
ライブ環境でテストする
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
C# PDF ライブラリ
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


.NET開発において、異なるデータ型間の変換は重要なスキルであり、特に文字列や整数のような一般的な型を扱う際には不可欠です。 最も頻繁に行う操作の1つは、文字列変数を整数値に変換することです。 ユーザー入力、ファイル、またはデータベースからの数値文字列を扱う際、文字列変数を効率的に整数に変換できることは重要です。 運よく、C#はこれらの変換を効果的に実行するためのさまざまな方法を提供しています。int.Parse()以下のコンテンツを日本語に翻訳してください:int.TryParse()メソッド。
一方で、PDFを扱う際、テキストデータを抽出して操作する能力は、特に請求書、レポート、フォームのような、整数の文字列を含むことが多い文書を取り扱う場合において、さらに重要になります。 ここはIronPDF.NETでPDFを扱うための強力で使いやすいライブラリです。 この記事では、C#で文字列を整数に変換する方法と、IronPDF が .NET プロジェクト内で PDF 関連のタスクを処理するのにどのように役立つかについて説明します。
文字列から整数への変換は、数値データが文字列として提供される多くのアプリケーションで重要なステップです。 以下は一般的な使用例です。
C#では、文字列変数を整数値に変換する方法がいくつかあります。 最も一般的なアプローチには、Parse メソッド、TryParse メソッド、および convert クラスが含まれます。
int.Parse()メソッドは文字列を整数に変換する簡単な方法です。 ただし、入力文字列が正しい形式であることを前提としています。(すなわち、有効な番号)変換が失敗した場合は、FormatExceptionがスローされます。
int number = int.Parse("123");int number = int.Parse("123");Dim number As Integer = Integer.Parse("123")利点:
有効な文字列入力に対してシンプルで直接的です。
欠点:
安全な変換のために、TryParseメソッドがよく使用されます。 変換を試み、その変換が成功したかどうかを示すブール値を返します。 変換が失敗した場合、例外はスローされず、単にfalseが返されます。 結果はアウトパラメータに格納されます。
bool success = int.TryParse("123", out int result);bool success = int.TryParse("123", out int result);Dim result As Integer
Dim success As Boolean = Integer.TryParse("123", result)ここで、successは変換が成功したかどうかを示すブール値であり、numberは変換された整数で、outパラメータに格納されます。
利点:
文字列が有効な数字かどうか確信が持てないシナリオに最適です。
欠点:
文字列変数を整数値に変換するもう一つの方法は、convertクラスを使用することです。 変換クラスには、文字列を整数に変換するなど、異なるデータ型を変換できるメソッドが含まれています。
int number = Convert.ToInt32("123");int number = Convert.ToInt32("123");Dim number As Integer = Convert.ToInt32("123")利点:
変換クラスは、文字列や整数だけでなく、より広範なデータ型を扱うことができます。
欠点:
PDFを扱う際、ドキュメントに埋め込まれた整数文字列を抽出して処理する必要があるかもしれません。 IronPDFPDF操作を簡略化し、テキストや数値をシームレスに抽出できます。 これは、請求書番号、数量、その他の重要なデータを抽出して変換する必要があるシナリオで特に役立ちます。
IronPDFは、PDFを操作するための包括的な機能セットを提供しています。含まれるもの:
PDFバージョンサポート: PDFバージョン1.2-1.7をサポート可能
これらの機能により、IronPDFは単純なレポートから複雑なドキュメント処理システムまで、PDF機能を必要とするあらゆるアプリケーションにとって強力なツールとなります。
文字列を整数に変換し、PDFを扱う重要なシナリオの一つは、PDFから数値データを抽出する必要がある場合です。 たとえば、PDFドキュメントから請求書番号、注文ID、数量を抽出したい場合があり、これらはしばしば文字列として表示されます。 次の例では、IronPDFを使用してPDFからテキストを抽出し、TryParseメソッドを使用して整数の文字列を整数値に変換する方法を示します。
IronPDFを使用すると、PDFからテキストを抽出し、int.TryParseを使用して数値文字列を整数に変換できます。(). 次の方法で:
public static void Main(string[] args)
{
PdfDocument pdf = PdfDocument.FromFile("invoice.pdf");
// Extract text from the PDF
string extractedText = pdf.ExtractAllText();
// Use regex to extract potential numbers from the text
var matches = Regex.Matches(extractedText, @"\d+");
if (matches.Count > 0)
{
Console.WriteLine("Extracted number(s) from PDF:");
foreach (Match match in matches)
{
if (int.TryParse(match.Value, out int num))
{
Console.WriteLine(num);
}
}
}
else
{
Console.WriteLine("Could not find any numbers in the extracted text.");
}
}public static void Main(string[] args)
{
PdfDocument pdf = PdfDocument.FromFile("invoice.pdf");
// Extract text from the PDF
string extractedText = pdf.ExtractAllText();
// Use regex to extract potential numbers from the text
var matches = Regex.Matches(extractedText, @"\d+");
if (matches.Count > 0)
{
Console.WriteLine("Extracted number(s) from PDF:");
foreach (Match match in matches)
{
if (int.TryParse(match.Value, out int num))
{
Console.WriteLine(num);
}
}
}
else
{
Console.WriteLine("Could not find any numbers in the extracted text.");
}
}Public Shared Sub Main(ByVal args() As String)
Dim pdf As PdfDocument = PdfDocument.FromFile("invoice.pdf")
' Extract text from the PDF
Dim extractedText As String = pdf.ExtractAllText()
' Use regex to extract potential numbers from the text
Dim matches = Regex.Matches(extractedText, "\d+")
If matches.Count > 0 Then
Console.WriteLine("Extracted number(s) from PDF:")
For Each match As Match In matches
Dim num As Integer
If Integer.TryParse(match.Value, num) Then
Console.WriteLine(num)
End If
Next match
Else
Console.WriteLine("Could not find any numbers in the extracted text.")
