

HTML to PDF NodeJS

HTML、CSS、およびJavaScriptから高忠実度のPDFを作成できる能力は、IronPDFの最も強力かつ最も人気のある機能です。 このチュートリアルは、Node開発者がIronPDFを活用して、自分のプロジェクトにHTMLからPDFへの変換機能を組み込むための包括的な入門書です。
IronPDFは、開発者がソフトウェアアプリケーションに強力で堅牢なPDF処理機能を迅速かつ簡単に実装するのを支援する高レベルのAPIライブラリです。 IronPDFは複数のプログラミング言語で利用可能です。 .NET、Java、およびPythonでPDFを作成する方法の詳細については、公式のドキュメントページをご参照ください。 このチュートリアルでは、Node.jsプロジェクトでの使用方法について説明します。
Node.jsでHTMLをPDFに変換する方法
- Install the HTML to PDF Node library via NPM:
npm install @ironsoftware/ironpdf. - @ironsoftware/ironpdf パッケージから PdfDocument クラスをインポートします。
- HTML文字列、ファイル、またはWeb URLから変換します。
- (optional) Add headers & footers, change page size, orientation and color.
- 生成されたPDFを保存するには、
PdfDocument.saveAsを呼び出します。
はじめに
今日から無料トライアルでIronPDFをあなたのプロジェクトで使い始めましょう。
Node.js用のIronPDFライブラリをインストールする
お使いのNodeプロジェクトで以下のNPMコマンドを実行してIronPDF for Node.jsパッケージをインストールしてください:
npm install @ironsoftware/ironpdfボタンを 手動で押すことで、IronPDFパッケージをダウンロードしてインストールすることもできます。
IronPDFエンジンを手動でインストールする(オプション)
IronPDF for Node.jsは現在、正常に動作するためにIronPDF Engineバイナリを必要としています。
オペレーティングシステムに適したパッケージをインストールすることで、IronPDF Engine のバイナリをインストールします。
次の内容にご注意ください。
@ironpdfは、初回実行時にNPMからブラウザとオペレーティングシステムに適したバイナリを自動でダウンロードしてインストールします。 ただし、インターネットへのアクセスが制限されている、または望ましくない状況では、このバイナリを明示的にインストールすることが重要になります。
ライセンスキーを適用する(オプション)
デフォルトでは、IronPDFは生成または変更したすべてのドキュメントにタイトル付きの背景透かしをブランド表示します。

透かしなしでPDFドキュメントを生成するためには、ironpdf.com/nodejs/licensing/でライセンスキーを取得してください。
IronPDFを追加のウォーターマークブランディングなしで使用するには、有効なライセンスキーを使用してグローバルなIronPdfGlobalconfigオブジェクトのlicenseKeyプロパティを設定する必要があります。 これを実現するためのソースコードは以下の通りです:
import {IronPdfGlobalConfig} from "@ironsoftware/ironpdf";
var config = IronPdfGlobalConfig.getConfig();
config.licenseKey = "{YOUR-LICENSE-KEY-HERE}";ライセンスキーを購入するには、ライセンスページをご覧いただくか、無料試用ライセンスキーを取得するためにお問い合わせください。
[{i:(ライセンスキーおよびその他のグローバル構成設定は、他のライブラリ関数を使用する前に設定して、最良のパフォーマンスと適切な機能を確保してください。
このチュートリアルの以下のセクションでは、ライセンスキーを持っており、それを_config.js_という別のJavaScriptファイルに設定していることを前提とします。 以下のスクリプトをインポートして、IronPDFの機能を使用します:
import {PdfDocument} from "@ironsoftware/ironpdf";
import('./config.js');
// ...HTMLをPDFに変換
IronPDFライブラリのNodeリリースは、HTMLコンテンツからPDFファイルを作成するための3つのアプローチを提供します:
-
HTMLコードの文字列から
-
ローカルのHTMLファイルから
-
オンラインウェブサイトから
このセクションでは三つの方法を詳細に説明します。
HTML文字列からPDFファイルを作成する
PdfDocument.fromHtml は、生のウェブページマークアップの文字列からPDFを生成する方法です。
この方法は3つのアプローチの中で最も柔軟性があります。 これは、HTML文字列内のデータがテキストファイル、データストリーム、HTMLテンプレート、生成されたHTMLデータなど、事実上どこからでも供給される可能性があるためです。
以下のコード例は、PdfDocument.fromHtml メソッドを実践で使用する方法を示しています。
import {PdfDocument} from "@ironsoftware/ironpdf";
import('./config.js');
// Create a PDF from the HTML String "Hello world!"
const pdf = await PdfDocument.fromHtml("<h1>Hello from IronPDF!</h1>");
// Save the PDF document to the file system.
