ライブ環境でテストする
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
Node.js PDFライブラリ


開発者は、Node.jsでXML2JSとIronPDFを組み合わせることで、XMLデータの解析とPDF作成機能をアプリに簡単に組み込むことができます。 XML2JSという人気のあるNode.jsパッケージは、XMLデータをJavaScriptオブジェクトに変換するのを簡単にし、XML素材のプログラムによる操作と使用を促進します。 一方、IronPDFは、調整可能なページサイズ、余白、ヘッダーを持つ高品質なPDFドキュメントの作成を専門としています。HTML動的に作成された素材を含む。
開発者は現在、XML2JSおよびIronPDFを使用して、XMLデータソースから直接PDFレポート、請求書、またはその他の印刷可能な資料を動的に作成することができます。 Node.jsアプリケーションでPDF出力のためのXMLベースのデータ管理における正確性と柔軟性を確保し、ドキュメント生成プロセスを自動化するために、この統合は両方のライブラリの強みを活用します。
Node.jsパッケージのXML2JSは、シンプルなXMLを解析および作成するのを容易にします。(拡張可能なマークアップ言語)JavaScriptオブジェクトコンバーター。 XMLファイルやテキストを解析し、それらを構造化されたJavaScriptオブジェクトに変換する方法を提供することで、XMLドキュメントの処理を簡単にします。 この手順により、アプリケーションはXML属性のみの管理、テキストコンテンツ、名前空間、マージ属性またはキー属性、およびその他のXML固有の特性に関するオプションを提供することで、XMLデータをどのように解釈し使用するかについて自由度を得られます。
ライブラリは、大規模なXMLドキュメントや非同期解析が必要な状況に対応することができます。これは、同期解析および非同期解析操作の両方をサポートしているためです。 さらに、XML2JSは、XMLをJavaScriptオブジェクトに変換する際の検証およびエラー解決の仕組みを提供し、データ処理操作の安定性と信頼性を保証します。 すべてのことを考慮すると、Node.js アプリケーションはしばしば XML2JS を使用して、XMLベースのデータソースを統合し、ソフトウェアを構成し、データ形式を変更し、自動テスト手順を効率化します。
XML2JSは、以下の機能によりNode.jsアプリケーションでXMLデータを扱うための柔軟で不可欠なツールです。
XML2JSを使用することで、開発者はXML文字列やファイルをJavaScriptオブジェクトに変換する処理を簡素化し、よく知られたJavaScript構文を用いてXMLデータに素早くアクセスし、操作することができます。
JavaScriptアプリケーション内でXMLデータを扱うことは、XMLデータを構造化されたJavaScriptオブジェクトにスムーズに変換することで簡単になります。
XML2JSでは、XMLデータの解析およびJavaScriptオブジェクトへの変換方法を変更するためのさまざまな設定オプションが提供されています。 これには、名前空間、テキストコンテンツ、属性、およびその他の事項の管理が含まれます。
往復データ変更は、JavaScriptオブジェクトを単純なXML文字列に変換する双方向変換機能によって可能になります。
大量のXMLドキュメントは、ライブラリの非同期パーシングプロセスのサポートにより、アプリケーションのイベントループを妨げることなくうまく処理できます。
XML2JSは、XMLの解析および変換プロセス中に発生する可能性のある検証問題や解析エラーを処理するために、強力なエラー処理手法を提供します。
それはJavaScriptのPromiseとよく連携し、XMLデータを処理する非同期コードパターンをより明確かつ容易に取り扱うことを可能にします。
デベロッパーは、カスタムパースフックを作成することにより、XMLパースの動作を傍受して変更する特別なオプションを可能にし、データ処理プロセスの柔軟性を高めることができます。
ライブラリをインストールし、ニーズに合わせて設定することが、Node.jsアプリケーションでXML2JSを使用するための最初のステップです。 これはXML2JSを設定して作成するための詳細な手順です。
まず、npmとNode.jsがインストールされていることを確認してください。XML2JSはnpmでインストールできます。
