
ライブ環境でテストする
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
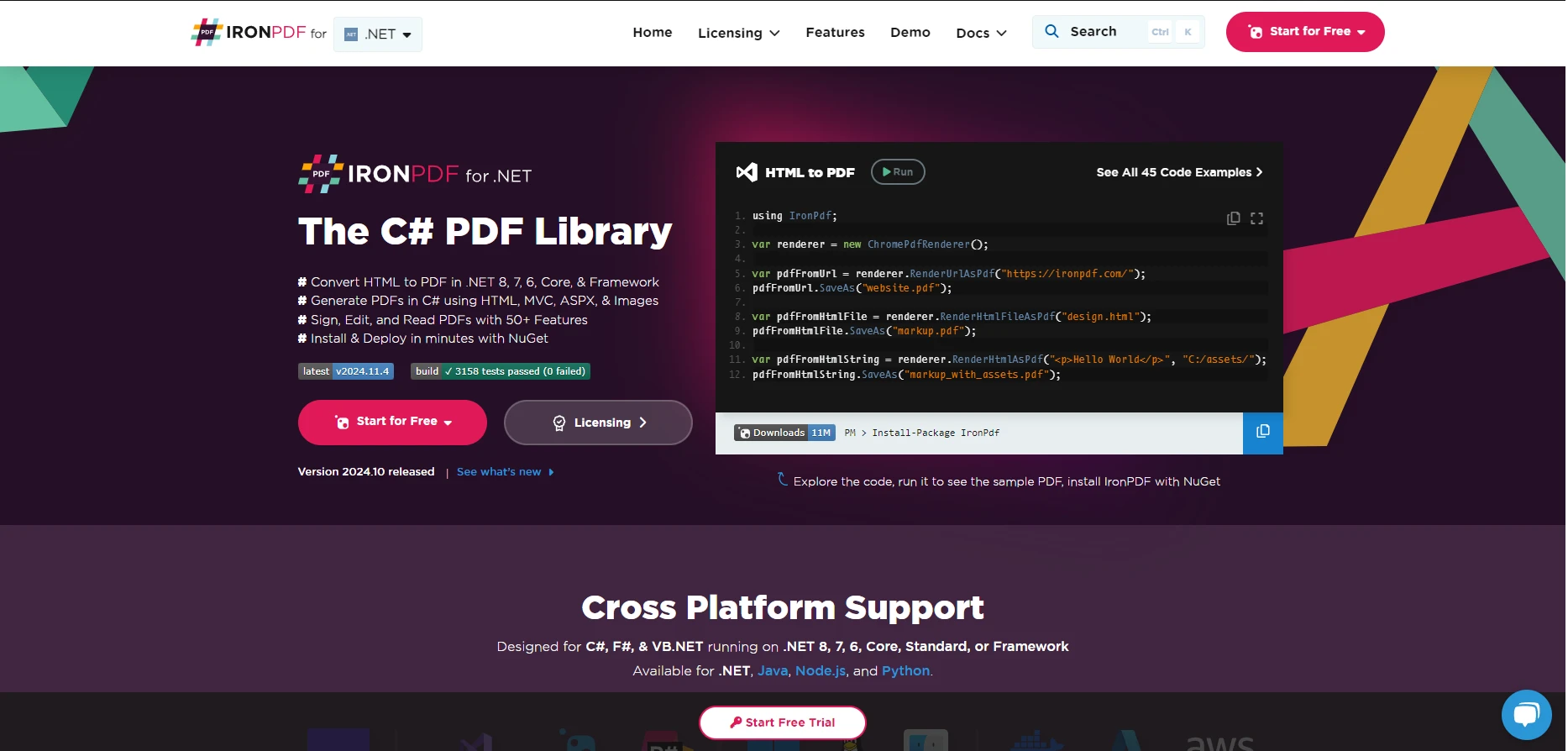
C# PDF ライブラリ
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


C#でデータを扱う際、開発者はしばしば数値の文字列表現を整数に変換する必要があります。 このタスクは「整数の解析」として知られ、ユーザー入力の処理からPDFのようなファイルからのデータ抽出まで、さまざまなアプリケーションにとって重要です。 C#は強力なメソッドを提供しながら、整数の解析PDFのような非構造化または半構造化データを扱う場合、プロセスはより複雑になることがあります。
ここはIronPDF.NET開発者向けの強力なPDFライブラリが登場します。 IronPDFを使用すると、PDFからテキストを抽出し、C#の解析機能を活用してこのテキストを利用可能な数値データに変換できます。 請求書、レポート、またはフォームを分析する際に、C#の解析ツールをIronPDFと組み合わせることでPDFデータの処理が簡単になり、文字列形式の数字を整数に変換することができます。
この記事では、C#でParseIntを使用して数値の文字列表現を整数に変換する方法と、IronPDFがPDFから数値データを抽出および解析するプロセスをどのように効率化できるかについて詳しく説明します。
C#で、文字列値を変換する(「123」など)整数への変換は、一般的にint.Parseを使用して行います。()または Convert.ToInt32(). これらのメソッドは、開発者がテキストデータを計算や検証に使用できる数値に変換するのを助けます。
Convert.ToInt32(文字列 s): 文字列を整数に変換し、null入力を異なる方法で処理します。
int.Parseを使用して文字列を変換する例を次に示します():
string numberString = "123";
int num = int.Parse(numberString);
Console.WriteLine(num); // Output: 123string numberString = "123";
int num = int.Parse(numberString);
Console.WriteLine(num); // Output: 123Dim numberString As String = "123"
Dim num As Integer = Integer.Parse(numberString)
Console.WriteLine(num) ' Output: 123または、Convertクラスを使用して:
string numericString = "123";
int i = Convert.ToInt32(numericString);
Console.WriteLine(result); // Outputs: 123string numericString = "123";
int i = Convert.ToInt32(numericString);
Console.WriteLine(result); // Outputs: 123Dim numericString As String = "123"