End If
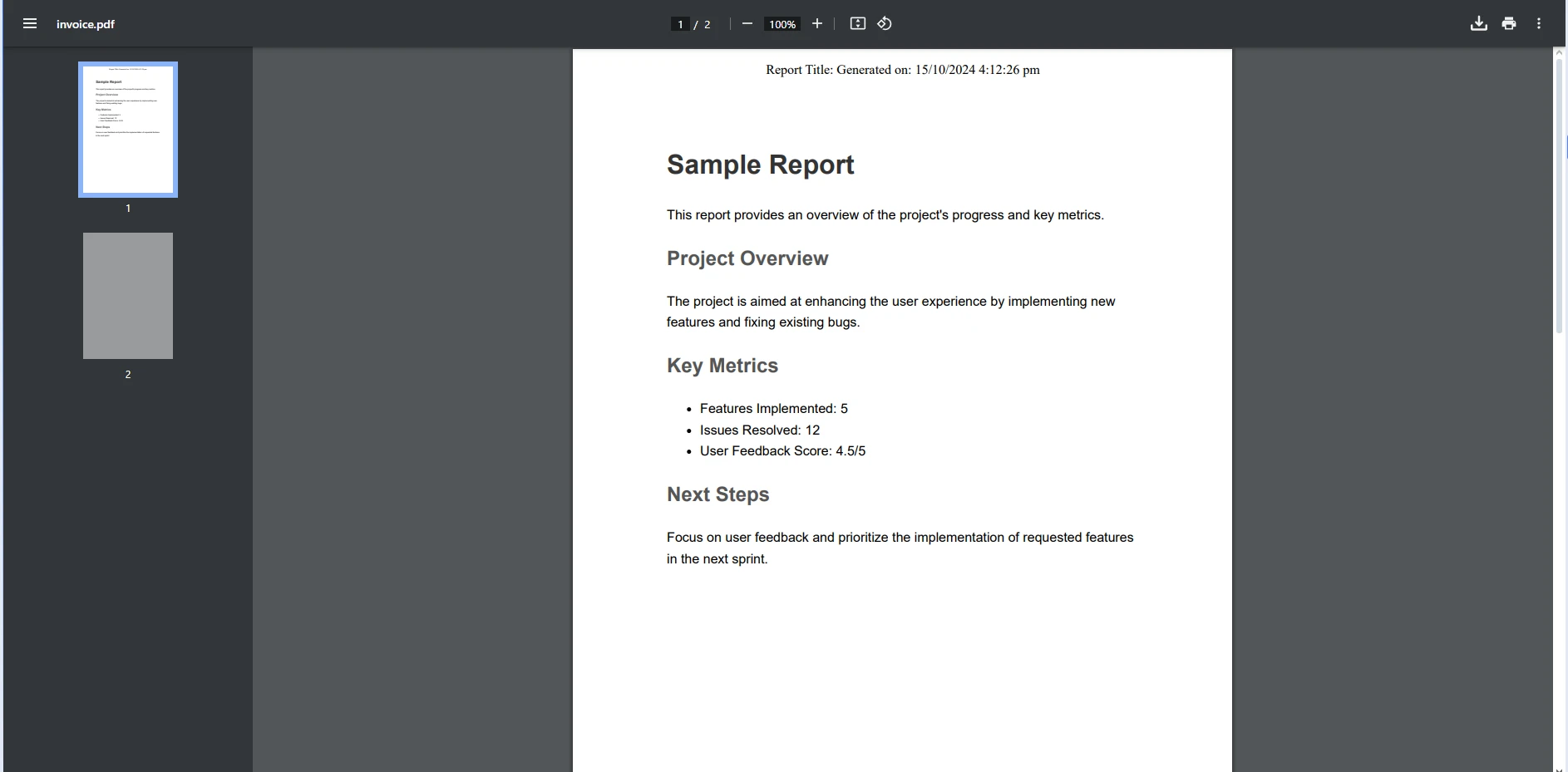
End SubインプットPDF
コンソール出力
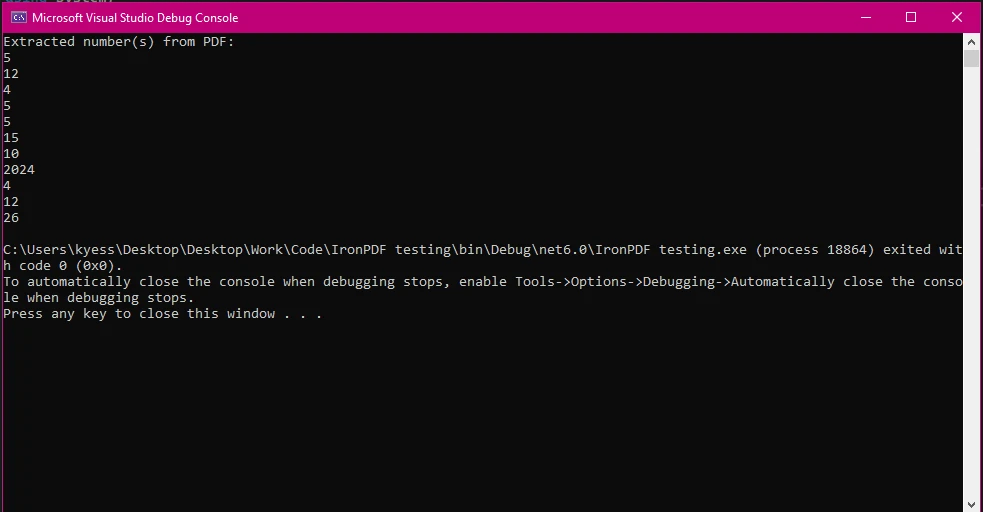
このコード例では、「invoice.pdf」という名前のPDFファイルを読み込み、ExtractAllText を使用してドキュメントからすべてのテキストを抽出する前に始めます。() メソッド 抽出されたテキスト内の潜在的な数字を識別するために、コードは正規表現を適用します。(正規表現)** \d+ は、数字のシーケンスに一致します。
一致が保存され、数字が見つかった場合はコンソールに表示されます。 int.TryParse を使用して、各一致が個別に整数として解析されます。()、有効な数値のみが処理されるようにします。 数字が見つからない場合、番号が抽出されなかったことを示すメッセージが表示されます。 この方法は、請求書のような数値データを含むPDFを処理する際に、数値の抽出と変換が重要である場合に役立ちます。
抽出されたPDFテキストを整数に変換することが有用なシナリオをいくつか紹介します:
文字列を整数に変換することは、特に外部データソースを扱う際に、C#での基本的なスキルです。 int.Parse()およびint.TryParse()これらの変換を柔軟に処理する方法を提供し、シンプルさと安全性の両方を確保します。