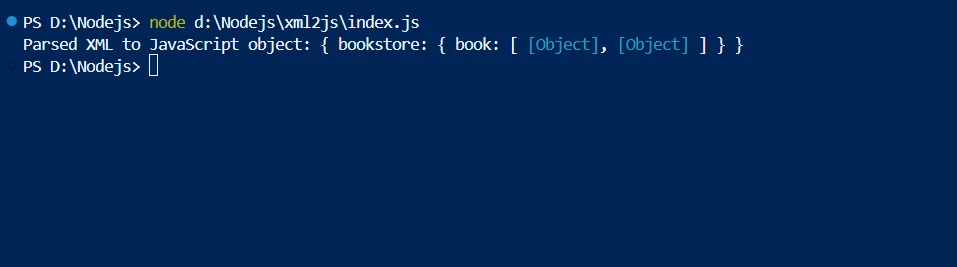
npm install xml2js以下は、XML2JSを使用してXMLテキストをJavaScriptオブジェクトに解析する方法の簡単な例です。
const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
console.log('Parsed XML to JavaScript object:', result);
});
XML2JSは、解析の動作を変更できるようにする設定オプションとデフォルト設定の範囲を提供します。 以下は、XML2JSのデフォルト解析設定を設定する方法の例です。
const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser with options
const parser = new xml2js.Parser({
explicitArray: false, // Convert child elements to objects instead of arrays when there is only one child
trim: true, // Trim leading/trailing whitespace from text nodes
});
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
console.log('Parsed XML to JavaScript object with options:', result);
});XML2JSは非同期解析をサポートしており、イベントループを止めることなく大きなXMLドキュメントを管理するのに役立ちます。以下にXML2JSでasync/await構文を使用する方法の例を示します。
const xml2js = require('xml2js');
// Example XML content (assume it's loaded asynchronously, e.g., from a file)
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Async function to parse XML content
async function parseXml(xmlContent) {
try {
const result = await parser.parseStringPromise(xmlContent);
console.log('Parsed XML to JavaScript object (async):', result);
} catch (err) {
console.error('Error parsing XML (async):', err);
}
}
// Call async function to parse XML content
parseXml(xmlContent);Node.jsアプリケーションでIronPDFとXML2JSを使用するには、まずXMLデータを読み込み、その処理された内容からPDFドキュメントを作成する必要があります。 これは、これらのライブラリをインストールおよび構成するのに役立つ詳細な手順です。
についてIronPDFライブラリは、PDFを操作するための強力なNode.jsライブラリです。 その目的は、HTMLコンテンツを優れた品質のPDFドキュメントに変換することです。 それは、HTML、CSS、およびその他のJavaScriptファイルを、元のオンラインコンテンツを損なうことなく適切にフォーマットされたPDFに変換するプロセスを合理化します。 これは、請求書、証明書、レポートなどの動的で印刷可能なドキュメントを作成する必要があるWebアプリケーションに非常に役立つツールです。
IronPDFには、カスタマイズ可能なページ設定、ヘッダー、フッター、フォントや画像を挿入する機能を含むいくつかの機能があります。 複雑なレイアウトやスタイルをサポートし、すべてのテスト出力PDFが指定されたデザインに従うようにします。 さらに、IronPDFはHTML内でのJavaScriptの実行を制御し、動的でインタラクティブなコンテンツを正確にレンダリングすることを可能にします。
HTMLからのPDF生成
