
ライブ環境でテストする
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
C# PDF ライブラリ
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


PDF(ポータブルドキュメントフォーマット)ファイルは無数の業界で重要な役割を果たし、企業が文書を安全に共有、保存、および管理することを可能にしています。 開発者にとって、PDFを扱うことは、クライアントのニーズをサポートするために、PDFの作成、読み込み、変換、およびコンテンツの抽出を含むことがよくあります。 PDFからのテキスト抽出は、データ分析、ドキュメントインデックス化、コンテンツ移行、またはアクセシビリティ機能の有効化などのタスクに不可欠です。 現代のライブラリのようなIronPDFこれらのタスクをこれまでになく簡単にし、最小限の労力でPDFファイルを操作するための強力なツールを提供します。
このガイドは、最も一般的な要件の1つであるC#でPDFからテキストを抽出することに焦点を当てています。 Visual Studioでプロジェクトを設定し、IronPDFをインストールして、簡潔なコード例を使用してテキスト抽出を行う手順を説明します。 途中で、IronPDFの強力な機能を強調し、その機能には.NETを使用してPDFファイルを作成、操作、変換する能力が含まれます。 ドキュメントを多用するアプリケーションを構築している場合でも、単に効率的なPDF処理が必要な場合でも、このチュートリアルがあなたをサポートします。
IronPDFは、ブラウザができるほとんどすべての操作を実行できる強力なPDF変換プログラムです。 開発者向けの.NETライブラリを使用すると、PDFドキュメントの作成、読み取り、および操作が簡単になります。 IronPDFは、Chromeエンジンを使用してHTMLからPDFのドキュメントに変換します。IronPDFは、HTML、ASPX、Razor HTML、MVC ViewなどのWebコンポーネントをサポートしています。 Microsoft .NET アプリケーションは IronPDF に対応しています。(ASP.NET Webアプリケーションと従来のWindowsアプリケーションの両方). IronPDFは、視覚的に魅力的なPDFドキュメントを作成するためにも使用できます。