await pdf.saveAs("html-string-to-pdf.pdf");上記のように、PdfDocument.fromHtml メソッドをレベル1の見出し要素のマークアップコードを含むテキスト文字列で呼び出します。
PdfDocument.fromHtmlは、PdfDocumentクラスのインスタンスを解決するPromiseを返します。 PdfDocument は、ライブラリがあるソースコンテンツから生成したPDFファイルを表します。 このクラスは、IronPDFの主要な機能の基礎を形成し、重要なPDFの作成および編集のユースケースを推進します。
最後に、PdfDocumentのsaveAsメソッドを使用してファイルをディスクに保存します。 保存されたPDFファイルは以下に表示されています。
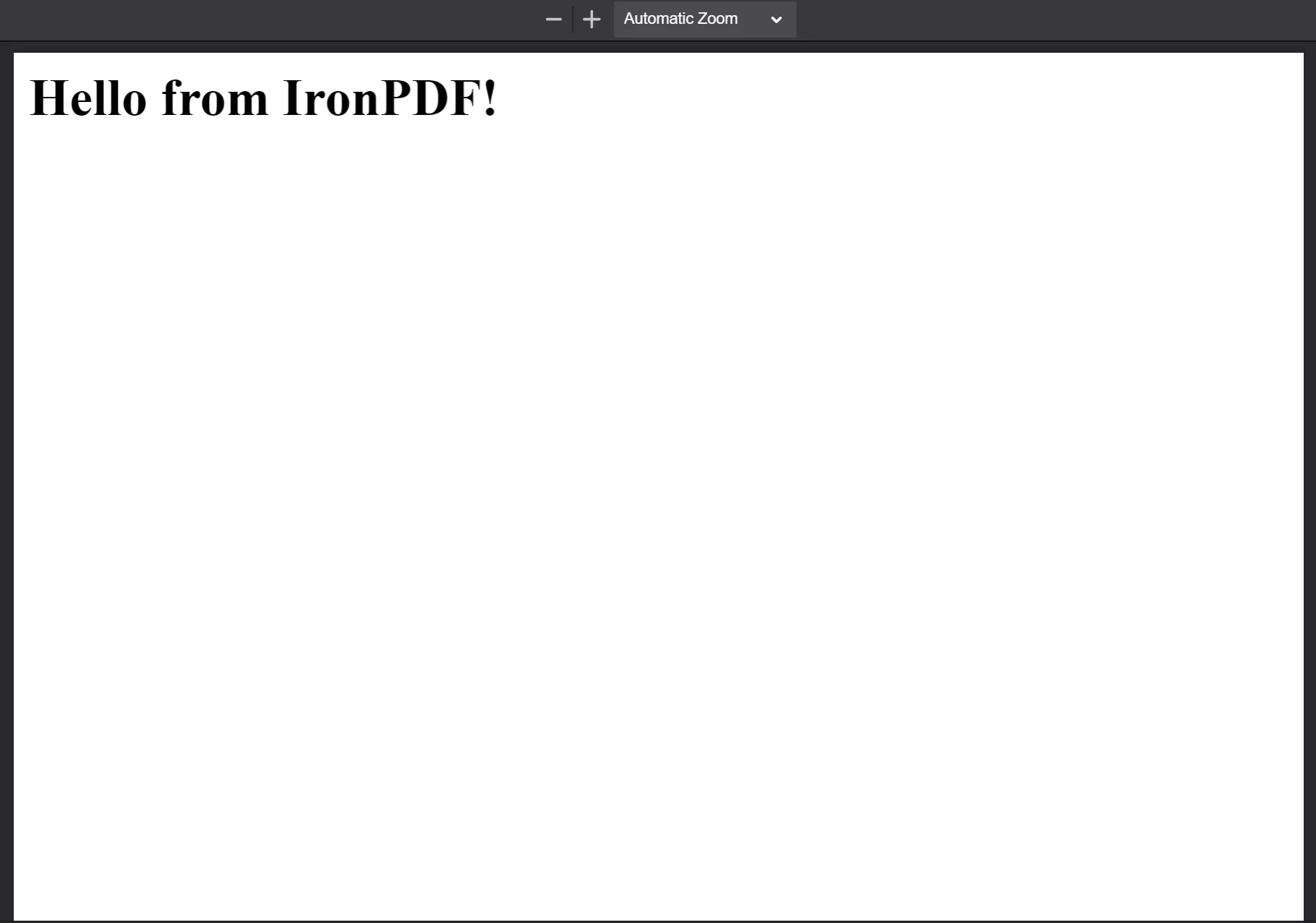
**HTML文字列 "<h1>Hello from IronPDF!</h1>" から生成されたPDF。 PdfDocument.fromHtmlが生成するPDFファイルは、まさにウェブページのコンテンツのように表示されます。
HTMLファイルからPDFファイルを作成する
PdfDocument.fromHtml は、HTML文字列だけでは機能しません。 そのメソッドは、ローカルHTMLドキュメントへのパスも受け付けます。
次の例では、このサンプルのウェブページを使って作業します。
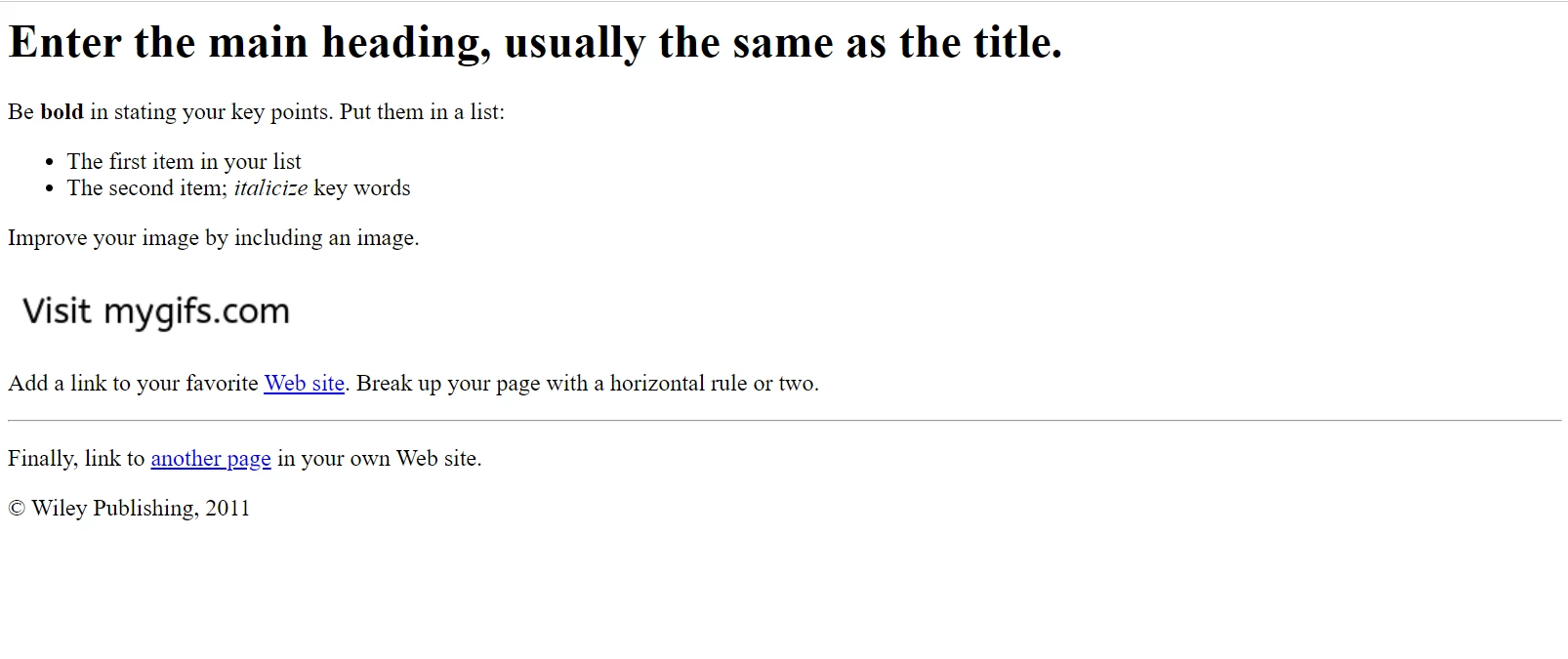
Google Chromeで表示されるサンプルHTMLページ。 このページや同様のページをFile Samplesのウェブサイトからダウンロードしてください: https://filesamples.com/samples/code/html/sample2.html
次のコード行はサンプルドキュメント全体をPDFに変換します。 HTML文字列の代わりに、サンプルファイルの有効なファイルパスを使ってPdfDocument.fromHtmlを呼び出します。
import {PdfDocument} from "@websiteironsoftware/ironpdf";
import('./config.js');
// Render a PDF from an HTML File
const pdf = await PdfDocument.fromHtml("./sample2.html");
// Save the PDF document to the same folder as our project.
await pdf.saveAs("html-file-to-pdf-1.pdf");以下に、生成されたPDFの内容を記載しています。 IronPDFは、オリジナルのHTMLドキュメントの外観を維持するだけでなく、リンク、フォーム、その他の一般的なインタラクティブ要素の機能も保持します。

このPDFは、前のコード例から生成されました。 前の画像とその外観を比較し、目立つ類似点に注目してください!
サンプルページのソースコードを確認した場合、その内容がより複雑であることに気付くでしょう。 それは、段落、順序なしリスト、改行、水平線、ハイパーリンク、画像など、より多くの種類のHTML要素を使用し、またスクリプト(クッキーの設定に使用)も含みます。
IronPDFは、これまで使用していたものよりもはるかに複雑なウェブコンテンツをレンダリングすることができます。 これを実証するために、次のページを考えてみましょう:

Puppeteerについて書かれた記事、ヘッドレスブラウザーインスタンスを使用してChromeをプログラムで制御する能力で人気のあるNodeライブラリ