HTML、CSS、JavaScriptをPDFに変換。 メディアクエリとレスポンシブデザインの2つの最新ウェブ標準をサポート。 HTMLとCSSを使用してPDFの請求書、レポート、およびドキュメントを動的に装飾するのに役立ちます。
**PDF編集
既存のPDFにテキストや画像などを追加することができます。 PDFファイルからテキストと画像を抽出します。 複数のPDFを1つのファイルに結合します。PDFファイルを複数の個別の文書に分割します。 ヘッダー、フッター、注釈、透かしを追加。
**性能と信頼性
産業界では、高性能と高信頼性が望ましい設計特性である。 大きな文書セットを簡単に処理します。
Node.jsプロジェクトでPDFを操作するために必要なツールを得るには、IronPDFパッケージをインストールしてください。
npm install @ironsoftware/ironpdf例として、example.xmlという基本的なXMLファイルを生成しましょう。
<!-- example.xml -->
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>GeneratePdf.js Node.jsスクリプトを作成し、XMLファイルを読み込み、XML2JSを使用してJavaScriptオブジェクトに解析し、次にIronPDFを使用して解析されたデータオブジェクトからPDFを作成します。
// generatePdf.js
const fs = require('fs');
const xml2js = require('xml2js');
const IronPdf = require("@ironsoftware/ironpdf");
const fs = require('fs');
const document=IronPdf.PdfDocument;
var config=IronPdf.IronPdfGlobalConfig
config.setConfig({licenseKey:''});
// Function to read and parse XML
parseXml=async (filePath)=> {
const parser = new xml2js.Parser();
const xmlContent = fs.readFileSync(filePath, 'utf8');
return awaitparser.parseStringPromise(xmlContent);
}
// Function to generate HTML content from the parser object
function generateHtml(parsedXml) {
let htmlContent = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Bookstore</title>
<style>
body { font-family: Arial, sans-serif; }
.book { margin-bottom: 20px; }
</style>
</head>
<body>
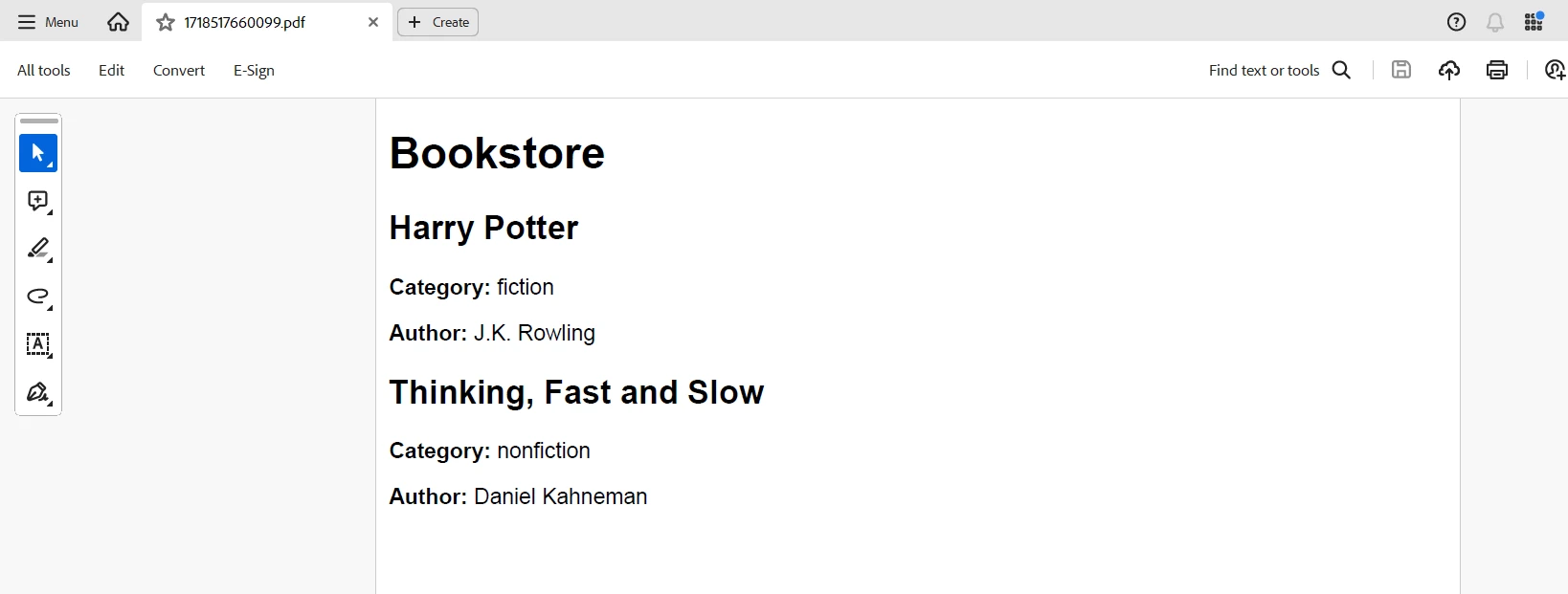
<h1>Bookstore</h1>
`;
// root node mapping
parsedXml.bookstore.book.forEach(book => {
htmlContent += `
<div class="book">
<h2>${book.title}</h2>
<p><strong>Category:</strong> ${book.$.category}</p>
<p><strong>Author:</strong> ${book.author}</p>
</div>
`;
});
htmlContent += `
</body>
</html>
`;
return htmlContent;
}
// Main function to generate PDF
generatePdf=async()=> {
try {
var parser = await parseXml('./example.xml');
const htmlContent = generateHtml(parser);
document.fromHtml(htmlContent).then((pdfres)=>{
const filePath = `${Date.now()}.pdf`;
