

C# PDFパーサー

2023年1月25日
更新済み 2024年12月11日
This article was translated from English: Does it need improvement?
Translated
View the article in English
適切なツールを使用することで、C#でPDFを取り扱い、.NETアプリケーションに必要なすべての機能を活用することが簡単になります。C#のPDFファイル解析機能を使用することも含まれます。 このチュートリアルでは、IronPDF(C#ライブラリ)を使用して、それをいくつかの簡単なステップで実行します。



IronPDFを始めましょう
今日から無料トライアルでIronPDFをあなたのプロジェクトで使い始めましょう。
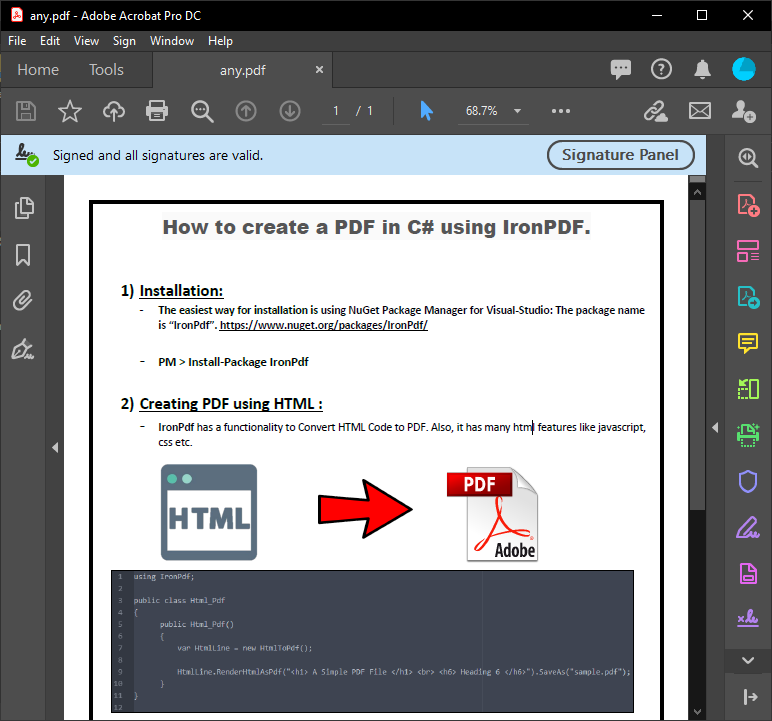
C#でPDFファイルを解析する方法
- C# PDF パーサーライブラリをダウンロード
- Visual Studioにインストールする
ExtractAllTextメソッドを使用して、すべての行のテキストを抽出します- 単一ページからすべてのテキストを
ExtractTextFromPageメソッドで抽出します - 解析されたPDFコンテンツを表示
C#PDFファイルを解析
PDFファイルのパースは比較的簡単です。 以下のコードでは、ExtractAllText メソッドを使用して、PDF ドキュメント全体からすべての行のテキストを抽出します。 後で、抽出されたPDFコンテンツを横に並べて、出力として確認できます。
:path=/static-assets/pdf/content-code-examples/how-to/csharp-parse-pdf-parse-pdf.csusing IronPdf;
// Select the desired PDF File
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract all text from an pdf
string allText = pdf.ExtractAllText();
// Extract all text from page 1
string page1Text = pdf.ExtractTextFromPage(0);Imports IronPdf
' Select the desired PDF File
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract all text from an pdf
Private allText As String = pdf.ExtractAllText()
' Extract all text from page 1
Private page1Text As String = pdf.ExtractTextFromPage(0)
$vbLabelText
$csharpLabel
解析されたPDFコンテンツを表示
上記のコード実行から解析されたPDFコンテンツを表示するために、C#フォームを使用しました。 この出力はPDFからの正確なテキストを提供するため、個人用または顧客のドキュメントのニーズに使用できます。
~ PDF ~
ライブラリ クイック アクセス

ChaknithはIronXLとIronBarcodeで作業しています。彼はC#と.NETに深い専門知識を持ち、ソフトウェアの改善と顧客サポートを支援しています。ユーザーとの対話から得た彼の洞察は、より良い製品、文書、および全体的な体験に貢献しています。