上記に表示されているページは、Puppeteer Node Libraryについて書かれた記事のものです。 Puppeteerは、Node開発者がサーバーサイドまたはクライアントサイドで多数のブラウザタスクを自動化するために使用するヘッドレスブラウザセッションを実行します(その中にはサーバーサイドHTML PDF生成が含まれます)。
新しいページは、多くのアセット(CSSファイル、画像、スクリプトファイルなど)を参照し、さらに複雑なレイアウトを使用しています。 この次の例では、このページの保存されたコピー(ソースアセットとともに)をピクセルパーフェクトなPDFに変換します。
以下のコードスニペットは、ページがプロジェクトと同じディレクトリに「sample4.html」として保存されていることを前提としています:
// Render a from even more complex HTML code.
PdfDocument.fromHtml("./sample4.html").then((pdf) async {
return await pdf.saveAs("html-file-to-pdf-2.pdf");
});以下の画像は、上記のコードスニペットの結果を示しています。
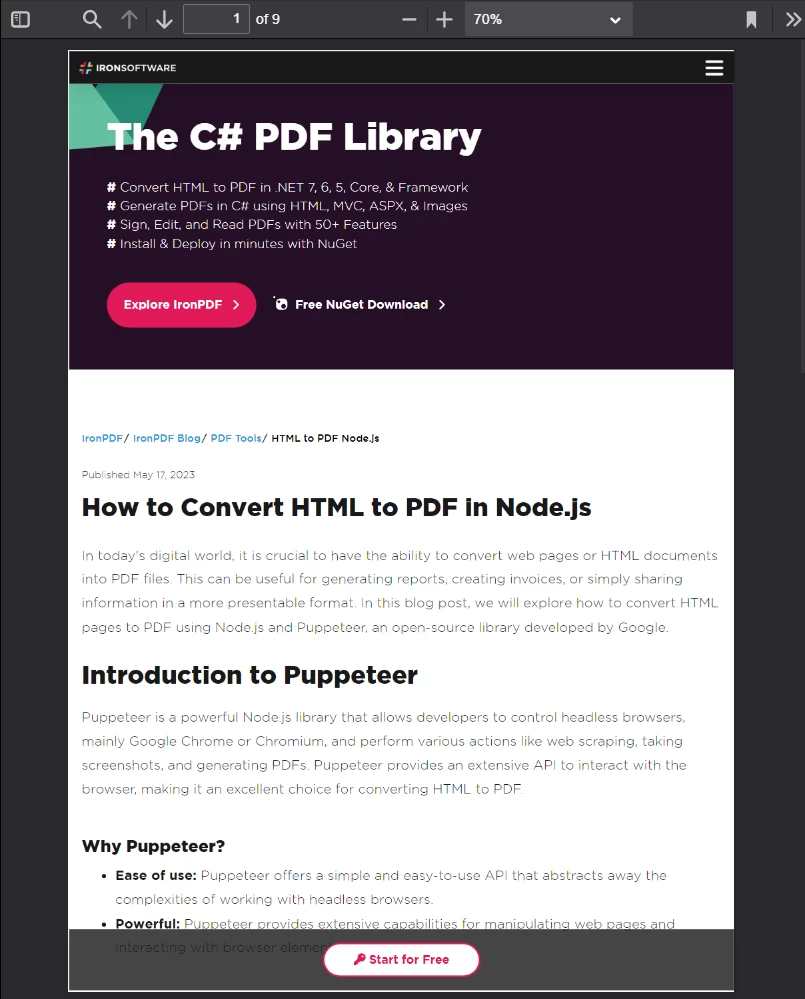
**Google Chrome で見栄えが良ければ、PDF に変換したときにも見栄えが良くなります。 これには、CSSおよびJavaScriptを多用したページデザインが含まれます。
URLからPDFファイルを作成
IronPDFは、あらゆるサイズと複雑さのHTML文字列およびHTMLファイルを変換できます。 ただし、生のマークアップを文字列やファイルから使用するだけにとどまりません。 IronPDFはURLからHTMLをリクエストすることもできます。
次の Wikipedia 記事をご覧ください:https://en.wikipedia.org/wiki/PDF。

標準準拠のウェブブラウザに表示されるPDF形式に関するウィキペディアの記事。
このWikipediaの記事をPDFに変換するには、次のソースコードを使用してください:
import {PdfDocument} from "@ironsoftware/ironpdf";
import('./config.js');
// Convert the Web Page to a pixel-perfect PDF file.
const pdf = await PdfDocument.fromUrl("https://en.wikipedia.org/wiki/PDF");
// Save the document.
await pdf.saveAs("url-to-pdf.pdf");上記では、PdfDocument.fromUrlを使用して、数行のコードでウェブページをPDFに変換します。 IronPDFは、ウェブアドレスのHTMLコードを取得し、それをシームレスにレンダリングします。 HTMLファイルやテキスト文字列は必要ありません!
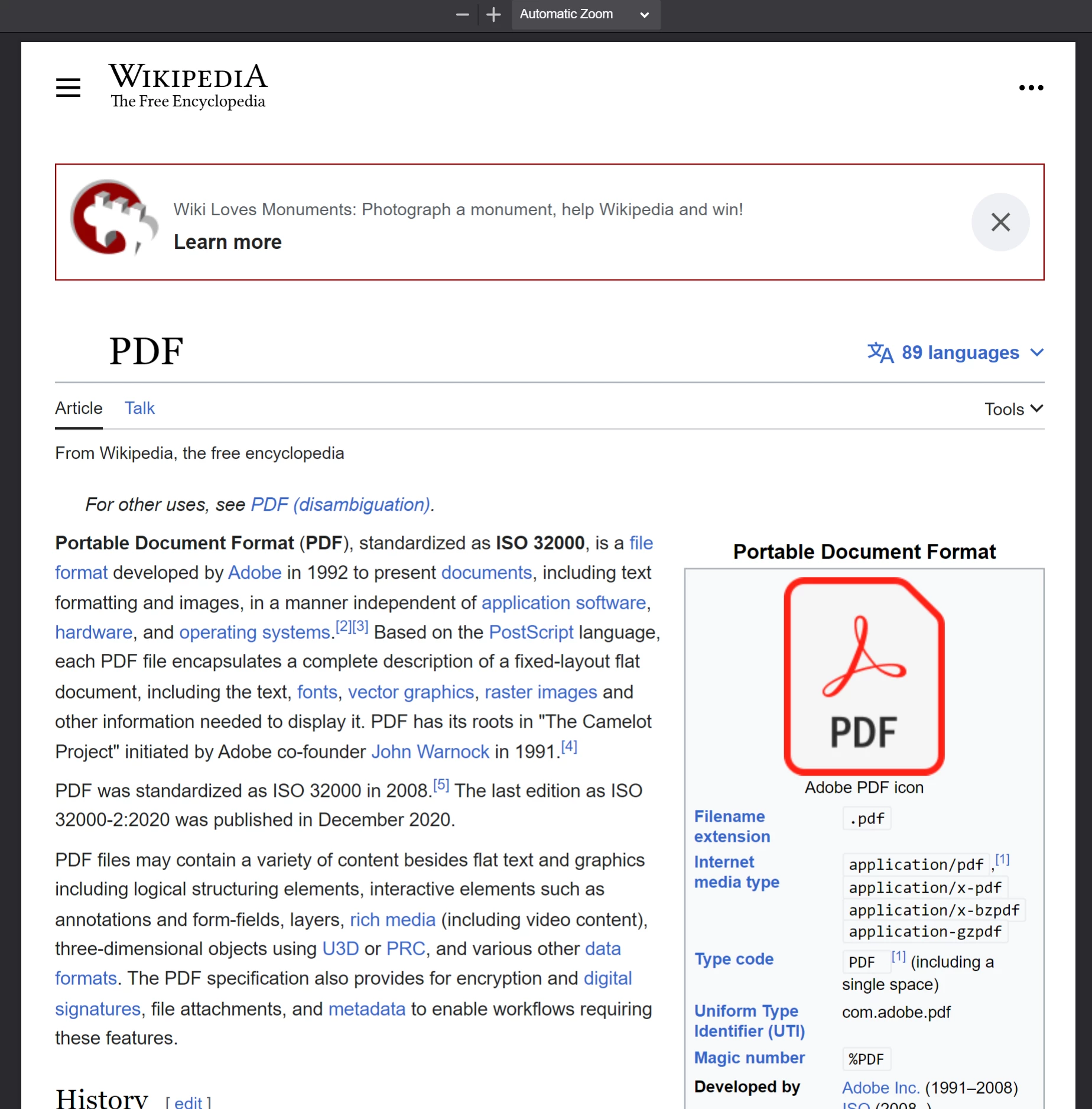
Wikipediaの記事に対してPdfDocument.fromUrlを呼び出して生成されたPDF。 元のウェブページとの類似点に注目してください。
ZipアーカイブからPDFファイルを作成
PdfDocument.fromZipを使用して、圧縮(zip)ファイルにある特定のHTMLファイルをPDFに変換します。
例えば、プロジェクトディレクトリ内に以下の内部構造を持つZipファイルがあると仮定します。
html-zip.zip
├─ index.html
├─ style.css
