ライブ環境でテストする
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
Python PDFライブラリ


XGBoostは、eXtreme Gradient Boostingの略で、強力で高精度な機械学習アルゴリズムです。 主に回帰分析、分類、ランキング問題に適用されています。 それは、過学習を避けるのに役立つ規則化のような機能を含みます。並列性、および欠落データの処理。
IronPDFは、PDFファイルの作成、変更、読み取りを行うためのPythonライブラリです。 HTML、画像、またはテキストをPDFに簡単に変換でき、ヘッダー、フッター、ウォーターマークを追加することもできます。 主にPythonでの使用を目的としていますが、このプログラミング言語で. NETツールを実装できることは注目に値します。相互運用性ツール(例:Python)の助けを借りて可能です。
XGBoostとIronPDFの組み合わせは、より幅広いアプリケーションを提供します。 IronPDFを通じて、予測の結果をインタラクティブなPDFドキュメントの作成と組み合わせることができます。 この組み合わせは、正確な企業文書や数値の生成、および適用された予測モデルから得られる結果に特に役立ちます。
XGBoostは、アンサンブル学習に基づくPython向けの強力な機械学習ライブラリであり、高効率で柔軟性があります。 XGBoostは、陳天琦による勾配ブースティングアルゴリズムの実装であり、追加の最適化が含まれています。 この方法によって解決できる分類、回帰、ランキングタスクなどの対応するタスクを持つ多くのアプリケーションドメインで、その効果が証明されています。XGBoostにはいくつかのユニークな特徴があります:欠損値の不存在が問題ではありません。 過学習に対抗するために、L1ノルムおよびL2ノルムを使用する機会があります。
申し訳ありませんが、翻訳するコンテンツのテキストを提供してください。その後、英語から日本語に翻訳いたします。!-- 壊れた画像 Pixabayから追加、ファイルから選択、またはここに画像をドラッグアンドドロップします。 -->
トレーニングは並行して行われるため、トレーニングプロセスが大幅に高速化されます。 XGBoostにおいて、木の剪定は深さ優先探索でも行われ、モデルの容量管理を助けます。 その機能の一つは、ハイパーパラメータのクロスバリデーションと、モデルのパフォーマンスを評価するための組み込み関数です。 このライブラリは、NumPy、SciPy、sci-kit-learn などのPython環境で構築された他のデータサイエンスユーティリティと良好に連携し、確認済み環境に組み込むことが可能です。 それでも、その速度、シンプルさ、高性能のおかげで、XGBoostは多くのデータアナリスト、機械学習スペシャリスト、ニューラルネットワークを志すデータサイエンティストの「武器庫」の必須ツールとなっています。
XGBoostは、多くの機械学習タスクや機械学習アルゴリズムにおいて有利であることを可能にする多くの機能で有名であり、実装しやすくしています。 これがPythonにおけるXGBoostの主要な機能です。 以下は、PythonにおけるXGBoostの主な機能です:
正則化
L1およびL2正則化技術を適用して、過学習を減少させ、モデルの性能を向上させます。
パラレル処理:
事前学習モデルはトレーニング中にすべてのCPUコアを使用し、それによってモデルのトレーニングを大幅に強化します。
欠損データの処理:
モデルが訓練されると、自動的に欠損値を処理する最適な方法を決定するアルゴリズム。
剪定
木の剪定においては、「max_depth」パラメータを使用して木の深さ優先による処理を行い、過学習を軽減します。
組み込みクロスバリデーション:
モデル評価とハイパーパラメータの最適化のためにビルトインされた交差検証の手法が含まれており、ネイティブに交差検証をサポートし実行するため、実装はそれほど複雑ではありません。
スケーラビリティ
スケーラビリティのために最適化されています。 したがって、大規模データを分析し、特徴空間データを適切に処理することができます。
複数言語のサポート:
XGBoostはもともとPythonで開発されました。 しかし、その範囲を広げるために、R、Julia、Javaもサポートしています。
分散コンピューティング
このパッケージは配布用に設計されており、つまり、大量のデータを処理するために複数のコンピューターで実行できるということです。
カスタム目的関数および評価関数:
それはユーザーが特定の要件に対する目的関数とパフォーマンス測定を設定できるようにします。 さらに、バイナリと多クラス分類の両方をサポートしています。
