

PDFから埋め込まれたテキストと画像を抽出する方法

埋め込まれたテキストや画像の抽出は、ドキュメント内のテキストコンテンツやグラフィック要素を取得することを含みます。 このプロセスにより、ユーザーはコンテンツにアクセスして編集、検索、またはテキストを他の形式に変換し、画像を再利用または分析のために保存することができます。
PDFからテキストと画像を抽出するには、IronPDFを使用してください。 抽出された画像はディスクに保存することができ、新しくレンダリングされたドキュメントに埋め込むために別の画像形式に変換することもできます。
IronPDFを始めましょう
今日から無料トライアルでIronPDFをあなたのプロジェクトで使い始めましょう。
PDFから埋め込まれたテキストと画像を抽出する方法
- IronPdf C# ライブラリをダウンロード
- テキストと画像抽出のためにPDFドキュメントを準備します。
- テキストを抽出するには
ExtractAllTextメソッドを使用します - 画像を抽出するには
ExtractAllImagesメソッドを使用します - 特定のページからテキストと画像を抽出するように指定
テキスト抽出の例
テキスト抽出は、新しくレンダリングされたPDF文書と既存のPDF文書の両方で実行できます。 ドキュメントから埋め込まれたテキストを抽出するには、ExtractAllText メソッドを使用します。 このメソッドは、指定されたPDF内のすべてのテキストを含む文字列を返します。 ページは、4つ連続した Environment.NewLinesPages で区切られています。 私はWikipediaサイトからレンダリングしたサンプルPDFを使用しましょう。
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text.csusing IronPdf;
using System.IO;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text
string text = pdf.ExtractAllText();
// Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text);Imports IronPdf
Imports System.IO
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text
Private text As String = pdf.ExtractAllText()
' Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text)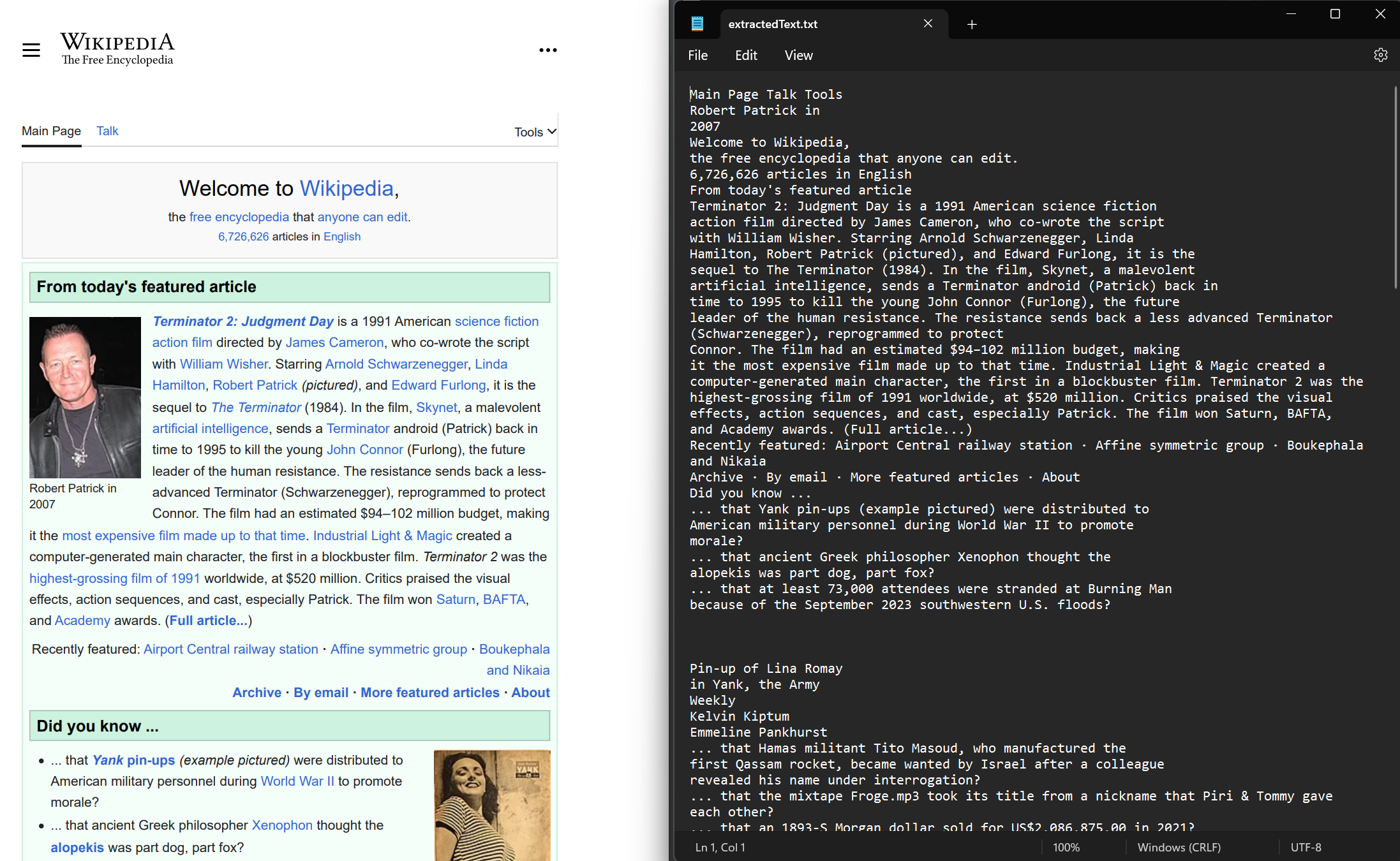
行と文字ごとにテキストを抽出