IronPDFを使用して、HTML5、JavaScript、CSS、画像からPDF文書を作成することができます。 さらに、ファイルにはヘッダとフッタを含めることができます。 IronPDFのおかげで、PDFドキュメントを簡単に読むことができます。 IronPDFには、包括的なPDF変換エンジンと強力なHTMLからPDFへの変換機能があり、PDFドキュメントを処理できます。
Visual Studioソフトウェアを開き、[ファイル]メニューに移動します。 「新しいプロジェクト」を選択し、その後「コンソールアプリケーション」を選択します。 この記事では、コンソールアプリケーションを使用してPDFドキュメントを生成します。
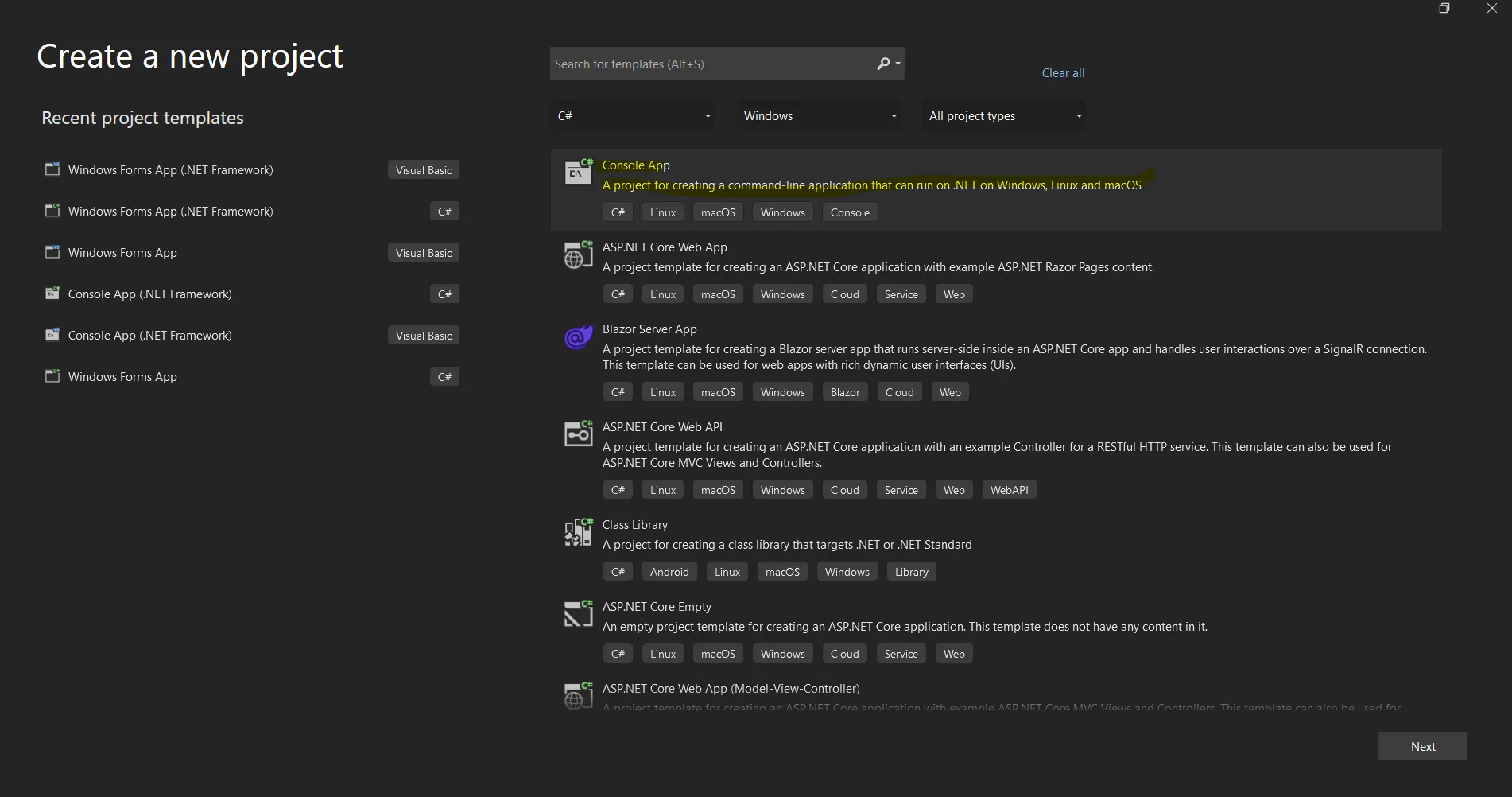
Visual Studio で新しいプロジェクトを作成する
プロジェクト名を入力し、適切なテキストボックスにファイルパスを選択してください。 次に、Create ボタンをクリックし、以下のスクリーンショットのように必要な .NET Framework を選択します。

Visual Studio で新しいプロジェクトを構成する
Visual Studioプロジェクトは、選択したアプリケーションの構造を生成し、もしコンソール、ウィンドウズ、およびWebアプリケーションを選択した場合、コードを入力してアプリケーションをビルド/実行できるprogram.csファイルを開きます。
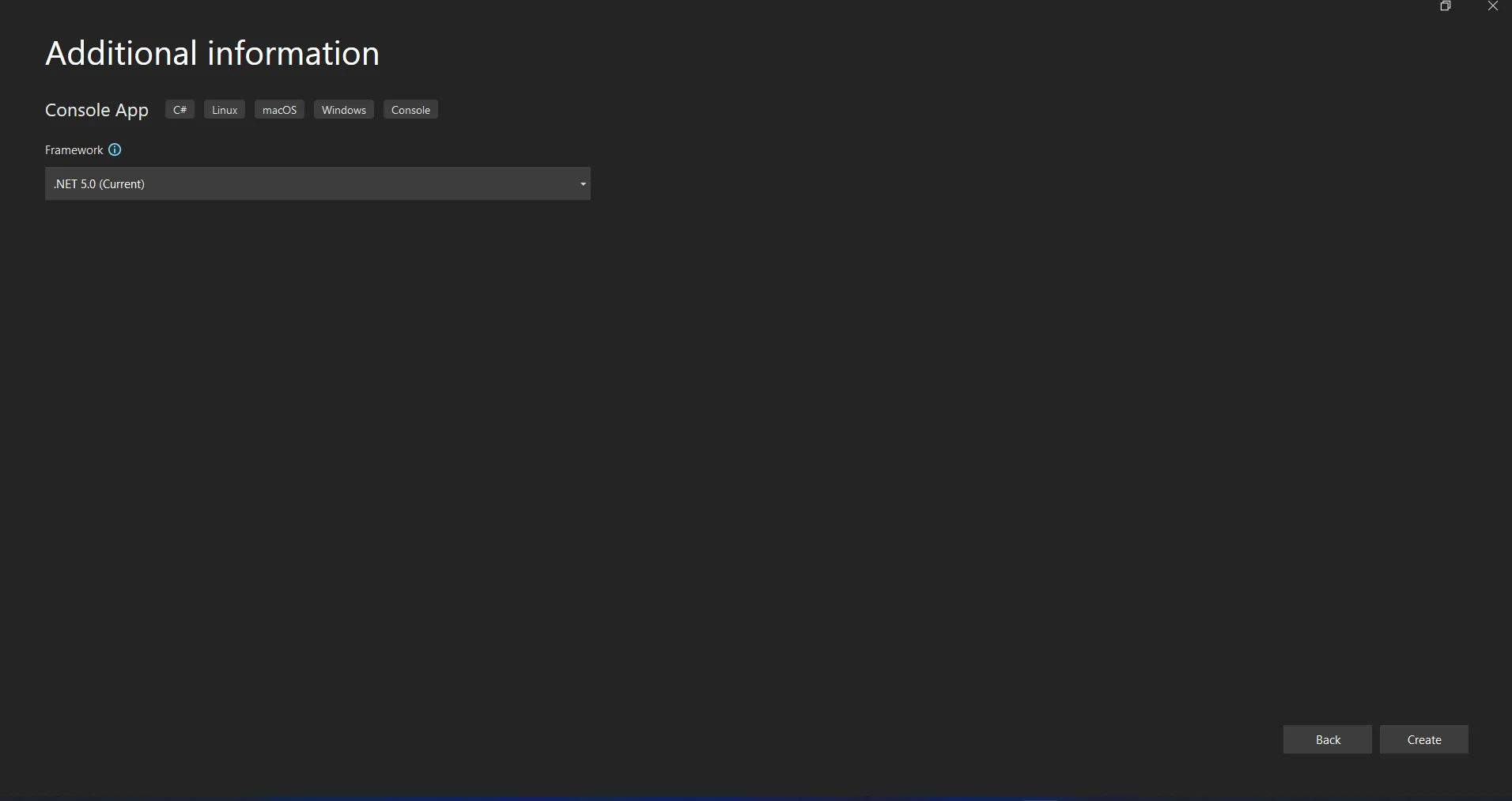
.NET Core の選択
次に、コードをテストするためにライブラリを追加します。
IronPDFライブラリは、4つの方法でダウンロードおよびインストールできます。
これらは:
Visual Studioソフトウェアは、ソリューションにパッケージを直接インストールするためのNuGetパッケージマネージャーオプションを提供します。 以下のスクリーンショットは、NuGetパッケージマネージャーの開き方を示しています。
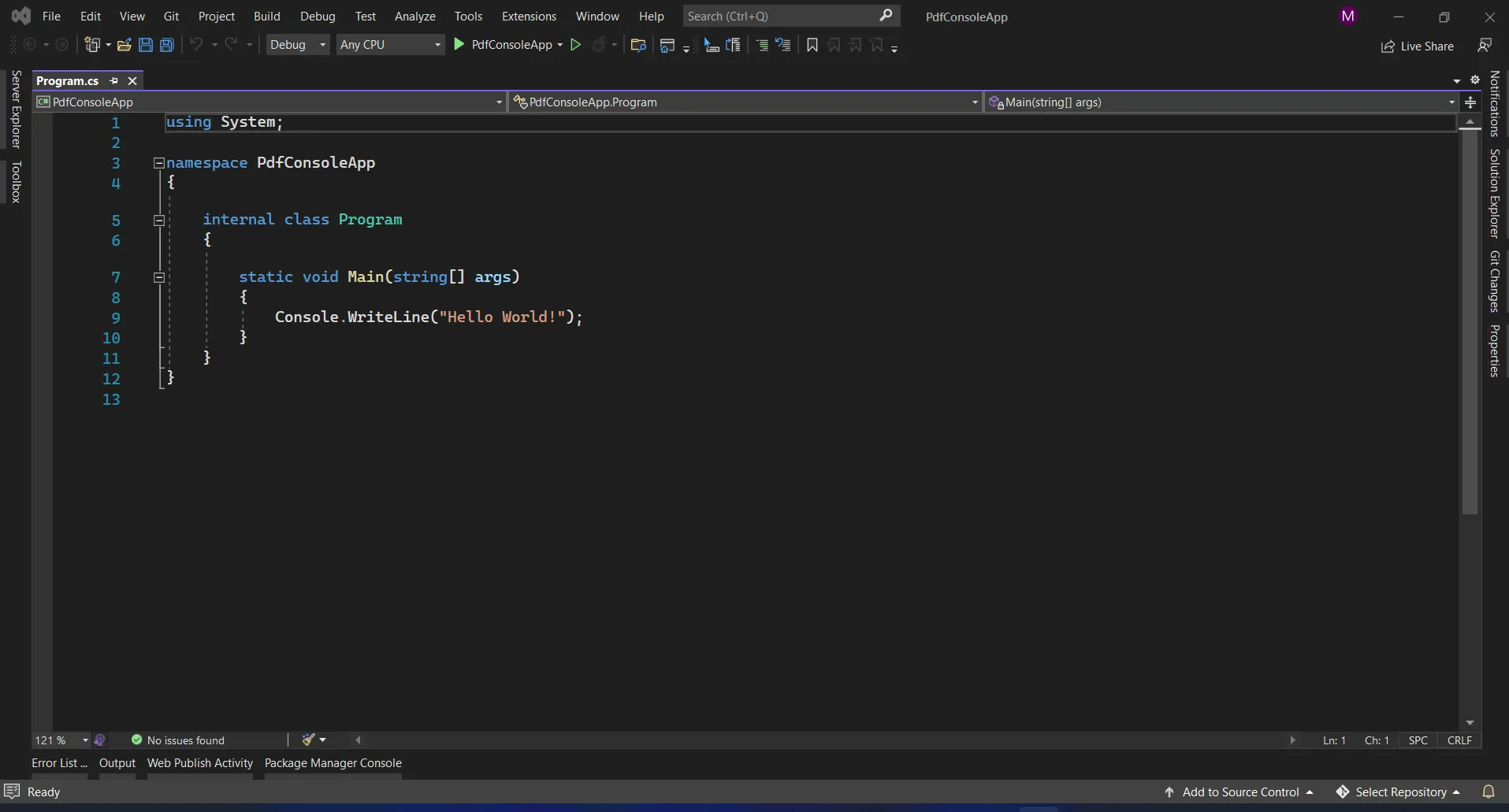
Visual Studio program.cs ファイル
NuGetサイトからパッケージのリストを表示するための検索ボックスを提供します。パッケージマネージャーでは、以下のスクリーンショットのようにキーワード「IronPDF」を検索する必要があります。

NuGet パッケージ マネージャー
上記の画像には、関連する検索項目のリストが表示されています。 ソリューションにパッケージをインストールするために必要なオプションを選択する必要があります。
Visual Studioで、ツール > NuGetパッケージマネージャー > パッケージマネージャーコンソールに移動
パッケージマネージャー コンソール タブに次の行を入力してください:
Install-Package IronPdf
現在、パッケージは現在のプロジェクトにダウンロード/インストールされ、使用できるようになります。
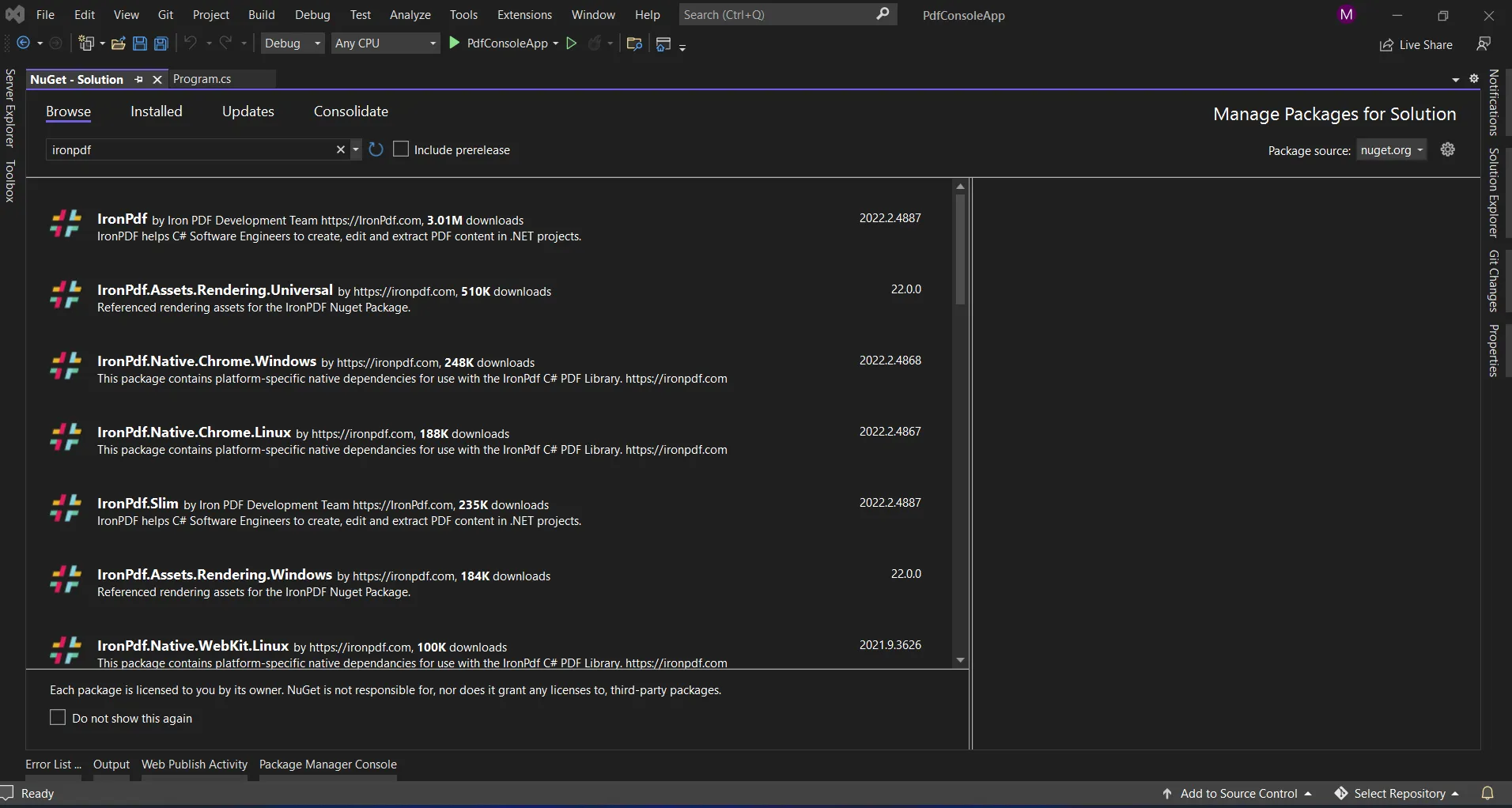
NuGet パッケージ マネージャーの IronPdf ライブラリ
こちらの第三の方法は、IronPDF NuGetパッケージ直接彼らのウェブサイトから。
訪問するIronPDF 公式サイトをクリックし、ウェブサイトから最新のパッケージを直接ダウンロードしてください。ダウンロードが完了したら、以下の手順に従ってパッケージをプロジェクトに追加してください。
IronPDFプログラムを使用すると、PDFファイルからのテキスト抽出を実行し、PDFページをPDFオブジェクトに変換できます。 以下は、IronPDFを使用して既存のPDFを読み取る方法の例です。
最初のアプローチはPDFからテキストを抽出することであり、サンプルコードのスニペットは以下の通りです。
using IronPdf;
var pdfDocument = PdfDocument.FromFile("result.pdf");