├─ logo.pngindex.htmlファイルには、以下のコードが含まれています:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Hello world!</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>Hello from IronPDF!</h1>
<a href="https://ironpdf.com/nodejs/">
<img src="logo.png" alt="IronPDF for Node.js">
</a>
</body>
</html><!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Hello world!</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>Hello from IronPDF!</h1>
<a href="https://ironpdf.com/nodejs/">
<img src="logo.png" alt="IronPDF for Node.js">
</a>
</body>
</html>style.css は5つのCSSルールを宣言します:
@font-face {
font-family: 'Gotham-Black';
src: url('gotham-black-webfont.eot?') format('embedded-opentype'), url('gotham-black-webfont.woff2') format('woff2'), url('gotham-black-webfont.woff') format('woff'), url('gotham-black-webfont.ttf') format('truetype'), url('gotham-black-webfont.svg') format('svg');
font-weight: normal;
font-style: normal;
font-display: swap;
}
body {
display: flex;
flex-direction: column;
justify-content: center;
margin-left: auto;
margin-right: auto;
margin-top: 200px;
margin-bottom: auto;
color: white;
background-color: black;
text-align: center;
font-family: "Helvetica"
}
h1 {
font-family: "Gotham-Black";
margin-bottom: 70px;
font-size: 32pt;
}
img {
width: 400px;
height: auto;
}
p {
text-decoration: underline;
font-size: smaller;
}最後に、logo.pngには当社製品のロゴが表示されています。

仮想HTML zipファイル内のサンプル画像。
fromZip メソッドを呼び出す際、最初の引数にzipの有効なパスを指定するとともに、変換したいzip内のHTMLファイルの名前をmainHtmlFileプロパティに設定するJSONオブジェクトを指定してください。
私たちは同様の方法でzipフォルダー内のindex.htmlファイルを変換します。
import {PdfDocument} from "@ironsoftware/ironpdf";
import('./config.js');
// Render the HTML string
PdfDocument.fromZip("./html-zip.zip", {