特徴の重要性:
さまざまな機能の価値を特定するのに役立ち、特定のデータセットに対する機能の選択を支援し、複数のモデルの解釈を提供します。
スパース対応
それは、NULL値やゼロを多く含むデータを扱う際に非常に便利である希薄なデータ形式で良好に動作します。
他のライブラリとの統合:
それは、NumPy、SciPy、およびscikit-learnなどのデータサイエンスライブラリの短期間で得た人気を補完し、これらはデータサイエンスのワークフローに簡単に統合できます。
Pythonでは、XGBoostモデルの作成と設定には複数のプロセスが関与しています: データ収集と前処理のプロセス、モデルの作成、モデルの管理、およびモデルの評価です。 以下は、開始するための詳細なガイドです:
XGBoostをインストールする
まず、Xgboostパッケージがシステムにあるか確認してください。 それをインストールするには、pipを利用してコンピュータにインストールすることができます。
pip install xgboostライブラリをインポート
import xgboost as xgb
import numpy as np
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_errorデータを準備する
この例では、ボストン住宅データセットを使用します。
# Load the Boston housing dataset
boston = load_boston()
#load default value from the package
X = boston.data
y = boston.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)DMatrixを作成する
XGBoostは、トレーニングにDMatrixと呼ばれる独自のデータ構造を使用します。
# Create DMatrix for training and testing sets
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)パラメータを設定
モデルパラメータを構成します。 サンプル構成は以下の通りです。
# Set parameters
params = {
'objective': 'reg:squarederror', # Objective function
'max_depth': 4, # Maximum depth of a tree
'eta': 0.1, # Learning rate
'subsample': 0.8, # Subsample ratio of the training instances
'colsample_bytree': 0.8, # Subsample ratio of columns when constructing each tree
'seed': 42 # Random seed for reproducibility
}モデルをトレーニングする
trainメソッドを使用してXGBoostモデルを訓練します。
# Number of boosting rounds
num_round = 100
# Train the model
bst = xgb.train(params, dtrain, num_round)予測を立てる
次に、この訓練済みモデルを使用してテストセットで予測を行います。
# Make predictions
preds = bst.predict(dtest)モデルを評価する
適切なメトリック測定を使用して、機械学習モデルのパフォーマンスを確認してください。例えば、二乗平均平方根誤差:
# Calculate mean squared error
mse = mean_squared_error(y_test, preds)
print(f"Mean Squared Error: {mse}")モデルの保存と読み込み
トレーニング済みのモデルをファイルに保存し、必要に応じて後で読み込むことができます。
# Save the model
bst.save_model('xgboost_model.json')
# Load the model performance
bst_loaded = xgb.Booster()
bst_loaded.load_model('xgboost_model.json')申し訳ありませんが、翻訳するコンテンツのテキストを提供してください。その後、英語から日本語に翻訳いたします。!-- 壊れた画像 Pixabayから追加、ファイルから選択、またはここに画像をドラッグアンドドロップします。 -->
以下は生成されたJSONファイルです。