string AllText = pdfDocument.ExtractAllText();using IronPdf;
var pdfDocument = PdfDocument.FromFile("result.pdf");
string AllText = pdfDocument.ExtractAllText();Imports IronPdf
Private pdfDocument = PdfDocument.FromFile("result.pdf")
Private AllText As String = pdfDocument.ExtractAllText()についてFromFile(ファイルから)既存のファイルからPDFドキュメントを読み込み、それを変換するために使用される静的メソッドPDFDocument上記のコードに示されているように、オブジェクト。 このオブジェクトを使用して、PDFページ上のテキストと画像を読み取ることができます。 そのオブジェクトには、というメソッドがありますExtractAllTextPDFドキュメント全体からすべてのテキストを抽出し、その抽出されたテキストを文字列に保持します。この文字列を使用して処理を行うことができます。
以下は、PDFファイルからページごとにテキストを抽出するために使用できる2つ目のメソッドのコード例です。
using PdfDocument pdf = PdfDocument.FromFile("result.pdf");
for (var index = 0; index < pdf.PageCount; index++)
{
string Text = pdf.ExtractTextFromPage(index);
}using PdfDocument pdf = PdfDocument.FromFile("result.pdf");
for (var index = 0; index < pdf.PageCount; index++)
{
string Text = pdf.ExtractTextFromPage(index);