mainHtmlFile: "index.html"
}).then(async (pdf) => {
return await pdf.saveAs("html-zip-to-pdf.pdf");
});
** PdfDocument.fromZip 関数を使用してPDFを作成します。 この関数は、ZIPファイルに含まれるHTMLコードを、その中に含まれるアセットと共に正常にレンダリングします。
高度なHTMLからPDFへの生成オプション
ChromePdfRenderOptions インターフェースは、Node開発者がライブラリのHTMLレンダリング動作を変更できるようにします。 そこに公開されているプロパティは、PDFの描画前にPDFの外観を詳細にカスタマイズできるようにします。 さらに、これらは特定のHTML-PDF変換のエッジケースを処理することを可能にします。
IronPDFは、最初にいくつかのデフォルトのChromePdfRenderOptions値を使用して新しいPDFをレンダリングします。 あなた自身でこれらのプリセット値を確認するには、defaultChromePdfRenderOptions 関数を呼び出してください。
// Retrieve a ChromePdfRenderOptions object with default settings.
var options = defaultChromePdfRenderOptions();このセクションでは、ChromePdfRenderOptionsインターフェースを使用する必要がある最も一般的なHTMLからPDFへのレンダリングユースケースを簡単に説明します。
各サブセクションは、事前設定された値から始まり、目標結果を達成するために必要に応じてそれらを変更します。
PDF生成出力のカスタマイズ
カスタムヘッダーとフッターを追加
textHeaderおよびtextFooterプロパティを使用すると、新しくレンダリングされたPDFにカスタムヘッダーやフッターコンテンツを付加できます。
以下の例では、テキストコンテンツからカスタムヘッダーとフッターを作成し、Google検索のホームページのPDFバージョンを作成します。 私たちはこのコンテンツをページの本文から分けるために区切り線を使用します。 ヘッダーとフッターには異なるフォントを使用して、区別をより明確にしています。
import {PdfDocument, defaultChromePdfRenderOptions, AffixFonts} from "@ironsoftware/ironpdf";
import('./config.js');
var options = defaultChromePdfRenderOptions();
// Build a Custom Text-Based Header
options.textHeader = {
centerText: "https://www.adobe.com",
dividerLine: true,
font: AffixFonts.CourierNew,
fontSize: 12,
leftText: "URL to PDF"
};
// Build a custom Text-Based Footer
options.textFooter = {
centerText: "IronPDF for Node.js",
dividerLine: true,
fontSize: 14,
font: AffixFonts.Helvetica,
rightText: "HTML to PDF in Node.js"
};
// Render a PDF from an HTML File
