
ライブ環境でテストする
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
C# PDF ライブラリ
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


PDF内のテキストを見つけることは、特に簡単に編集できない静的ファイルを扱う場合、困難な作業になり得ます。検索可能な. ドキュメントのワークフローを自動化する場合、検索機能を構築する場合、検索条件に一致するテキストを強調表示する必要がある場合、またはデータを抽出する場合でも、テキスト抽出は開発者にとって重要な機能です。
IronPDF強力な.NETライブラリである がこのプロセスを簡素化し、開発者が効率的に検索できるようにします。テキストを抽出PDFから。 この記事では、コード例や実用的なアプリケーションとともに、C#を使用してPDF内のテキストを見つける方法をIronPDFで探ります。
「テキスト検索」とは、文書、ファイル、またはその他のデータ構造内で特定のテキストやパターンを検索する過程を指します。 PDFファイルの文脈では、特定の単語、フレーズ、またはパターンをPDFドキュメントのテキストコンテンツ内で識別し、位置を特定することを含みます。 この機能は、特にPDF形式で保存された非構造化または半構造化データを扱う際に、多くの業界のさまざまなアプリケーションにとって不可欠です。
PDFファイルは、内容を一貫したデバイス非依存の形式で表示するように設計されています。 ただし、PDF内のテキストの保存方法は大きく異なる場合があります。 テキストは次のように保存される場合があります。
複雑なレイアウト: 断片として保存されたテキストや異常なエンコーディングによるもので、正確に抽出および検索することが困難です。
この変動性により、PDF内での効果的なテキスト検索には、異なるコンテンツタイプをシームレスに処理できるIronPDFのような専門的なライブラリがしばしば必要になります。
PDFでテキストを検索する機能は、次のような幅広い用途において役立ちます。
ワークフローの自動化: PDFドキュメント内の重要な用語や値を特定することで、請求書、契約書、またはレポートの処理などのタスクを自動化します。
データ抽出: 他のシステムでの使用や分析のために情報を抽出すること。
コンテンツの検証: コンプライアンス声明や法的条項など、必要な用語やフレーズが文書に含まれていることを保証すること。
PDFでテキストを見つけることは、次の課題のため、必ずしも簡単ではありません:
IronPDFは、.NETエコシステムで作業する開発者のために、PDF操作を可能な限りシームレスにするよう設計されています。 テキスト抽出と操作プロセスを効率化するためにカスタマイズされた一連の機能を提供します。
使いやすさ:
IronPDFには特徴があります直感的なAPI、開発者が急な学習曲線なく迅速に開始できるようにします。 基本的なテキスト抽出を行う場合でもHTMLからPDFへの変換、または高度な操作であっても、そのメソッドは使いやすいです。