Dim i As Integer = Convert.ToInt32(numericString)
Console.WriteLine(result) ' Outputs: 123Convertクラスを使用すると、文字列やその他のデータ型を安全に変換できます。 文字列変数がnullまたは無効な値を表す可能性がある場合、特に役立ちます。()デフォルト値を返します。(この場合は0)例外をスローする代わりに。
文字列を整数に変換する際に開発者がよく直面する問題の一つは、無効または非数値の入力を処理することです。 数値の文字列表現が正しい形式ではない場合、int.Parseのようなメソッドは()例外をスローします。 ただし、Convert.ToInt32()無効な文字列に対する組み込みのフォールバックメカニズムがあります。
以下は、解析時にデフォルト値を扱う方法を示す例です:
string invalidString = "abc";
int result = Convert.ToInt32(invalidString); // Returns 0 (default value) instead of throwing an error.
Console.WriteLine(result); // Outputs: 0string invalidString = "abc";
int result = Convert.ToInt32(invalidString); // Returns 0 (default value) instead of throwing an error.
Console.WriteLine(result); // Outputs: 0Dim invalidString As String = "abc"
Dim result As Integer = Convert.ToInt32(invalidString) ' Returns 0 (default value) instead of throwing an error.
Console.WriteLine(result) ' Outputs: 0文字列をより詳細に制御して変換したい場合は、使用できます。int.TryParse()、変換が成功したかどうかを示すブール値を返します:
string invalidInput = "abc";
if (int.TryParse(invalidInput, out int result))
{
Console.WriteLine(result);
}
else
{
Console.WriteLine("Parsing failed.");
}string invalidInput = "abc";
if (int.TryParse(invalidInput, out int result))
{
Console.WriteLine(result);
}
else
{
Console.WriteLine("Parsing failed.");
}Dim invalidInput As String = "abc"
Dim result As Integer
If Integer.TryParse(invalidInput, result) Then
Console.WriteLine(result)
Else
Console.WriteLine("Parsing failed.")