PdfDocument.fromUrl("https://www.google.com/", {renderOptions: options}).then(async (pdf) => {
return await pdf.saveAs("add-custom-headers-footers-1.pdf");
});このソースコードはこのPDFを生成します:
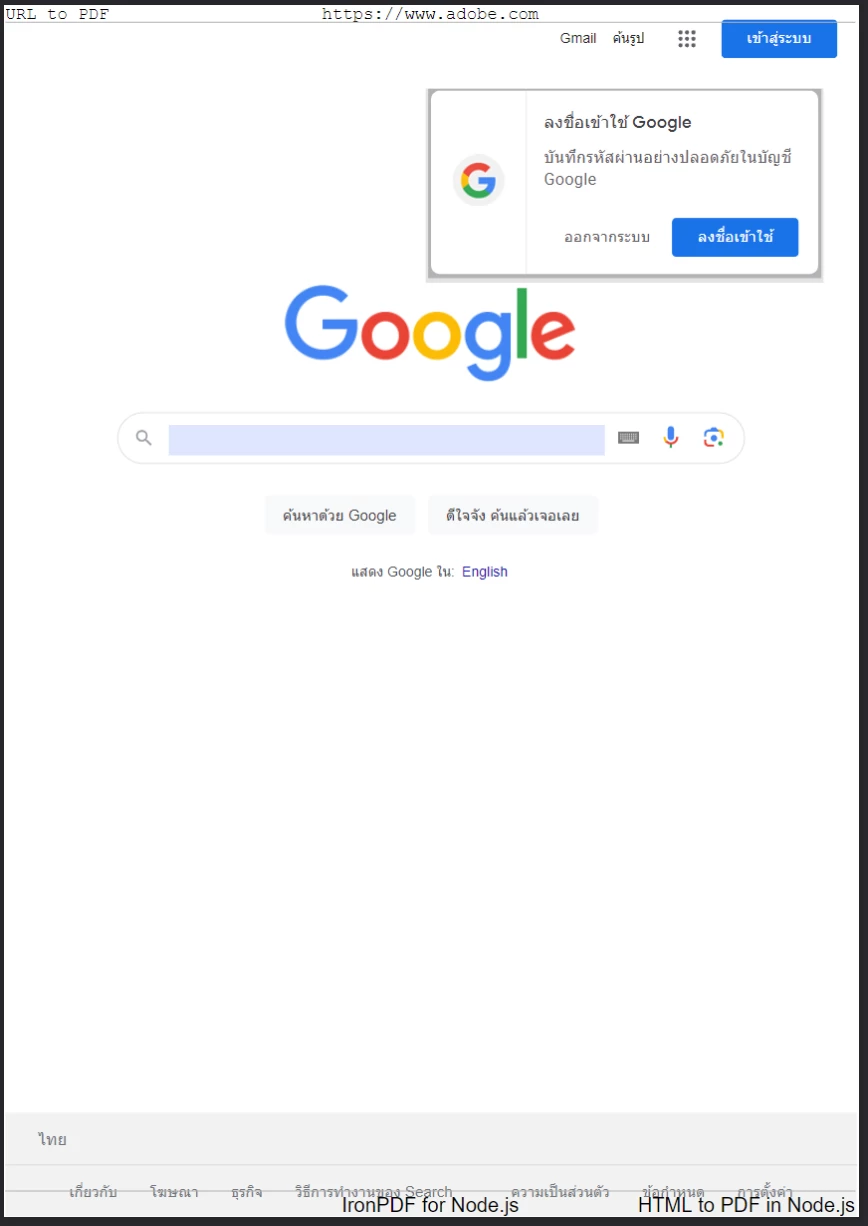
Googleのホームページから生成されたPDF形式の新しいページが作成されました。 追加のヘッダーとフッターの含有に注目してください。
レイアウト、位置、ヘッダーおよびフッターに含まれるコンテンツをさらに詳細に制御するために、テキストの代わりに生のHTMLを使用してそれらを定義することもできます。
次のコードブロックでは、ヘッダーおよびフッターにリッチなコンテンツを組み込むためにHTMLを使用します。 ヘッダーにページのURLを太字で中央揃えにします。 フッターには、ロゴを埋め込み、中央に配置します。
import {PdfDocument, defaultChromePdfRenderOptions} from "@ironsoftware/ironpdf";
import('./config.js');
var options = defaultChromePdfRenderOptions();
options.htmlHeader = {
htmlFragment: "<strong>https://www.google.com/</strong>",
dividerLine: true,
dividerLineColor: "blue",
loadStylesAndCSSFromMainHtmlDocument: true,
};
options.htmlFooter = {
htmlFragment: "<img src='logo.png' alt='IronPDF for Node.js' style='display: block; width: 150px; height: auto; margin-left: auto; margin-right: auto;'>",
dividerLine: true,
loadStylesAndCSSFromMainHtmlDocument: true
};
// Render a PDF from an HTML File
await PdfDocument.fromUrl("https://www.google.com/", {renderOptions: options}).then(async (pdf) => {
return await pdf.saveAs("add-html-headers-footers.pdf");
});以下の画像は、これらの変更の結果を示しています。

IronPDF for Node.js は、HTML ページを PDF に変換する際にカスタマイズを適用できます。
余白、ページサイズ、ページの向き、カラーを設定
IronPDFは新しく変換されたPDFのために、カスタムページの余白、ページサイズ、およびページの向きを定義する追加設定をサポートしています。
import {PdfDocument, defaultChromePdfRenderOptions, PaperSize, FitToPaperModes, PdfPaperOrientation} from "@ironsoftware/ironpdf";
import('./config.js');
var options = defaultChromePdfRenderOptions();
// Set top, left, right, and bottom page margins in millimeters.