高精度:
一部のPDFライブラリが複雑なレイアウトや埋め込みフォントを含むPDFの取り扱いに苦労するのに対し、IronPDFは正確にテキストを抽出します。
*クロスプラットフォームサポート:***。
IronPDFは.NET Frameworkと.NET Coreの両方に対応しており、開発者はそれをモダンなウェブアプリ、デスクトップアプリケーション、さらには従来のシステムでも使用することができます。
高度なクエリのサポート:
ライブラリは、正規表現やターゲット抽出のような高度な検索技術をサポートしており、データマイニングやドキュメントのインデックス作成のような複雑な使用ケースに適しています。
IronPDFはNuGetを通じて利用可能で、.NETプロジェクトに簡単に追加できます。 はじめ方をご紹介します。
にIronPDF をインストールするVisual StudioでNuGetパッケージマネージャーを使用するか、パッケージマネージャーコンソールで次のコマンドを実行してください。
Install-Package IronPdfInstall-Package IronPdf'INSTANT VB TODO TASK: The following line uses invalid syntax:
'Install-Package IronPdfこれはライブラリとその依存関係をダウンロードしてインストールします。
ライブラリをインストールしたら、IronPDF名前空間を参照してプロジェクトに含める必要があります。 コードファイルの先頭に次の行を追加します。
using IronPdf;using IronPdf;Imports IronPdfIronPDFは、PDFドキュメント内のテキスト検索プロセスを簡素化します。 以下は、これを達成するためのステップバイステップのデモンストレーションです。
最初のステップは、作業したいPDFファイルを読み込むことです。 これは、次のコードに示されているように、PdfDocumentクラスを使用して行われます。
using IronPdf;
PdfDocument pdf = PdfDocument.FromFile("example.pdf");using IronPdf;
PdfDocument pdf = PdfDocument.FromFile("example.pdf");Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("example.pdf")PdfDocumentクラスはメモリ内のPDFファイルを表し、テキストの抽出や内容の修正といったさまざまな操作を行うことができます。 PDFが読み込まれたら、PDFドキュメント全体、またはファイル内の特定のPDFページからテキストを検索することができます。