以下は、両ライブラリの基本インストールであり、データ分析にXGBoostを使用し、PDFレポートを生成するためにIronPDFを使用する開始例です。
強力なPythonパックIronPDFを使用して、PDFの生成、操作、読み取りを行いましょう。 これにより、プログラマーは既存のPDFを操作したり、HTMLをPDFファイルに変換したりするなど、多くのプログラミングベースの操作をPDFで行うことができます。 IronPDFは、高品質なPDFドキュメントを動的に生成および処理することを必要とするアプリケーションに最適なソリューションであり、適応性があり使いやすい方法でPDFを生成することができます。
IronPDFは、任意のHTMLコンテンツから新規または既存のPDFドキュメントを作成できます。 それは、現代のHTML5、CSS3、およびJavaScriptのすべての形態の力を捉えたウェブコンテンツから、美しく芸術的なPDF出版物を作成することを可能にします。
新しくプログラムで生成されたPDFドキュメントにテキスト、画像、表、その他のコンテンツを追加できます。 IronPDFを使用すると、既存のPDFドキュメントを開いて、さらに修正することができます。 PDFでは、必要に応じてドキュメント内のコンテンツを編集/追加したり、特定のコンテンツを削除したりできます。
PDFのコンテンツをスタイリングするためにCSSを使用します。複雑なレイアウト、フォント、色、およびそれらのデザイン要素すべてをサポートします。 さらに、JavaScriptで使用できるHTML素材のレンダリング方法により、PDFで動的なコンテンツ作成が可能になります。
IronPDFはPipを介してインストールできます。インストールするには、次のコマンドを使用してください:
pip install ironpdfすべての関連ライブラリをインポートし、データセットを読み込みます。 私たちの場合、ボストン住宅データセットを使用します。
import xgboost as xgb
import numpy as np
from ironpdf import * from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Load data
boston = load_boston()
X = boston.data
y = boston.target
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create DMatrix
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
# Set parameters
params = {
'objective': 'reg:squarederror',
'max_depth': 4,
'eta': 0.1,
'subsample': 0.8,
'colsample_bytree': 0.8,
'seed': 42
}
# Train model
num_round = 100
bst = xgb.train(params, dtrain, num_round)
# Make predictions
preds = bst.predict(dtest)
# Create a PDF document
iron_pdf = ChromePdfRenderer()
# Create HTML content
html_content = f"""
<html>
<head>
<title>XGBoost Model Report</title>
</head>
<body>
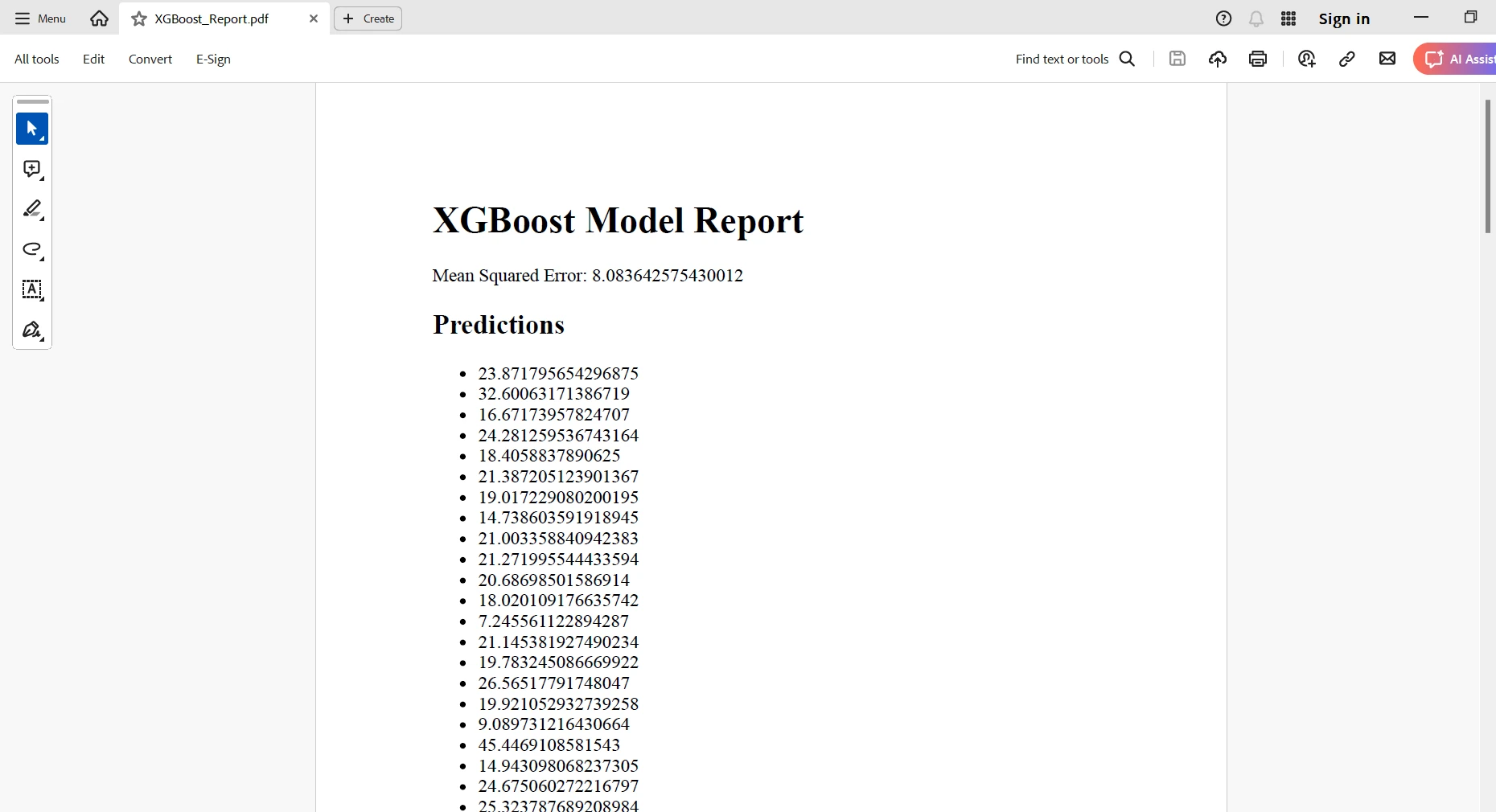
<h1>XGBoost Model Report</h1>
<p>Mean Squared Error: {mse}</p>
<h2>Predictions</h2>
<ul>
{''.join([f'<li>{pred}</li>' for pred in preds])}
</ul>
</body>
</html>
"""
pdf=iron_pdf.RenderHtmlAsPdf(html_content)
