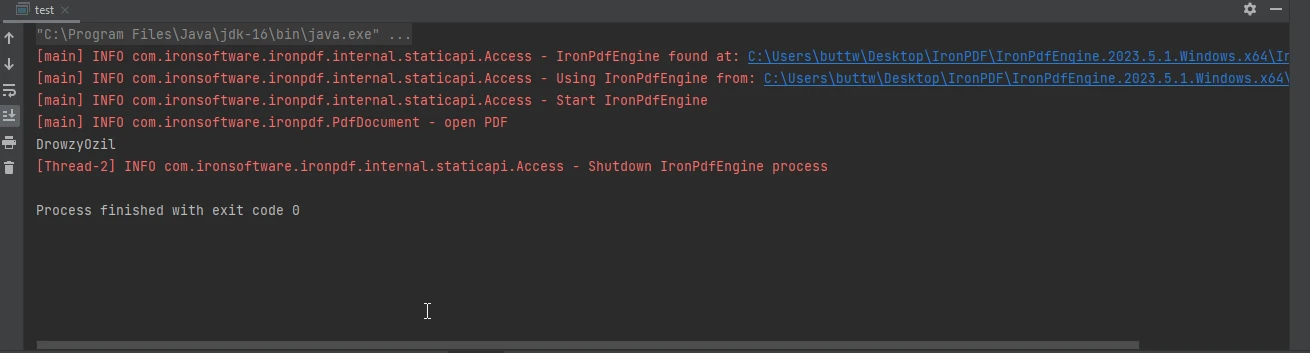 The console output
The console output
In conclusion, reading an existing PDF document in a Java program is a valuable skill that opens up a world of possibilities for developers. Whether it's extracting text, images, or other data, the ability to manipulate PDFs programmatically is a crucial aspect of many applications. IronPDF for Java serves as a robust and efficient solution for developers seeking to integrate PDF reading capabilities into their Java projects.
By following the installation steps and exploring the provided code examples, developers can quickly leverage the power of IronPDF to create new files and handle PDF-related tasks with ease. In addition to this, one can also further explore its capabilities in creating encrypted documents.
IronPDF product portal offers extensive support for its developers. To know more about how IronPDF for Java works, visit these comprehensive documentation pages. Also, IronPDF offers a free trial license offer page that is a great opportunity to explore IronPDF and its features.
Darrius Serrant holds a Bachelor’s degree in Computer Science from the University of Miami and works as a Full Stack WebOps Marketing Engineer at Iron Software. Drawn to coding from a young age, he saw computing as both mysterious and accessible, making it the perfect medium for creativity and problem-solving.
At Iron Software, Darrius enjoys creating new things and simplifying complex concepts to make them more understandable. As one of our resident developers, he has also volunteered to teach students, sharing his expertise with the next generation.
For Darrius, his work is fulfilling because it is valued and has a real impact.

<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2025.4.4</version>
</dependency>
No credit card required
Your trial key should be in the email.![]() The trial form was submitted
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
No credit card required

Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial





![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.

Book a 30-minute, personal demo.
No contract, no card details, no commitments.


10 .NET API products for your office documents