各PDFページ内で、テキスト行および文字の座標を取得することが可能です。 まず、PDFからページを選択し、LinesプロパティとCharactersプロパティにアクセスします。 座標は上、右、下、左の値として配置され、テキストの位置を表します。
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-by-line-character.csusing IronPdf;
using System.IO;
using System.Linq;
// Open PDF from file
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text by lines
var lines = pdf.Pages[0].Lines;
// Extract text by characters
var characters = pdf.Pages[0].Characters;
File.WriteAllLines("lines.txt", lines.Select(l => $"at Y={l.BoundingBox.Bottom:F2}: {l.Contents}"));Imports IronPdf
Imports System.IO
Imports System.Linq
' Open PDF from file
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text by lines
Private lines = pdf.Pages(0).Lines
' Extract text by characters
Private characters = pdf.Pages(0).Characters
File.WriteAllLines("lines.txt", lines.Select(Function(l) $"at Y={l.BoundingBox.Bottom:F2}: {l.Contents}"))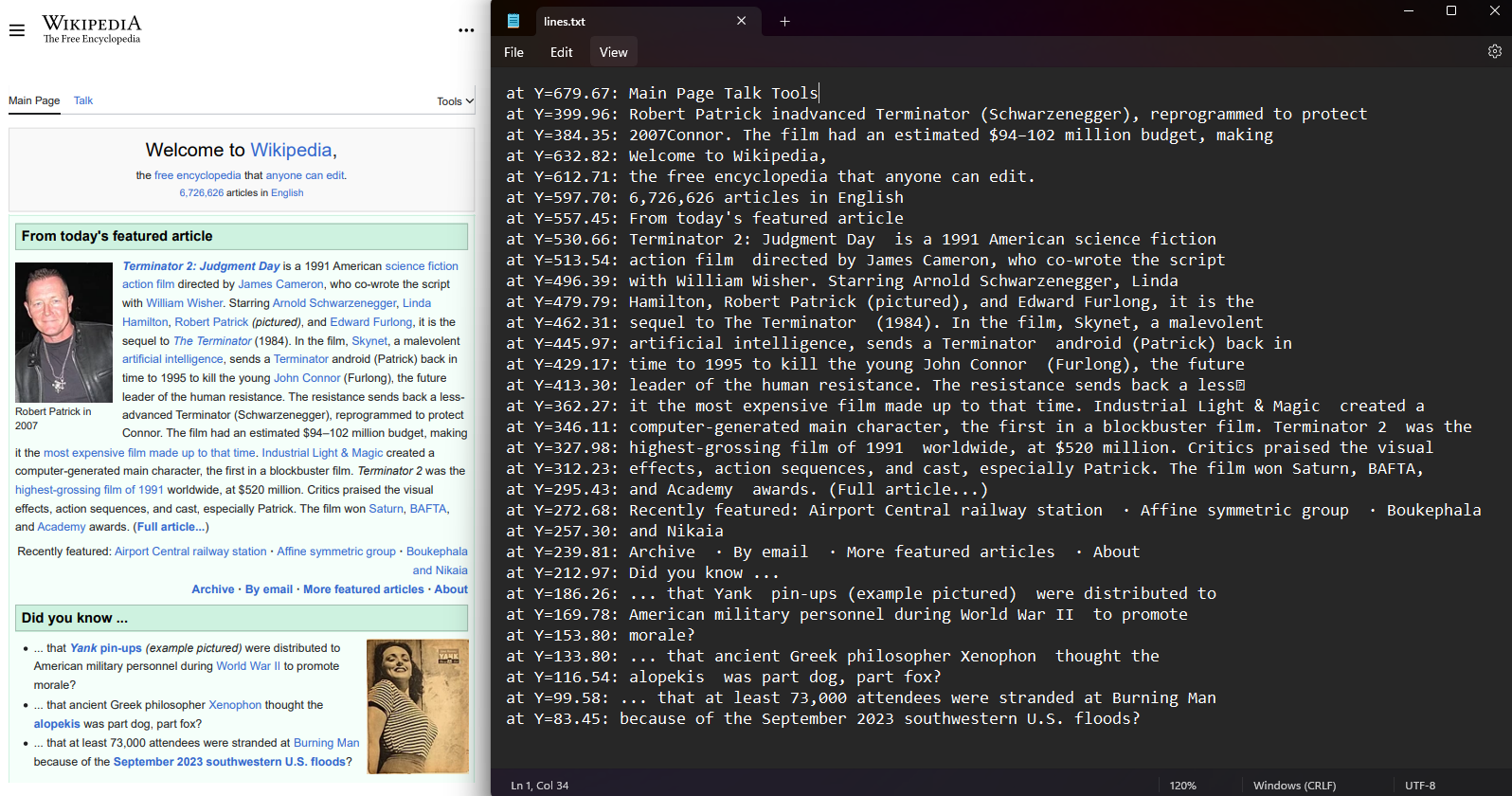
画像抽出の例
ExtractAllImages メソッドを使用して、ドキュメントに埋め込まれたすべての画像を抽出します。 そのメソッドは、AnyBitmapオブジェクトのリストとして画像を返します。 前の例から使用した同じドキュメントを使用して、画像を抽出し、それらを「images」フォルダーにエクスポートしました。
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-image.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract images
var images = pdf.ExtractAllImages();
for(int i = 0; i < images.Count; i++)
{
// Export the extracted images
