
ライブ環境でテストする
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
Java PDF ライブラリ


この記事では、IronPDFライブラリーを使用して効率的なアプローチでJavaにPDFパーサーを作成します。
IronPDF for Javaは、PDFドキュメントの作成、読み取り、および操作を簡単かつ正確に行うことができるJavaのPDFライブラリです。 それは、IronPDF for .NETの成功に基づいて構築されており、異なるプラットフォーム全体で効率的な機能を提供します。 IronPDF for Javaは、高速でパフォーマンスが最適化されたIronPdfEngineを利用しています。
IronPDFを使用すると、PDFファイルからテキストや画像を抽出できるだけでなく、HTML文字列、ファイル、URL、画像を含むさまざまなソースからPDFを作成することも可能です。 さらに、新しいコンテンツを簡単に追加し、IronPDF を使用して署名を挿入し、PDF ドキュメントにメタデータを埋め込むことができます。 IronPDFはJava 8+、Scala、Kotlin用に特別に設計されており、Windows、Linux、クラウドプラットフォームに対応しています。
JavaでPDF解析プロジェクトを作成するには、次のツールが必要です:
Java IDE: Javaをサポートする任意のIDEを使用できます。開発に利用可能なJava IDEはいくつもあります。 ここでは、このチュートリアルはIntelliJ IDEを使用します。 NetBeans、Eclipseなどを使用できます。
Mavenプロジェクト: Mavenは依存関係の管理ツールであり、Javaプロジェクトを制御することを可能にします。 Java用のMavenはMaven公式ウェブサイトからダウンロードできます。 IntelliJのJava IDEには、Mavenのサポートが組み込まれています。
IronPDF - IronPDF for Java は複数の方法でダウンロードしてインストールできます。
pom.xmlファイルにIronPDFの依存関係を追加する。 :ProductInstallJava用の最新IronPDFパッケージについては、Mavenリポジトリのウェブサイトをご覧ください。
Iron Softwareの公式ダウンロードページからの直接ダウンロード。
pom.xmlファイルに追加してください。 <dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.5</version>
</dependency>すべての前提条件がインストールされると、最初のステップはPDFドキュメントを操作するために必要なIronPDFパッケージをインポートすることです。 Main.java ファイルの先頭に次のコードを追加してください:
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;IronPDFで利用可能ないくつかのメソッドは、使用するためにライセンスが必要です。 ライセンスを購入するか、無料トライアルでIronPDFを無料でお試しください。 次のようにキーを設定できます:
License.setLicenseKey("YOUR-KEY");既存のドキュメントを解析してコンテンツを抽出するには、PdfDocument クラスを使用します。 その静的なfromFileメソッドは、Javaプログラムで特定のパスと特定のファイル名からPDFファイルを解析するために使用されます。 コードは以下の通りです:
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));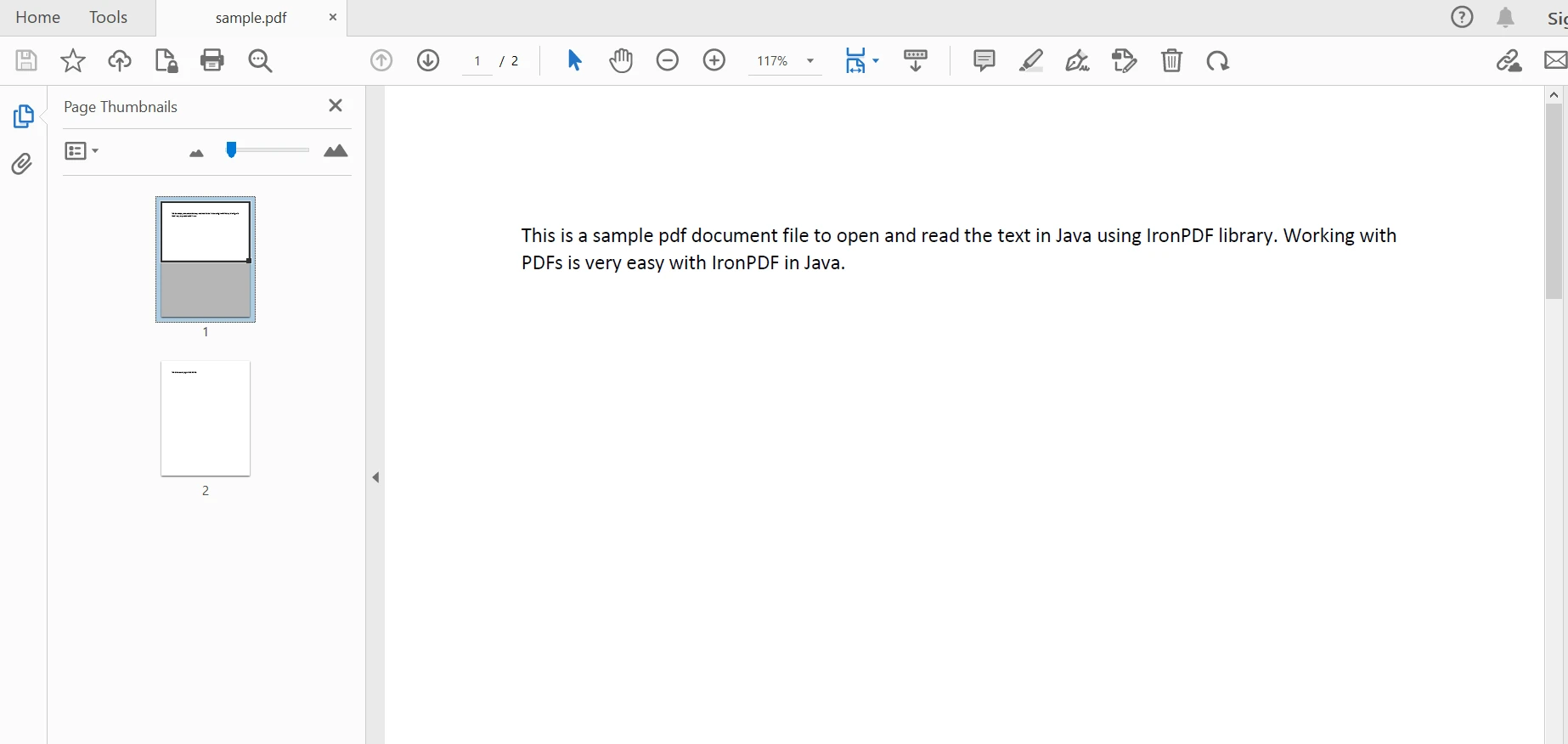
解析されたドキュメント
IronPDF for Java は、PDF ドキュメントからテキストを抽出する簡単な方法を提供します。 以下のコードスニペットは、PDFファイルからテキストデータを抽出するためのものです:
String extracted_text = parsedDocument.extractAllText();上記のコードは以下の出力を生成します:
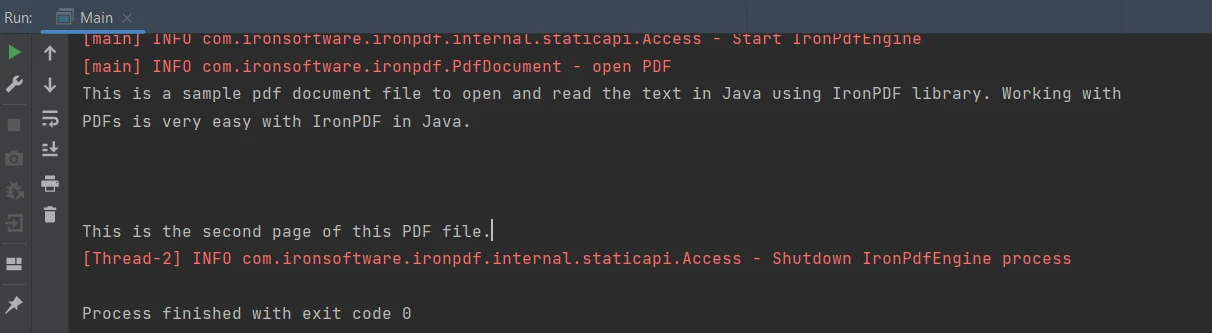
出力
IronPDF for Javaは既存のPDFだけでなく、新しいファイルを作成して解析し、コンテンツを抽出することもできます。 ここでは、このチュートリアルがURLからPDFファイルを作成し、そこからコンテンツを抽出します。 以下の例は、このタスクを達成する方法を示しています:
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extracted_text = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extracted_text);
}
}出力は以下の通りです:
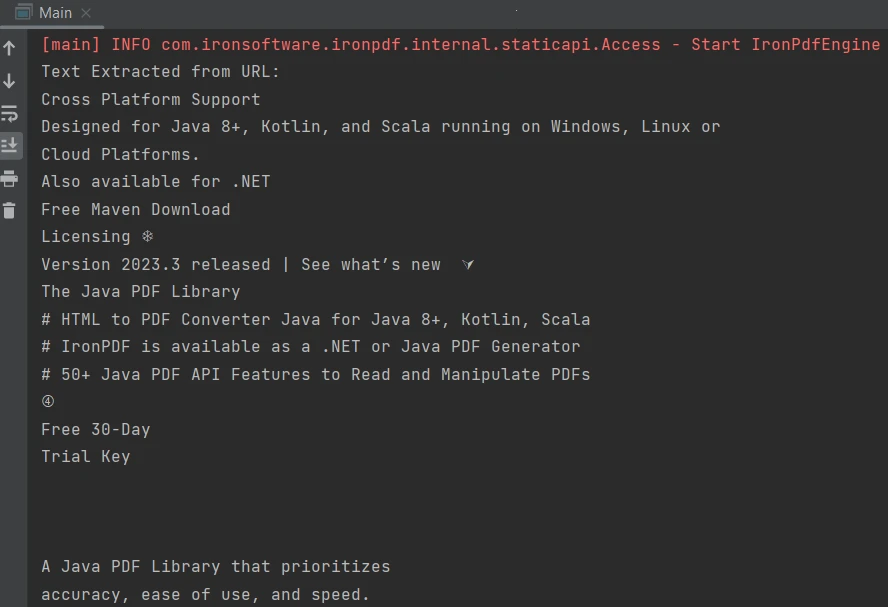
出力
IronPDFは、解析されたドキュメントからすべての画像を抽出する簡単なオプションも提供します。 ここでは、チュートリアルで前の例を使用して、PDFファイルから画像がどれほど簡単に抽出されるかを見ていきます。
import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}[extractAllImages](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllImages() メソッドは BufferedImages のリストを返します。 それぞれのBufferedImageは、ImageIO.writeメソッドを使用して指定した場所にPNG画像として保存できます。 解析されたPDFファイルには34枚の画像があり、すべての画像が完璧に抽出されています。

