
ライブ環境でテストする
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
Java PDF ライブラリ


Google HTTP クライアントライブラリ for Java は、Java アプリケーションで HTTP リクエストを作成し、レスポンスを処理するプロセスを簡素化するために設計された堅牢なライブラリです。 それは、Google Apisの一部としてGoogleアプリエンジンとGoogle APIクライアントの一部です。Googleによって開発および維持されているこの強力なJavaライブラリは、広範なHTTPメソッドをサポートし、JSONデータモデルおよびXMLデータモデルとシームレスに統合されるため、webサービスと連携したい開発者にとって優れた選択肢です。 さらに、私たちは探求しますIronPDFJava用および、それをどのように統合するかを示すGoogle HTTP クライアント ライブラリHTTP応答データからPDFドキュメントを生成するために。
簡略化されたHTTPリクエスト: このライブラリはHTTPリクエストの作成と送信の複雑さの多くを抽象化し、開発者が扱いやすくします。
さまざまな認証方法へのサポート: 現代のAPIと連携するために不可欠なOAuth 2.0やその他の認証スキームをサポートしています。
JSONおよびXML解析: このライブラリはJSONおよびXMLの応答をJavaオブジェクトに自動的に解析し、ボイラープレートコードを削減します。
非同期リクエスト:ネットワーク操作をバックグラウンドスレッドにオフロードすることで、アプリケーションのパフォーマンスを向上させる非同期リクエストをサポートしています。
組み込みの再試行メカニズム: このライブラリには一時的なネットワークエラーを処理するための組み込みの再試行メカニズムが含まれており、アプリケーションの堅牢性を向上させるのに役立ちます。

Google HTTP クライアント ライブラリを Java で使用するには、フル クライアント ライブラリと必要な依存関係をプロジェクトに追加する必要があります。 Mavenを使用している場合は、次の依存関係をpom.xmlファイルに追加できます。
<dependencies>
<dependency>
<groupId>com.google.http-client</groupId>
<artifactId>google-http-client</artifactId>
<version>1.39.2</version>
</dependency>
<dependency>
<groupId>com.google.http-client</groupId>
<artifactId>google-http-client-jackson2</artifactId>
<version>1.39.2</version>
</dependency>
</dependencies>さまざまな例を通じて、Google HTTP Client Library for Java の基本的な使用法を探ってみましょう。
以下のコードは、Google HTTP クライアント ライブラリを使用して、完全なリクエスト コンテンツのシンプルな GET リクエストを行う方法を示しています:
import com.google.api.client.http.HttpRequest;
import com.google.api.client.http.HttpRequestFactory;
import com.google.api.client.http.HttpResponse;
import com.google.api.client.http.javanet.NetHttpTransport;
import com.google.api.client.http.GenericUrl;
public class HttpClientExample {
public static void main(String[] args) {
try {
HttpRequestFactory requestFactory = new NetHttpTransport().createRequestFactory();
GenericUrl url = new GenericUrl("https://jsonplaceholder.typicode.com/posts/1");
HttpRequest request = requestFactory.buildGetRequest(url);
HttpResponse response = request.execute();
System.out.println(response.parseAsString());
} catch (Exception e) {
e.printStackTrace();
}
}
}この例では、HttpRequestFactoryを作成し、それを使用してプレースホルダーAPIへのGETリクエストを構築および実行します。 ここでは、リクエストが失敗した場合に例外をキャッチして、コンパイルエラーの発生頻度を減らすためにtry-catchブロックを使用します。 次に、以下に示すコンソールにレスポンスを出力します。

次のコードは、JSONデータを使用してPOSTリクエストを行う方法を示しています:
import com.google.api.client.http.HttpRequest;
import com.google.api.client.http.HttpRequestFactory;
import com.google.api.client.http.HttpResponse;
import com.google.api.client.http.javanet.NetHttpTransport;
import com.google.api.client.http.GenericUrl;
import com.google.api.client.http.json.JsonHttpContent;
import com.google.api.client.json.JsonFactory;
import com.google.api.client.json.jackson2.JacksonFactory;
import java.util.HashMap;
import java.util.Map;
public class HttpClientExample {
public static void main(String[] args) {
try {
HttpRequestFactory requestFactory = new NetHttpTransport().createRequestFactory();
GenericUrl url = new GenericUrl("https://jsonplaceholder.typicode.com/posts");
Map<String, Object> jsonMap = new HashMap<>();
jsonMap.put("title", "foo");
jsonMap.put("body", "bar");
jsonMap.put("userId", 1);
JsonFactory jsonFactory = new JacksonFactory();
JsonHttpContent content = new JsonHttpContent(jsonFactory, jsonMap);
HttpRequest request = requestFactory.buildPostRequest(url, content);
HttpResponse response = request.execute();
System.out.println(response.parseAsString());
} catch (Exception e) {
e.printStackTrace();
}
}
}この例では、JSONオブジェクトを作成し、それをJsonHttpContentを使用してPOSTリクエストで送信します。その後、レスポンスがコンソールに出力されます。