PDFを読み込んだ後、ExtractAllTextを使用します。()ドキュメント全体のテキストコンテンツを抽出するメソッド。 その後、標準的な文字列操作技術を使用して特定の用語を検索できます。
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string path = "example.pdf";
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile(path);
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for a specific term
string searchTerm = "Invoice";
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
Console.WriteLine(isFound
? $"The term '{searchTerm}' was found in the PDF!"
: $"The term '{searchTerm}' was not found.");
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string path = "example.pdf";
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile(path);
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for a specific term
string searchTerm = "Invoice";
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
Console.WriteLine(isFound
? $"The term '{searchTerm}' was found in the PDF!"
: $"The term '{searchTerm}' was not found.");
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim path As String = "example.pdf"
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile(path)
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Search for a specific term
Dim searchTerm As String = "Invoice"
Dim isFound As Boolean = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase)
Console.WriteLine(If(isFound, $"The term '{searchTerm}' was found in the PDF!", $"The term '{searchTerm}' was not found."))
End Sub
End ClassインプットPDF
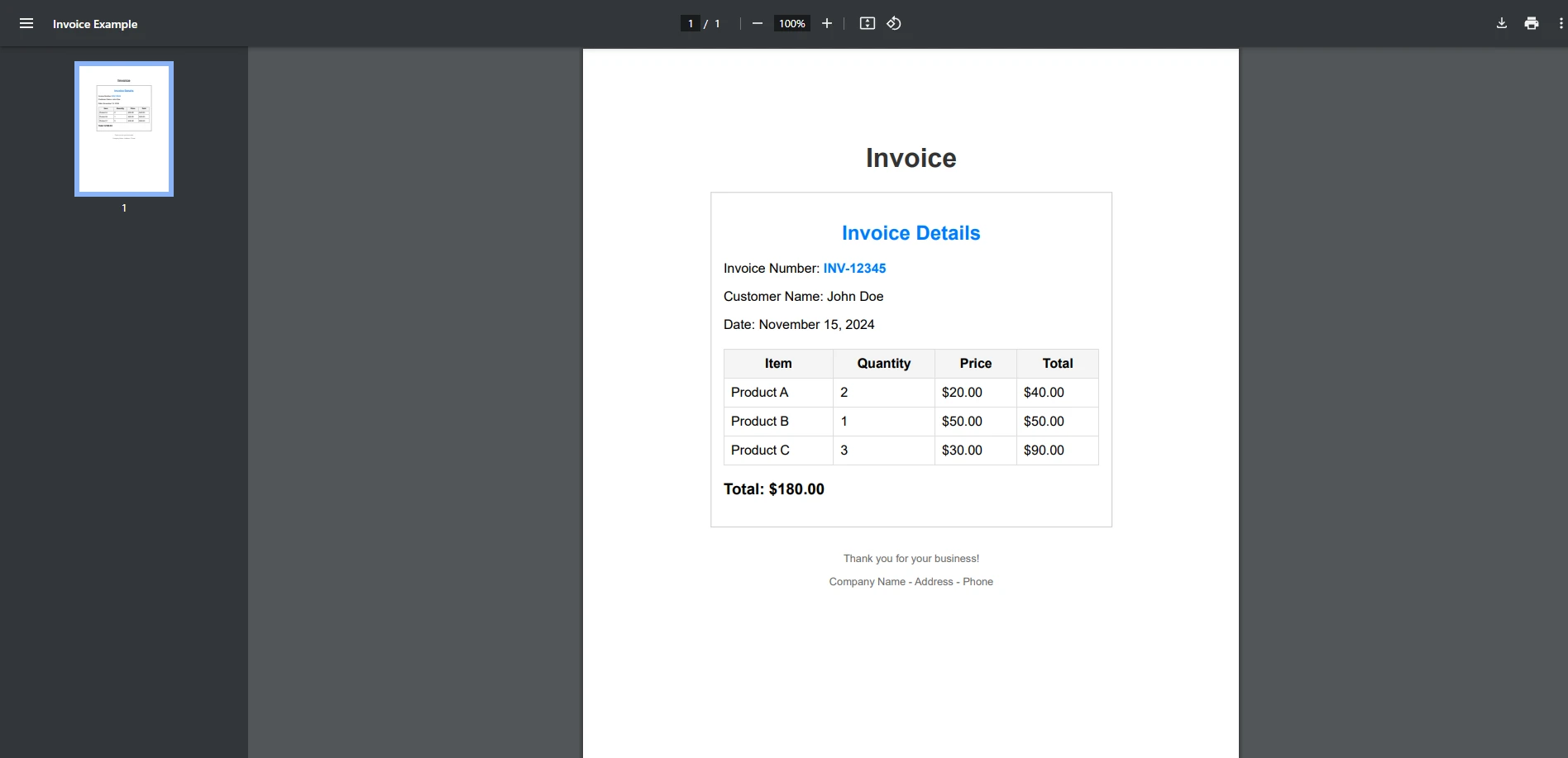
コンソール出力
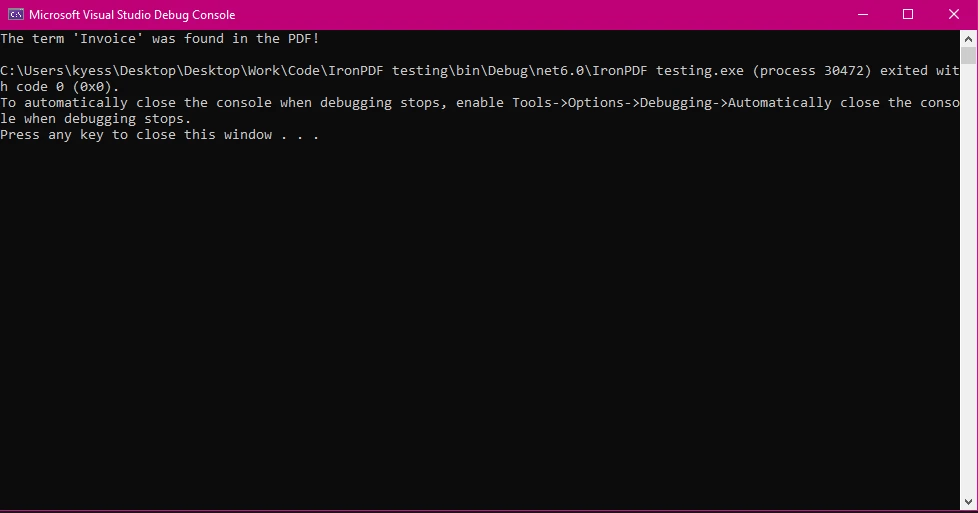
この例では、PDFに用語が存在するかどうかを確認する簡単なケースを示しています。 StringComparison.OrdinalIgnoreCaseは、検索対象のテキストが大文字と小文字を区別しないことを保証します。
IronPDFは、テキスト検索機能を拡張するいくつかの高度な機能を提供します。
正規表現は、テキスト内のパターンを見つけるための強力なツールです。 たとえば、PDF内のすべてのメールアドレスを見つけたい場合があります。
using System.Text.RegularExpressions;
// Extract all text
string pdfText = pdf.ExtractAllText();
// Use a regex to find patterns (e.g., email addresses)
Regex regex = new Regex(@"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}");
MatchCollection matches = regex.Matches(pdfText);
foreach (Match match in matches)
{
Console.WriteLine($"Found match: {match.Value}");
}using System.Text.RegularExpressions;
// Extract all text
string pdfText = pdf.ExtractAllText();
// Use a regex to find patterns (e.g., email addresses)
Regex regex = new Regex(@"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}");
MatchCollection matches = regex.Matches(pdfText);
foreach (Match match in matches)
{
Console.WriteLine($"Found match: {match.Value}");
}Imports System.Text.RegularExpressions
' Extract all text
Private pdfText As String = pdf.ExtractAllText()
' Use a regex to find patterns (e.g., email addresses)