抽出された画像
PDFファイル内の表形式の境界からコンテンツを抽出することは、[extractAllTextメソッド](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText()を使用して、わずか1行のコードで簡単に行えます。 以下のコードスニペットは、PDFファイルのテーブルからテキストを抽出する方法を示しています:
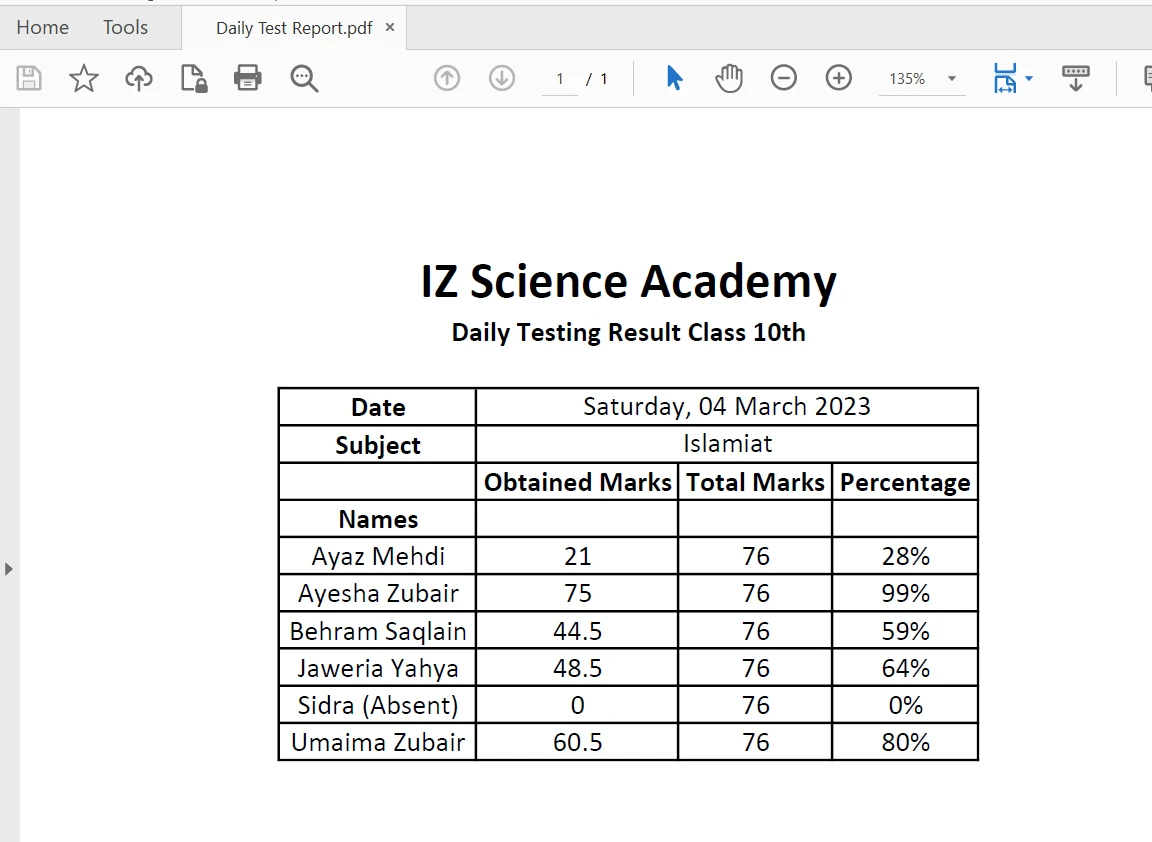
PDFの表
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extracted_text = parsedDocument.extractAllText();
System.out.println(extracted_text);出力は以下の通りです:
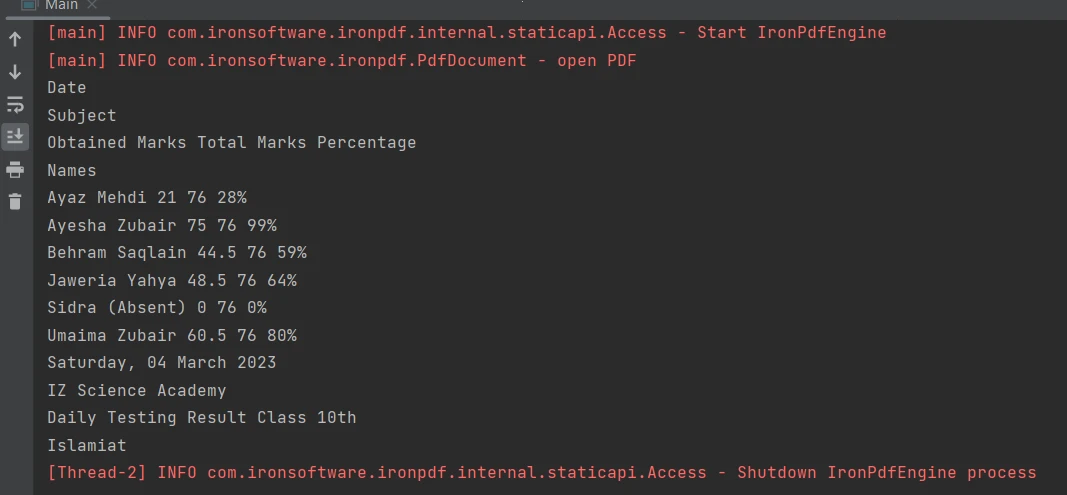
出力
この記事では、IronPDFを使用してJavaで既存のPDFドキュメントを解析するか、URLから新しいPDFパーサーファイルを作成してデータを抽出する方法を示しました。 ファイルを開いた後、PDFから表データ、画像、テキストを抽出することができ、抽出したテキストを後で使用するためにテキストファイルに追加することもできます。
Javaでプログラム的にPDFファイルを操作する方法についての詳細情報は、こちらのPDFファイル作成例をご覧ください。
Java 用 IronPDF ライブラリは、無料トライアルが利用可能で、開発目的には無料です。 しかし、商業利用の場合は、IronSoftwareを通じてライセンスが可能で、$749から始まります。