IronPDFは、PDFドキュメントの作成、編集、および管理のプロセスを簡単にするJava開発者向けの強力なライブラリです。 HTMLをPDFに変換、既存のPDFファイルの操作、PDFからのテキストおよび画像の抽出を含む幅広い機能を提供します。
HTMLからPDFへの変換: 高品質でHTMLコンテンツをPDFに変換します。
既存のPDFの操作: 既存のPDFドキュメントを結合、分割、修正します。
テキストおよび画像抽出:PDFドキュメントからテキストと画像を抽出し、さらに処理します。
透かしと注釈: PDFファイルに透かし、注釈、その他の強化を追加します。
JavaプロジェクトでIronPDFを使用するには、IronPDFライブラリを含める必要があります。 IronPDFのウェブサイトからJARファイルをダウンロードするか、Mavenのようなビルドツールを使用してプロジェクトに含めることができます。 Mavenを使用しているユーザーは、次のコードをpom.xmlに追加してください。
<!--Adds IronPDF Java. Use the latest version in the version tag.-->
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2023.12.1</version>
</dependency>
<!--Adds the slf4j logger which IronPDF Java uses.-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.3</version>
</dependency>このセクションでは、Google HTTPクライアントライブラリを使用してウェブサービスからHTMLコンテンツを取得し、そのHTMLコンテンツをIronPDFを使用してPDFドキュメントに変換する方法を示します。
import com.google.api.client.http.HttpRequest;
import com.google.api.client.http.HttpRequestFactory;
import com.google.api.client.http.HttpResponse;
import com.google.api.client.http.javanet.NetHttpTransport;
import com.google.api.client.http.GenericUrl;
import com.google.api.client.json.JsonFactory;
import com.google.api.client.json.jackson2.JacksonFactory;
import com.google.api.client.http.json.JsonHttpContent;
import com.google.api.client.auth.oauth2.Credential;
import com.google.api.client.auth.oauth2.CredentialAccessMethod;
import com.google.api.client.auth.oauth2.TokenResponse;
import com.google.api.client.auth.oauth2.TokenResponseException;
import com.google.api.client.auth.oauth2.TokenRequest;
import com.google.api.client.auth.oauth2.AuthorizationCodeFlow;
import com.google.api.client.auth.oauth2.AuthorizationCodeRequestUrl;
import com.google.api.client.auth.oauth2.AuthorizationCodeTokenRequest;
import com.google.api.client.auth.oauth2.ClientParametersAuthentication;