}Using pdf As PdfDocument = PdfDocument.FromFile("result.pdf")
For index = 0 To pdf.PageCount - 1
Dim Text As String = pdf.ExtractTextFromPage(index)
Next index
End Using上記のコードでは、最初にPDF文書全体を読み込み、それをPDFオブジェクトに変換することがわかります。 次に、組み込みメソッドを使用してPDFドキュメント全体のページ数を取得します。そのメソッドの名称はPageCount(ページ数)これは、読み込んだPDFドキュメントの利用可能なページ数の合計を取得します。 「forループ」を使用してExtractTextFromPage関数は、ページ番号をパラメータとして渡して読み込まれたドキュメントからテキストを抽出することを可能にします。 その後、正確なテキストを文字列変数に保持します。 同様に、"for"または"for each"ループを使用して、PDFページごとにテキストを抽出します。
IronPDFは、.NETアプリケーションでPDFをシームレスに利用できるよう設計された多用途で強力なPDFライブラリです。 その強力な機能により、開発者はAdobe Readerのようなサードパーティ依存に頼ることなく、PDFの作成、操作、コンテンツの抽出が可能になります。 IronPDFの際立った機能の一つは、PDFドキュメントからテキストを抽出する能力です。 この機能は、データ分析、文書のインデックス作成、コンテンツの移行、アクセシビリティ機能の有効化などのタスクを自動化するために非常に重要です。 IronPDFは、開発者がプログラムを使ってテキストを取得し処理することを可能にすることで、ワークフローを簡素化し、PDFコンテンツの扱いに新たな可能性を開きます。
シンプルな統合とクロスプラットフォームのサポートにより、IronPDFはPDFドキュメントを効率的に処理しようとする開発者にとって優れた選択肢です。 また、IronPDFは無料試用その機能を全面的にリスクなしで探求し、納得した上で購入することができます。 価格の詳細とライセンスオプションについて詳しくは、弊社のサイトをご覧ください価格ページ.