End Ifこの場合、TryParse()変換された整数を格納するためにoutパラメータを使用し、変換が失敗した場合でも例外をスローせずにメソッドが値を返せるようにします。変換に失敗した場合は、プログラムが単にクラッシュするのではなく、else文が実行されます。 そうでなければ、プログラムは入力文字列から正常に解析された数字の結果を表示します。 int.TryParseを使用することは、変換が失敗する可能性がある場合にプログラムのクラッシュを回避したいときに役立ちます。
PDFを扱う際、文字列値に数値データを含むテーブルや非構造化テキストに遭遇することがあります。 このデータを抽出して処理するためには、文字列を整数に変換することが重要です。 IronPDFはこのプロセスを簡単にし、PDFコンテンツの読み取りや文字列を数値に変換するような操作を行うための柔軟性とパワーを提供します。
以下にIronPDFの主な機能をいくつか紹介します。
使用を開始するにはIronPDF、最初にそれをインストールする必要があります。 すでにインストールされている場合は、次のセクションに進むことができます。そうでない場合は、以下の手順がIronPDFライブラリのインストール方法を説明しています。
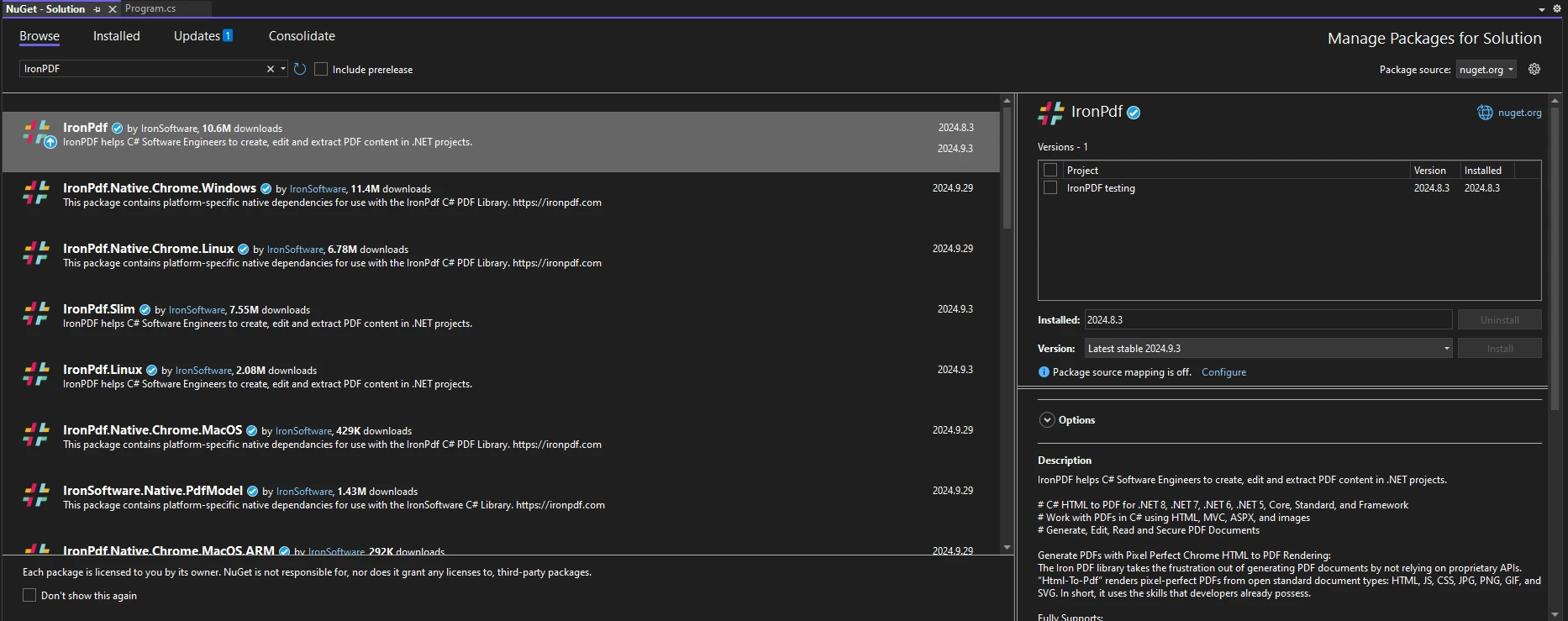
にIronPDF をインストールするNuGetパッケージマネージャーコンソールを使用して、Visual Studioを開き、パッケージマネージャーコンソールに移動します。 次に、以下のコマンドを実行します。
Install-Package IronPdfInstall-Package IronPdf'INSTANT VB TODO TASK: The following line uses invalid syntax:
'Install-Package IronPdfVisual Studioを開き、「ツール -> NuGet パッケージマネージャー -> ソリューションのNuGetパッケージを管理」に移動し、IronPDFを検索します。 ここからは、プロジェクトを選択して「インストール」をクリックするだけで、IronPDF がプロジェクトに追加されます。
IronPDFをインストールしたら、IronPDFを使用するために必要なのはコードの先頭に正しいusingステートメントを追加することだけです。
using IronPdf;using IronPdf;Imports IronPdfIronPDFは無料試用その機能を完全に利用することができます。 ウェブサイトに訪問してくださいIronPDFのウェブサイトトライアルをダウンロードして、.NETプロジェクトに高度なPDF処理を統合し始めましょう。