options.margin = {
top: 50,
bottom: 50,
left: 60,
right: 60
};
options.paperSize = PaperSize.A5;
options.fitToPaperMode = FitToPaperModes.FitToPage;
options.paperOrientation = PdfPaperOrientation.Landscape;
options.grayScale = true;
// Create a PDF from the Google.com Home Page
PdfDocument.fromUrl("https://www.google.com/", {renderOptions: options}).then(async (pdf) => {
return await pdf.saveAs("set-margins-and-page-size.pdf");
});上記のコードブロックでは、IronPDFを設定して、グーグルのホームページPDFを風景モードで、グレースケールで生成し、最低50ミリメートルの余白を確保します。 コンテンツをA5用紙サイズに合わせるように設定しました。
動的なウェブページからPDFを生成
ページ読み込み時にすぐに利用できないコンテンツを含むWebページの場合、特定の条件が満たされるまでそのページのコンテンツのレンダリングを一時停止する必要があるかもしれません。
たとえば、開発者がページの読み込み完了後15秒後にのみ表示されるコンテンツを含むPDFを生成したい場合があります。 別の場合、この同じコンテンツは、複雑なクライアントサイドコードが実行されるときにのみ表示されることがあります。
これらの特殊ケース(および他の多くのケース)に対処するために、IronPDF for Node.js は WaitFor メカニズムを定義しています。 開発者は、このプロパティをChromePdfRenderOptions設定に含めることで、IronPDFのChrome Renderingエンジンに特定のイベントが発生した際にページの内容を変換するよう指示できます。
以下のコードブロックは、IronPDF がホームページの内容を PDF としてキャプチャする前に20秒間待機するように設定します:
import {PdfDocument, defaultChromePdfRenderOptions, WaitForType} from "@ironsoftware/ironpdf";
import('./config.js');
// Configure the Chrome Renderer to wait until 20 seconds has passed
// before rendering the web page as a PDF.
var options = defaultChromePdfRenderOptions();
options.waitFor = {
type: WaitForType.RenderDelay,
delay: 20000
}
PdfDocument.fromUrl("https://ironpdf.com/nodejs/", {renderOptions: options}).then(async (pdf) => {
return await pdf.saveAs("waitfor-renderdelay.pdf");
});次のコードブロックは、人気のあるSEOテキストエディタで要素が正常に選択できるまでIronPDFを待機するように設定します。
import {PdfDocument, defaultChromePdfRenderOptions, WaitForType} from "@ironsoftware/ironpdf";
import('./config.js');
// Configure the Chrome Renderer to wait up to 20 seconds for a specific element to appear
options.waitFor = {
type: WaitForType.HtmlElement,
htmlQueryStr: "div.ProseMirror",
maxWaitTime: 20000,
}
PdfDocument.fromUrl("https://app.surferseo.com/drafts/s/V7VkcdfgFz-dpkldsfHDGFFYf4jjSvvjsdf", {renderOptions: options}).then(async (pdf) => {
return await pdf.saveAs("waitfor-htmlelement.pdf");
});HTMLテンプレートからPDFを生成する
このチュートリアルの最終セクションでは、前のセクションで紹介した知識をすべて適用して、非常に実用的な自動化を実現します。具体的には、HTMLテンプレートを使用して1つまたは複数のPDFを生成します。
以下のセクションで使用するテンプレートは次のとおりです。 それは、置換可能なコンテンツのためのプレースホルダータグ(例:{COMPANY-NAME}、{FULL-NAME}、{INVOICE-NUMBER}など)を含むように、誰でもアクセス可能なこの請求書テンプレートから適応されました。

**請求書テンプレートのサンプル。 PDFに変換する前に、このテンプレートに動的なデータを追加するJavaScriptコードを追加します。
続行する前に、このHTMLテンプレートをダウンロードし、お好みのIDEで調べることができます。
次のソースコードブロックでは、HTMLテンプレートを新しいPdfDocumentオブジェクトにロードし、定義したプレースホルダーをダミーテストデータで置き換えた後、PdfDocumentオブジェクトをファイルシステムに保存します。
import {PdfDocument} from "@ironsoftware/ironpdf";
import('./config.js');
/**
* Loads an HTML template from the file system.
*/
async function getTemplateHtml(fileLocation) {