Private regex As New Regex("[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}")
Private matches As MatchCollection = regex.Matches(pdfText)
For Each match As Match In matches
Console.WriteLine($"Found match: {match.Value}")
Next matchインプットPDF
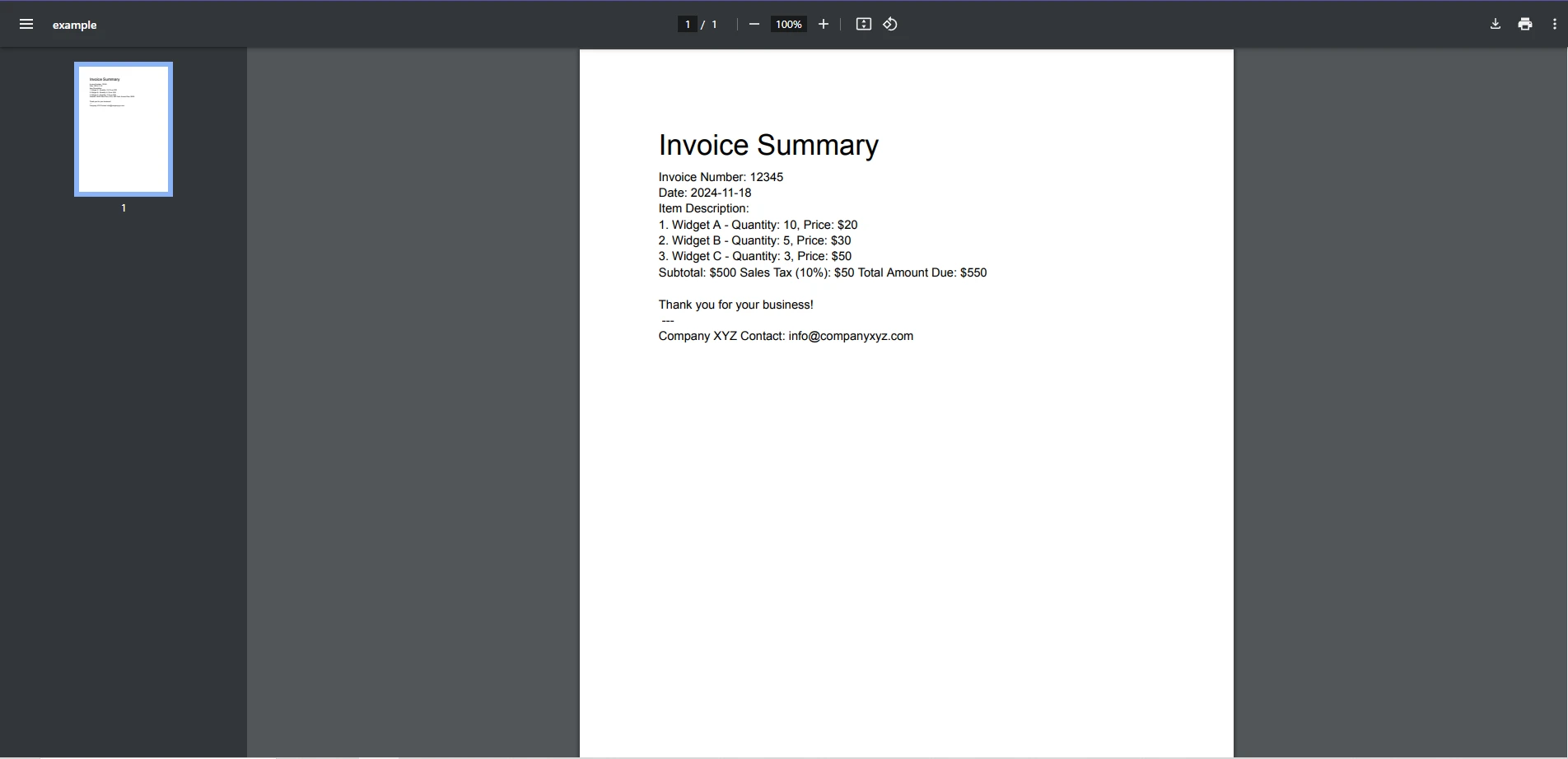
コンソール出力
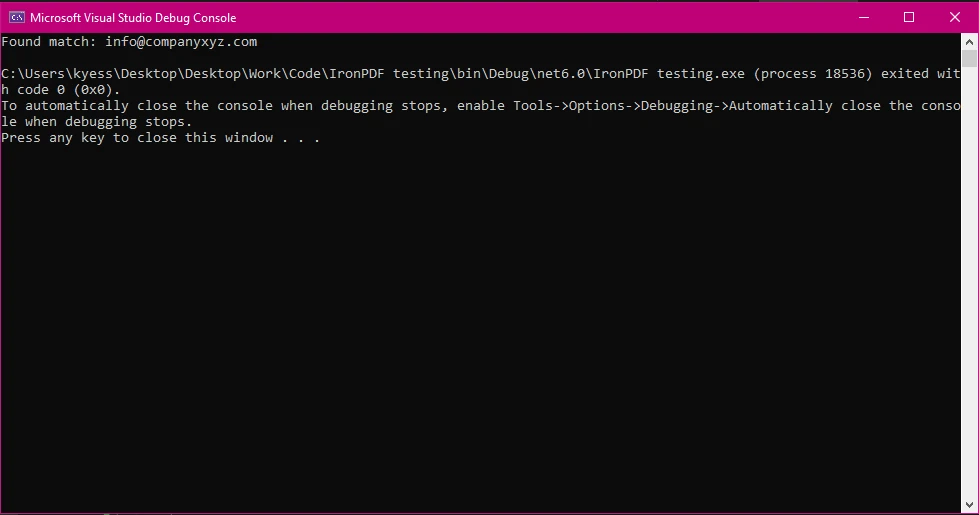
この例では、正規表現パターンを使用して文書内に見つかったすべてのメールアドレスを識別して印刷します。
場合によっては、PDFの特定のページ内だけを検索する必要があるかもしれません。 IronPDFを使用すると、PdfDocument.Pagesプロパティを使用して個々のページをターゲットにすることができます。
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("urlPdf.pdf");
var pageText = pdf.Pages[0].Text.ToString(); // Extract text from the first page
if (pageText.Contains("IronPDF"))
{
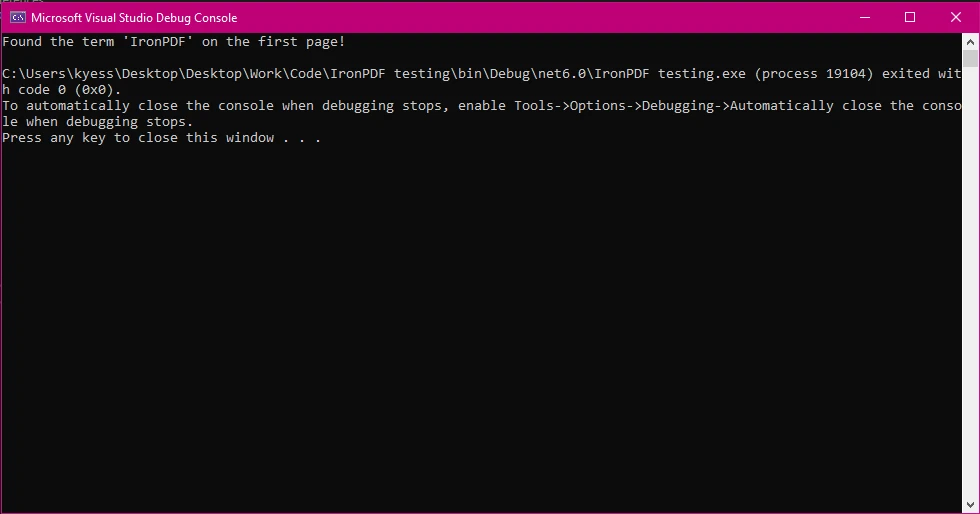
Console.WriteLine("Found the term 'IronPDF' on the first page!");
}
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("urlPdf.pdf");
var pageText = pdf.Pages[0].Text.ToString(); // Extract text from the first page
if (pageText.Contains("IronPDF"))
{
Console.WriteLine("Found the term 'IronPDF' on the first page!");
}
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile("urlPdf.pdf")
Dim pageText = pdf.Pages(0).Text.ToString() ' Extract text from the first page
If pageText.Contains("IronPDF") Then
Console.WriteLine("Found the term 'IronPDF' on the first page!")