Kye Stuart は Iron Software でプログラミングへの情熱とライティング能力を融合させています。Yoobee College でソフトウェア導入を学び、複雑な技術コンセプトを明確な教育コンテンツに変換しています。Kye は生涯学習を重視し、新しい技術的挑戦を積極的に受け入れています。
仕事の外では、PC ゲーム、Twitch でのストリーミング、庭仕事や犬の Jaiya との散歩などのアウトドア活動を楽しんでいます。Kye の率直なアプローチにより、彼らはグローバルな開発者のためにテクノロジーをわかりやすくすることを使命とする Iron Software にとって重要な存在です。
30日間の試用キーをすぐに取得。
15日間の試用キー 即時発行。
 クレジットカードやアカウント作成は不要です。
クレジットカードやアカウント作成は不要です。Install-Package IronPdf
クレジットカードは不要です
試用キーはメールに送信されるはずです。![]() 試用版申し込みフォームが
試用版申し込みフォームが
正常に送信されました。
もし届かない場合は、
support@ironsoftware.comにお問い合わせください。
無料で始めましょう
クレジットカードは不要です
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
30日間、完全に機能する製品をご利用いただけます。
数分で稼働させることができます。
製品トライアル期間中にサポートエンジニアリングチームへの完全アクセス





![]() クレジットカードやアカウント作成は不要です。
クレジットカードやアカウント作成は不要です。
試用キーはメールにあるはずです。
もしない場合は、
support@ironsoftware.comまでご連絡ください。
30分の個別デモを予約する。
契約なし、カード情報不要、義務なし。


10 .NET API製品オフィスドキュメントのために