以下のC#コードは、IronPDFを使用してPDFからテキストを抽出し、正規表現を使用して抽出したテキスト内のすべての数値を見つけて解析する方法を示しています。 コードは、整数と小数の両方を処理し、通貨記号のような非数値文字を除去します。
using IronPdf;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Print the extracted text (for reference)
Console.WriteLine("Extracted Text: ");
Console.WriteLine(text);
// Parse and print all numbers found in the extracted text
Console.WriteLine("\nParsed Numbers:");
// Use regular expression to find all number patterns, including integers and decimals
var numberMatches = Regex.Matches(text, @"\d+(\.\d+)?");
// Iterate through all matched numbers and print them
foreach (Match match in numberMatches)
{
// Print each matched number
Console.WriteLine($"{match.Value}");
}
}
}using IronPdf;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Print the extracted text (for reference)
Console.WriteLine("Extracted Text: ");
Console.WriteLine(text);
// Parse and print all numbers found in the extracted text
Console.WriteLine("\nParsed Numbers:");
// Use regular expression to find all number patterns, including integers and decimals
var numberMatches = Regex.Matches(text, @"\d+(\.\d+)?");
// Iterate through all matched numbers and print them
foreach (Match match in numberMatches)
{
// Print each matched number
Console.WriteLine($"{match.Value}");
}
}
}Imports Microsoft.VisualBasic
Imports IronPdf
Imports System.Text.RegularExpressions
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile("example.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Print the extracted text (for reference)
Console.WriteLine("Extracted Text: ")
Console.WriteLine(text)
' Parse and print all numbers found in the extracted text
Console.WriteLine(vbLf & "Parsed Numbers:")
' Use regular expression to find all number patterns, including integers and decimals
Dim numberMatches = Regex.Matches(text, "\d+(\.\d+)?")
' Iterate through all matched numbers and print them
For Each match As Match In numberMatches
' Print each matched number
Console.WriteLine($"{match.Value}")
Next match
End Sub
End Class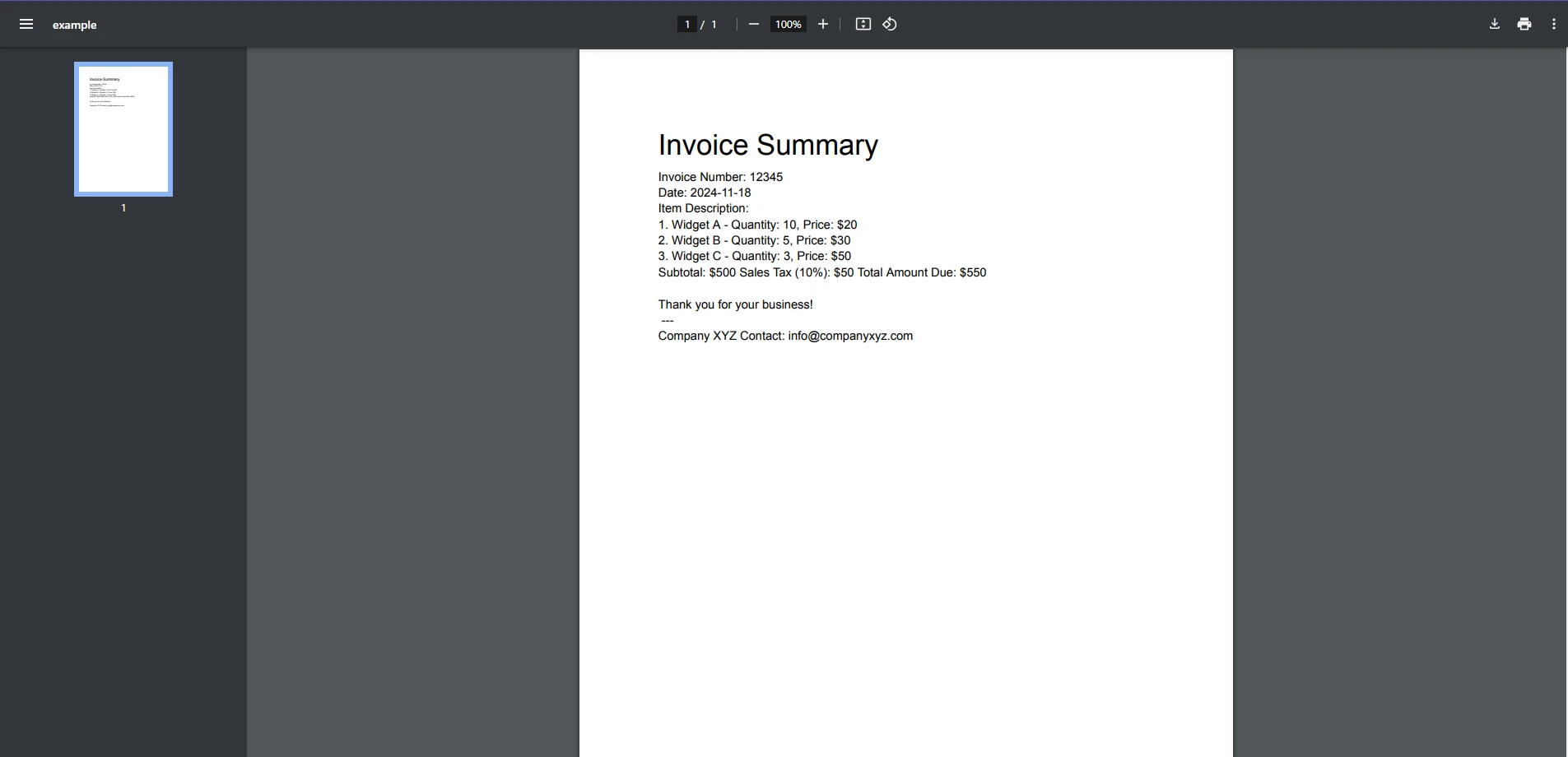
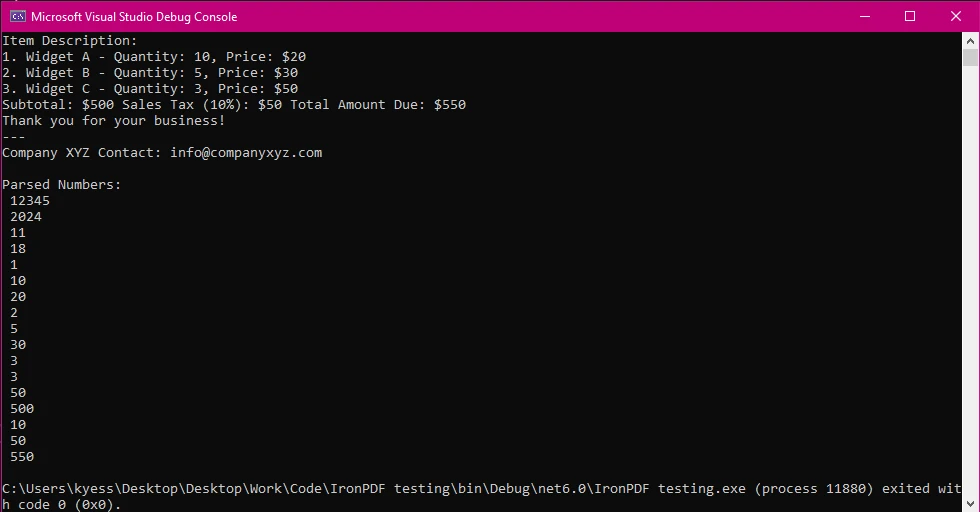
PDFからテキストを抽出
コードは、IronPDFを使用してPDFファイルを読み込むことから始まります。 次に、PDFからすべてのテキストを抽出します。
正規表現を使用して数字を検索:
そのコードは正規表現を使用しています(テキストを一致させるパターン)抽出されたテキストを検索して、任意の数字を見つけます。 正規表現は整数を探します(e.g., 12345)および10進数(例: 50.75).