# Save the PDF document
pdf.SaveAs("XGBoost_Report.pdf")
print("PDF document generated successfully.")次に、データを効率的に処理するためにDMatrixクラスのオブジェクトを作成し、目的関数やハイパーパラメータに関するモデルパラメータを設定します。 XGBoostモデルのトレーニング後、テストセットで予測を行います。 性能を評価するために、平均二乗誤差や類似の指標を使用することができます。 次に、IronPDFを使用してすべての結果を含むPDFを作成します。
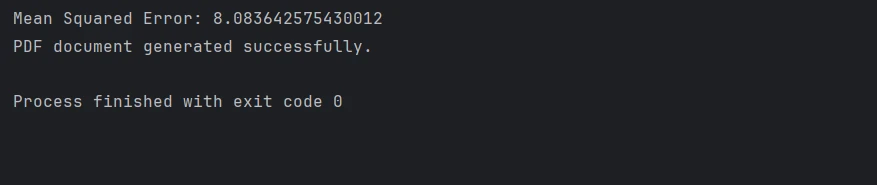
すべての結果を使用してHTML表現を作成します。 次に、IronPDF の RenderHtmlAsPdf クラスを使用して、この HTML コンテンツを PDF に変換します。PDFドキュメント. 最後に、この生成されたPDFレポートを希望の場所に保存できます。 言い換えれば、この統合により、Machine Learningモデルから得られた洞察を集約した非常に精巧でプロフェッショナルなレポートの作成を自動化することが可能になります。
要約すると、XGBoostとIronPDFは高度なデータ分析とプロフェッショナルなレポート生成のために統合されています。 XGBoostの効率性とスケーラビリティは、堅牢な予測能力とモデル最適化のための優れたツールを伴った複雑な機械学習タスクのストリーミングにおいて最良のソリューションを提供します。 Pythonを使用して、IronPDFをPythonにシームレスにリンクし、XGBoostから得られる豊富なインサイトを非常に詳細なPDFレポートに変換できます。
これらの統合により、結果に関して魅力的で情報豊富なドキュメントの作成が可能になり、それをステークホルダーに伝達したり、さらなる分析に適したものにしたりすることができます。 ビジネス分析、学術研究、またはその他のデータ駆動型プロジェクトは、データを効率的に処理し、結果を容易に伝えるためのXGBoostとIronPDF間の内蔵されたシナジーがなければ可能ではありませんでした。
統合するIronPDF以下のコンテンツを日本語に翻訳してください:Iron Software顧客や最終ユーザーに機能豊富でプレミアムなソフトウェアソリューションを提供するための製品。 これにより、プロジェクトとプロセスの最適化にも役立ちます。
包括的なドキュメント、活発なコミュニティ、頻繁なアップデート—これらすべてがIronPDFの機能と密接に関連しています。 Iron Softwareは、現代のソフトウェア開発プロジェクトにおける信頼できるパートナーの名前です。 IronPDFは、すべての開発者が無料で試用できます。 彼らはすべての機能を試すことができます。 この製品の最大の価値を得るために、$749 のライセンス料金をご利用いただけます。

pip install 製品名-製品バージョン-py37-none-win_amd64.whlクレジットカードは不要です
試用キーはメールに送信されるはずです。![]() 試用版申し込みフォームが
試用版申し込みフォームが
正常に送信されました。
もし届かない場合は、
support@ironsoftware.comにお問い合わせください。

無料で始めましょう
クレジットカードは不要です
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
30日間、完全に機能する製品をご利用いただけます。
数分で稼働させることができます。
製品トライアル期間中にサポートエンジニアリングチームへの完全アクセス





![]() クレジットカードやアカウント作成は不要です。
クレジットカードやアカウント作成は不要です。
試用キーはメールにあるはずです。
もしない場合は、
support@ironsoftware.comまでご連絡ください。

30分の個別デモを予約する。
契約なし、カード情報不要、義務なし。


10 .NET API製品オフィスドキュメントのために