images[i].SaveAs($"images/image{i}.png");
}Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract images
Private images = pdf.ExtractAllImages()
For i As Integer = 0 To images.Count - 1
' Export the extracted images
images(i).SaveAs($"images/image{i}.png")
Next i
上記で示したExtractAllImagesメソッドに加えて、ユーザーはExtractAllBitmapsとExtractAllRawImagesメソッドを使用して、ドキュメントから画像情報を抽出することができます。 ExtractAllBitmaps メソッドは、コード例のように AnyBitmap のリストを返しますが、ExtractAllRawImages メソッドは PDF ドキュメントからすべての画像を抽出し、それらをバイト配列(byte [])の形式で生のデータとして返します。
特定のページからテキストと画像を抽出
テキストと画像の抽出は、単一または複数の指定されたページで実行できます。 単一ページまたは複数ページからテキストを抽出するには、ExtractTextFromPage および ExtractTextFromPages メソッドを使用します。 画像を抽出するには、ExtractImagesFromPage および ExtractImagesFromPages メソッドを使用します。
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-single-multiple.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text from page 1
string textFromPage1 = pdf.ExtractTextFromPage(0);
int[] pages = new[] { 0, 2 };
// Extract text from pages 1 & 3
string textFromPage1_3 = pdf.ExtractTextFromPages(pages);Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text from page 1
Private textFromPage1 As String = pdf.ExtractTextFromPage(0)
Private pages() As Integer = { 0, 2 }
' Extract text from pages 1 & 3
Private textFromPage1_3 As String = pdf.ExtractTextFromPages(pages)