End If
End Sub
End ClassインプットPDF
コンソール出力
このアプローチは、大きなPDFを扱う際のパフォーマンスを最適化するのに役立ちます。
法律専門家は、長文の契約内の主要な用語や条項の検索を自動化するためにIronPDFを使用できます。 例えば、ドキュメント内で「終了条項」や「機密保持」を素早く見つけることができます。
金融または会計業務のワークフローにおいて、IronPDFは請求書番号、日付、または合計金額を大量のPDFファイルの中から見つけ出すのに役立ち、業務を合理化し、手作業を減らします。
IronPDFは、データパイプラインに統合して、PDF形式で保存されたレポートやログから情報を抽出および分析することができます。 これは、大量の非構造化データを扱う業界にとって特に有用です。
IronPDFは、PDFを操作するためのライブラリ以上のものです。 これは、.NET開発者が複雑なPDF操作を簡単に扱うことを可能にする完全なツールキットです。 テキスト抽出や特定の用語の検索から、正規表現による高度なパターンマッチングの実行まで、IronPDFは、手作業や複数のライブラリが必要となる可能性があるタスクを効率化します。
PDFでのテキスト抽出と検索の機能は、業界全体で強力なユースケースを引き出します。 法律専門家は契約書の重要な条項の検索を自動化でき、会計士は請求書処理を効率化し、どの分野の開発者も効果的なドキュメントワークフローを作成できます。 IronPDFは、正確なテキスト抽出、.NET CoreおよびFrameworkとの互換性、そして高度な機能を提供することで、PDFに関するニーズを手間なく満たします。
PDF処理が開発のスピードを落とすことがないようにしましょう。 今日からIronPDFを使用して、テキスト抽出を簡素化し、生産性を向上させましょう。 以下の手順で始めることができます:
Install-Package IronPdf
クレジットカードは不要です
試用キーはメールに送信されるはずです。![]() 試用版申し込みフォームが
試用版申し込みフォームが
正常に送信されました。
もし届かない場合は、
support@ironsoftware.comにお問い合わせください。
無料で始めましょう
クレジットカードは不要です
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
30日間、完全に機能する製品をご利用いただけます。
数分で稼働させることができます。
製品トライアル期間中にサポートエンジニアリングチームへの完全アクセス





![]() クレジットカードやアカウント作成は不要です。
クレジットカードやアカウント作成は不要です。
試用キーはメールにあるはずです。
もしない場合は、
support@ironsoftware.comまでご連絡ください。
30分の個別デモを予約する。
契約なし、カード情報不要、義務なし。


10 .NET API製品オフィスドキュメントのために