import com.google.api.client.json.JsonGenerator;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import com.ironsoftware.ironpdf.PdfDocument;
public class HtmlToPdfExample {
public static void main(String[] args) {
try {
// Fetch HTML content using Google HTTP Client Library
HttpRequestFactory requestFactory = new NetHttpTransport().createRequestFactory();
GenericUrl url = new GenericUrl("https://jsonplaceholder.typicode.com/posts/1");
HttpRequest request = requestFactory.buildGetRequest(url);
HttpResponse response = request.execute();
String htmlContent = response.parseAsString();
// Convert HTML content to PDF using IronPDF
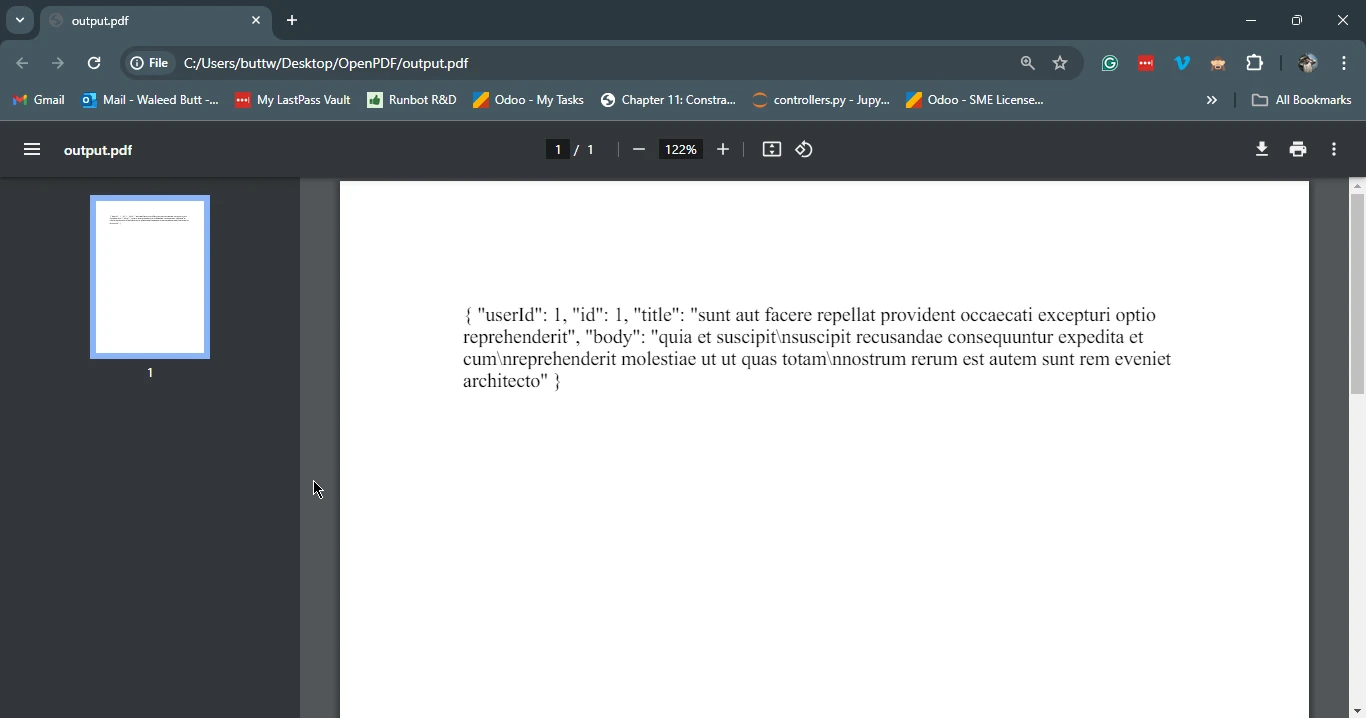
PdfDocument pdf = PdfDocument.renderHtmlAsPdf(htmlContent);
pdf.saveAs("output.pdf");
System.out.println("PDF created successfully!");
} catch (Exception e) {
e.printStackTrace();
}
}
}この例では、Google HTTP クライアント ライブラリを使用してプレースホルダー API から最初に HTML コンテンツを取得します。 次に、IronPDFを使用して取得したHTMLコンテンツをPDFドキュメントに変換し、output.pdfとして保存します。
Google HTTP クライアントライブラリ for Java は、Web サービスとやり取りするための強力なツールであり、簡素化された HTTP リクエスト、多様な認証方法のサポート、JSON および XML 解析とのシームレスな統合、さまざまな Java 環境への互換性を提供します。 IronPDFと組み合わせることで、開発者はウェブサービスからHTMLコンテンツを簡単に取得し、PDFドキュメントに変換することができます。これにより、レポート生成からウェブアプリケーション用のダウンロード可能なコンテンツ作成まで、さまざまなアプリケーションに対する完全なライブラリーを可能にします。 これらの2つのライブラリを活用することで、Java開発者はアプリケーションの機能を大幅に強化し、コードの複雑さを軽減できます。
以下をご参照くださいリンク.

<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2025.3.6</version>
</dependency>
クレジットカードは不要です
試用キーはメールに送信されるはずです。![]() 試用版申し込みフォームが
試用版申し込みフォームが
正常に送信されました。
もし届かない場合は、
support@ironsoftware.comにお問い合わせください。

無料で始めましょう
クレジットカードは不要です
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
30日間、完全に機能する製品をご利用いただけます。
数分で稼働させることができます。
製品トライアル期間中にサポートエンジニアリングチームへの完全アクセス





![]() クレジットカードやアカウント作成は不要です。
クレジットカードやアカウント作成は不要です。
試用キーはメールにあるはずです。
もしない場合は、
support@ironsoftware.comまでご連絡ください。

30分の個別デモを予約する。
契約なし、カード情報不要、義務なし。


10 .NET API製品オフィスドキュメントのために