pdfres.saveAs(filePath).then(()=>{
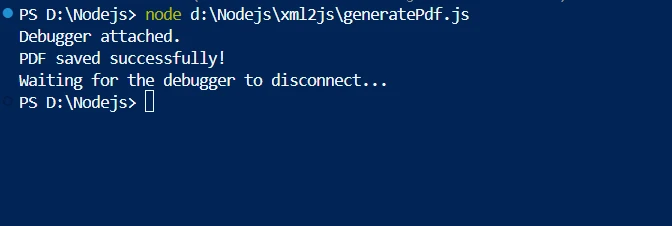
console.log('PDF saved successfully!');
}).catch((e)=>{
console.log(e);
});
});
} catch (error) {
console.error('Error:', error);
}
}
// Run the main function
generatePdf();XMLデータを変換し、複数のファイルをPDFドキュメントに解析する簡単な方法は、Node.jsアプリケーションでIronPDFとXML2JSを組み合わせることです。 XML2JSを使用して、Node.jsのfsモジュールを用いて最初にXMLファイルを読み取った後、複数のファイルのXMLコンテンツがJavaScriptオブジェクトに解析されます。 その後、基盤を形成するHTMLテキストPDFこの処理されたデータを使用して動的に生成されます。
スクリプトは、ファイルからXMLテキストを読み込み、xml2jsを使用してそれをJavaScriptオブジェクトに解析することから始まります。 解析されたデータオブジェクトから、カスタム関数がHTMLコンテンツを作成し、必要な要素(例えば、書店の著者やタイトル)で構成します。 このHTMLは、その後、IronPDFを使用してPDFバッファにレンダリングされます。 生成されたPDFはファイルシステムに保存されます。
IronPDFの効果的なHTMLからPDFへの変換機能とXML2JSの堅牢なXML解析機能を使用して、この方法はNode.jsアプリケーションでXMLデータからPDFを作成するための簡潔な方法を提供します。 その接続により、動的なXMLデータを印刷可能で整った形式のPDFドキュメントに変換することが可能になります。 これは、XMLソースからの自動ドキュメント生成を必要とするアプリケーションに最適です。
まとめると、XML2JSとIronPDFをNode.jsアプリケーションで組み合わせることにより、XMLデータを高品質なPDFドキュメントに変換するための強力で柔軟な方法が提供されます。 XML2JSを使用したJavaScriptオブジェクトへの効果的なXML解析により、データの抽出と操作が簡単になります。 データが解析された後、HTMLテキストに動的に変更することができ、そのHTMLテキストをIronPDFが簡単に適切に構造化されたPDFファイルに変換します。
XMLデータソースからレポート、請求書、証明書などのドキュメントを自動的に作成する必要があるアプリケーションは、この組み合わせが特に役立つでしょう。 開発者は、両方のライブラリの利点を利用することで、正確で美しいPDF出力を保証し、ワークフローを効率化し、ドキュメント生成タスクを扱うNode.jsアプリの能力を向上させることができます。
IronPDFは、Iron Softwareの非常に柔軟なシステムとスイートを活用しながら、開発者にさらに多くの機能と効率的な開発を提供します。
ライセンスオプションが明確でプロジェクトに特化している場合、開発者が最適なモデルを選択するのは容易です。 これらの機能により、開発者は使いやすく、効率的でまとまりのある方法でさまざまな問題を解決できます。
npm i @ironsoftware/ironpdf
クレジットカードは不要です
試用キーはメールに送信されるはずです。![]() 試用版申し込みフォームが
試用版申し込みフォームが
正常に送信されました。
もし届かない場合は、
support@ironsoftware.comにお問い合わせください。

無料で始めましょう
クレジットカードは不要です
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
30日間、完全に機能する製品をご利用いただけます。
数分で稼働させることができます。
製品トライアル期間中にサポートエンジニアリングチームへの完全アクセス





![]() クレジットカードやアカウント作成は不要です。
クレジットカードやアカウント作成は不要です。
試用キーはメールにあるはずです。
もしない場合は、
support@ironsoftware.comまでご連絡ください。

30分の個別デモを予約する。
契約なし、カード情報不要、義務なし。


10 .NET API製品オフィスドキュメントのために