// Return promise for loading template file
return PdfDocument.fromFile(fileLocation);
}
/**
* Save the PDF document at a given location.
*/
async function generatePdf(pdf, location) {
return pdf.saveAs(location);
}
/**
* Use the PdfDocument.replaceText method to replace
* a specified placeholder with a provided value.
*/
async function addTemplateData(pdf, key, value) {
return pdf.replaceText(key, value);
}
const template = "./sample-invoice.html";
getTemplateHtml(template).then(async (doc) => { // load HTML template from file
await addTemplateData(doc, "{FULL-NAME}", "Lizbeth Presland");
await addTemplateData(doc, "{ADDRESS}", "678 Manitowish Alley, Portland, OG");
await addTemplateData(doc, "{PHONE-NUMBER}", "(763) 894-4345");
await addTemplateData(doc, "{INVOICE-NUMBER}", "787");
await addTemplateData(doc, "{INVOICE-DATE}", "August 28, 2023");
await addTemplateData(doc, "{AMOUNT-DUE}", "13,760.13");
await addTemplateData(doc, "{RECIPIENT}", "Celestyna Farmar"),
await addTemplateData(doc, "{COMPANY-NAME}", "BrainBook");
await addTemplateData(doc, "{TOTAL}", "13,760.13");
await addTemplateData(doc, "{AMOUNT-PAID}", "0.00");
await addTemplateData(doc, "{BALANCE-DUE}", "13,760.13");
await addTemplateData(doc, "{ITEM}", "Training Sessions");
await addTemplateData(doc, "{DESCRIPTION}", "60 Minute instruction");
await addTemplateData(doc, "{RATE}", "3,440.03");
await addTemplateData(doc, "{QUANTITY}", "4");
await addTemplateData(doc, "{PRICE}", "13,760.13");
return doc;
}).then(async (doc) => await generatePdf(doc, "html-template-to-pdf.pdf"));上記のソースは3つの非同期ヘルパー関数を定義しています。
getTemplateHtml:PdfDocument.fromHtmlメソッドを使用して、HTML テンプレートを新しいPdfDocumentオブジェクトに読み込みます。addTemplateData: 提供されたプレースホルダー(キーと呼ばれる)をその置換データの値に置き換えるために、PdfDocument.replaceTextメソッドを使用します。-
generatePdf: 指定されたファイル位置にPdfDocumentを保存します。さらに、HTMLテンプレートファイルの場所を保持するために
const template変数を宣言します。上記のソースコードから生成されたPDFは以下に示されています。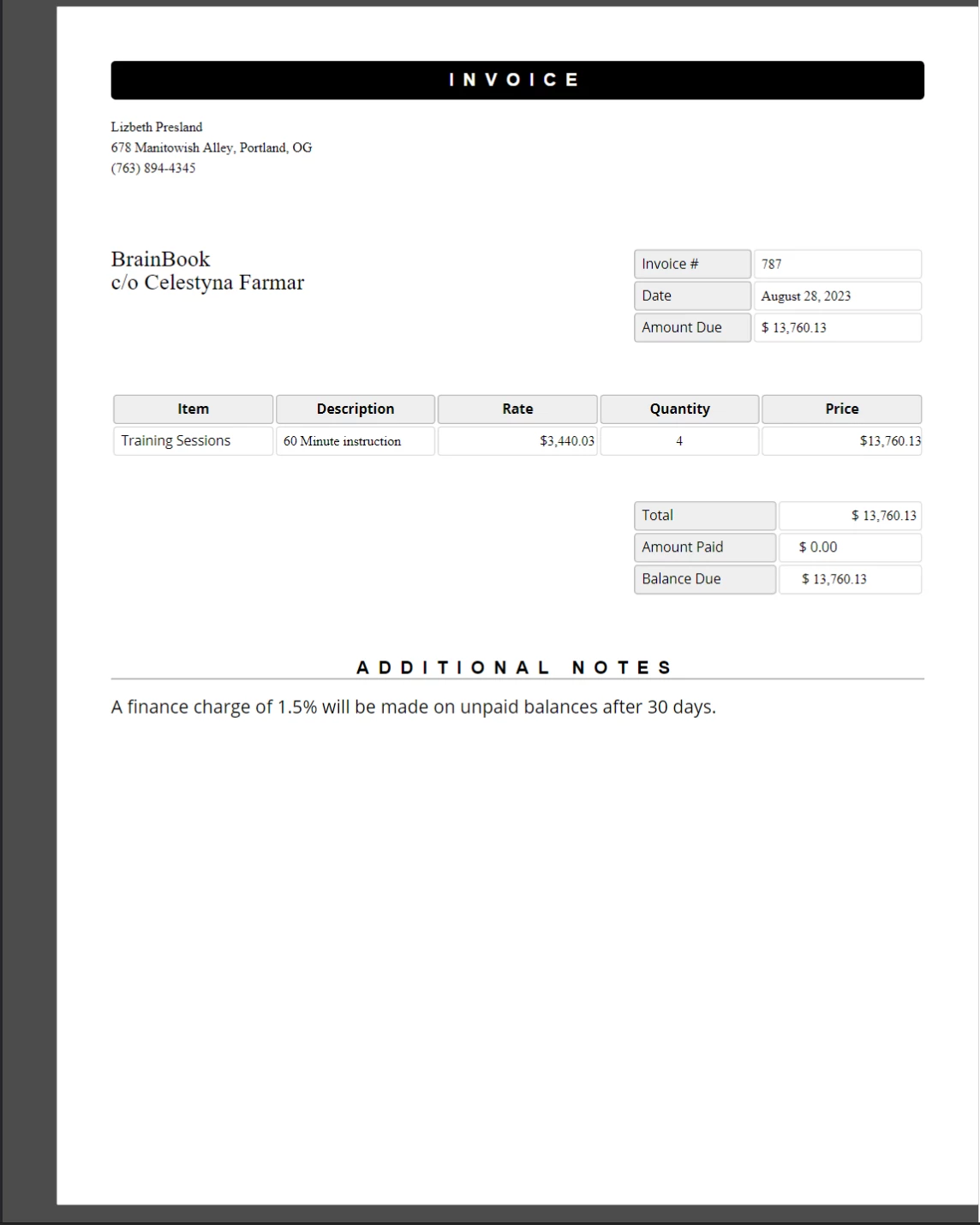
HTMLテンプレートで定義されたプレースホルダを実際のデータで置き換えて作成された新しいPDFドキュメント。 このドキュメントは、置換が行われなかった場合に予想されるCSSスタイルとレイアウトを保持しています。
さらなる読み物
このチュートリアルでは、IronPDFの高レベルAPI機能で可能なことの一端を紹介したに過ぎません。 これらの関連トピックを学習して、知識と理解を深めることを検討してください。
-
PdfGeneratorクラス: これは HTML、URL、Zip アーカイブ、その他のソースメディアからPdfDocumentオブジェクトを作成するための専用ユーティリティクラスです。 このクラスは、PdfDocumentクラスで定義されたPDFレンダリング機能を使用する際の実行可能な代替手段を提供します。 HttpLoginCredentials: 特定のクッキーが必要なウェブページや、パスワードで保護されているウェブページからPDFを生成する必要がある場合、このリファレンスは非常に役立ちます。
Darrius Serrantは、マイアミ大学でコンピュータサイエンスの学士号を取得しており、Iron SoftwareでフルスタックWebOpsマーケティングエンジニアとして働いています。若い頃からコーディングに魅了され、コンピューティングを神秘的でありながらアクセスしやすいものと見なし、それが創造性と問題解決のための完璧な媒体であると感じました。
Iron Softwareでは、新しいものを作り出し、複雑な概念を簡単にすることでより理解しやすくすることを楽しんでいます。彼は常駐の開発者の一人として、学生に教えることを志願し、自分の専門知識を次世代と共有しています。
Darriusにとって、彼の仕事は評価され、実際に影響があることで充実しています。