数値の解析と印刷:
数値が見つかると、プログラムはそれぞれをコンソールに出力します。 これには整数と小数が含まれます。
なぜ正規表現なのか:
正規表現は、数字のようなパターンをテキスト内で見つけるための強力なツールであるため、使用されます。 彼らは記号付きの数字を処理できます。(通貨記号 $ のように)プロセスをより柔軟にするため。
複雑なPDF構造からクリーンなデータを抽出することは、しばしば文字列値をもたらし、その後の処理が必要になる場合があります。例えば、文字列を整数に変換するなどです。 以下は一般的な課題とIronPDFによる解決方法です:
PDFはしばしばテキストとしてフォーマットされた数字を含みます。(例:「1,234.56」または「12,345 USD」). これらを正しく処理するためには、数値の文字列表現が解析のための正しい形式になっていることを確認する必要があります。 IronPDFを使用すると、テキストをきれいに抽出でき、文字列操作メソッドを使用することができます。(例:置換())変換前に書式を調整します。
例:
string formattedNumber = "1,234.56"; // String value with commas
string cleanNumber = formattedNumber.Replace(",", ""); // Remove commas
int result = Convert.ToInt32(Convert.ToDouble(cleanNumber)); // Convert to integer
Console.WriteLine(result); // Outputs: 1234string formattedNumber = "1,234.56"; // String value with commas
string cleanNumber = formattedNumber.Replace(",", ""); // Remove commas
int result = Convert.ToInt32(Convert.ToDouble(cleanNumber)); // Convert to integer
Console.WriteLine(result); // Outputs: 1234Dim formattedNumber As String = "1,234.56" ' String value with commas
Dim cleanNumber As String = formattedNumber.Replace(",", "") ' Remove commas
Dim result As Integer = Convert.ToInt32(Convert.ToDouble(cleanNumber)) ' Convert to integer
Console.WriteLine(result) ' Outputs: 1234複雑なPDFでは、数値が異なる形式で表示されたり、異なる場所に散らばっていることがあります。 IronPDFを使用すると、すべてのテキストを抽出し、正規表現を利用して、文字列を効率的に整数に変換できます。
C#で整数を解析することは、特にユーザー入力やさまざまなソースからのデータ抽出を扱う際に、開発者にとって不可欠なスキルです。 組み込みメソッドのint.Parseのように()および Convert.ToInt32()有用ですが、PDFに含まれるテキストなどの非構造化または半構造化データを扱うことは、追加の課題を呈することがあります。 ここでIronPDFが活躍し、PDFからテキストを抽出し、それを.NETアプリケーションで活用するための強力で簡単なソリューションを提供します。
使用することによってIronPDF、複雑なPDF、スキャンされた文書を含むテキストを簡単に抽出し、そのデータを使用可能な数値に変換する機能を得ることができます。 OCRを使用したスキャンされたPDFや強力なテキスト抽出ツールなどの機能により、IronPDFは困難なフォーマットでもデータ処理を合理化することができます。
請求書、財務報告書、または数値データを含むその他の文書を扱っている場合、C# の ParseInt メソッドと IronPDF を組み合わせることで、より効率的かつ正確に作業することができます。
複雑なPDFで開発プロセスが遅くならないように、使用を開始しましょう。IronPDFは、IronPDF がどのようにワークフローを向上させることができるかを探る絶好の機会ですので、ぜひ試してみて、次のプロジェクトを効率化する方法をご覧ください。
Install-Package IronPdf
クレジットカードは不要です
試用キーはメールに送信されるはずです。![]() 試用版申し込みフォームが
試用版申し込みフォームが
正常に送信されました。
もし届かない場合は、
support@ironsoftware.comにお問い合わせください。
無料で始めましょう
クレジットカードは不要です
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
30日間、完全に機能する製品をご利用いただけます。
数分で稼働させることができます。
製品トライアル期間中にサポートエンジニアリングチームへの完全アクセス





![]() クレジットカードやアカウント作成は不要です。
クレジットカードやアカウント作成は不要です。
試用キーはメールにあるはずです。
もしない場合は、
support@ironsoftware.comまでご連絡ください。
30分の個別デモを予約する。
契約なし、カード情報不要、義務なし。


10 .NET API製品オフィスドキュメントのために