その間IronPDF.NET開発者が複雑なPDFワークフローを簡単に扱えるようにします。 テキストの抽出、動的レポートの作成、またはPDFデータの利用可能な形式への変換を行う場合、IronPDFは開発ツールキットにとって貴重な追加ツールです。
IronPDFを試してみたいですか? 今日から無料トライアルを始めましょうインストールして、.NET アプリケーションでのPDFの取り扱い方法をどのようにIronPDFが変えることができるか体験してください。!
Install-Package IronPdf
クレジットカードは不要です
試用キーはメールに送信されるはずです。![]() 試用版申し込みフォームが
試用版申し込みフォームが
正常に送信されました。
もし届かない場合は、
support@ironsoftware.comにお問い合わせください。
無料で始めましょう
クレジットカードは不要です
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
30日間、完全に機能する製品をご利用いただけます。
数分で稼働させることができます。
製品トライアル期間中にサポートエンジニアリングチームへの完全アクセス





![]() クレジットカードやアカウント作成は不要です。
クレジットカードやアカウント作成は不要です。
試用キーはメールにあるはずです。
もしない場合は、
support@ironsoftware.comまでご連絡ください。
30分の個別デモを予約する。
契約なし、カード情報不要、義務なし。


10 .NET API製品オフィスドキュメントのために