Darrius Serrantは、マイアミ大学でコンピュータサイエンスの学士号を取得しており、Iron SoftwareでフルスタックWebOpsマーケティングエンジニアとして働いています。若い頃からコーディングに魅了され、コンピューティングを神秘的でありながらアクセスしやすいものと見なし、それが創造性と問題解決のための完璧な媒体であると感じました。
Iron Softwareでは、新しいものを作り出し、複雑な概念を簡単にすることでより理解しやすくすることを楽しんでいます。彼は常駐の開発者の一人として、学生に教えることを志願し、自分の専門知識を次世代と共有しています。
Darriusにとって、彼の仕事は評価され、実際に影響があることで充実しています。

<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2025.4.4</version>
</dependency>
クレジットカードは不要です
試用キーはメールに送信されるはずです。![]() 試用版申し込みフォームが
試用版申し込みフォームが
正常に送信されました。
もし届かない場合は、
support@ironsoftware.comにお問い合わせください。

無料で始めましょう
クレジットカードは不要です
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
30日間、完全に機能する製品をご利用いただけます。
数分で稼働させることができます。
製品トライアル期間中にサポートエンジニアリングチームへの完全アクセス





![]() クレジットカードやアカウント作成は不要です。
クレジットカードやアカウント作成は不要です。
試用キーはメールにあるはずです。
もしない場合は、
support@ironsoftware.comまでご連絡ください。

30分の個別デモを予約する。
契約なし、カード情報不要、義務なし。


10 .NET API製品オフィスドキュメントのために