
ライブ環境でテストする
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
C# PDF ライブラリ
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


テキスト操作は、.NET 開発者にとって重要なスキルです。 ユーザー入力の文字列をクリーンアップしたり、分析のためのデータをフォーマットしたり、ドキュメントから抽出したテキストを処理したりするときに、適切なツールを持っていることで差が生まれます。 PDFを扱う際には、その非構造的な性質のために、テキストを効率的に管理および処理することが困難です。 そこで、IronPDF、C#でPDFを扱う強力なライブラリが輝きます。
この記事では、C#のTrim()メソッドをIronPDFと組み合わせて利用し、PDFドキュメントからテキストを効果的にクリーンアップおよび処理する方法を探ります。
Trim() メソッドは、文字列の先頭と末尾から空白または指定された文字を削除します。 例えば:
string text = " Hello World! ";
string trimmedText = text.Trim(); // Output: "Hello World!" string text = " Hello World! ";
string trimmedText = text.Trim(); // Output: "Hello World!" Dim text As String = " Hello World! "
Dim trimmedText As String = text.Trim() ' Output: "Hello World!"また、特定の文字を対象にすることもできます。例えば、文字列から#記号を削除することなどが可能です。
string text = "###Important###";
string trimmedText = text.Trim('#'); // Output: "Important" string text = "###Important###";
string trimmedText = text.Trim('#'); // Output: "Important" Dim text As String = "###Important###"
Dim trimmedText As String = text.Trim("#"c) ' Output: "Important"C# は、文字列の先頭または末尾から文字を削除するために TrimStart() と TrimEnd() を提供します。 例えば:
string str = "!!Hello World!!";
string trimmedStart = str.TrimStart('!'); // "Hello World!!"
string trimmedEnd = str.TrimEnd('!'); // "!!Hello World" string str = "!!Hello World!!";
string trimmedStart = str.TrimStart('!'); // "Hello World!!"
string trimmedEnd = str.TrimEnd('!'); // "!!Hello World" Dim str As String = "!!Hello World!!"
Dim trimmedStart As String = str.TrimStart("!"c) ' "Hello World!!"
Dim trimmedEnd As String = str.TrimEnd("!"c) ' "!!Hello World"null文字列に対してTrim()を呼び出すとエラーが発生します。 これを避けるために、null合体演算子または条件チェックを使用します。
string text = null;
string safeTrim = text?.Trim() ?? string.Empty; string text = null;
string safeTrim = text?.Trim() ?? string.Empty; Dim text As String = Nothing
Dim safeTrim As String = If(text?.Trim(), String.Empty)C#の文字列は不変なので、ループ内での繰り返しTrim()操作はパフォーマンスを低下させる可能性があります。 大規模なデータセットの場合、Span\<T> を使用するか、変数を再利用することを検討してください。
必要な文字を誤って削除することは、よくある間違いです。 常に正確な文字を指定して、空白以外のコンテンツを処理するときにトリムしてください。
デフォルトのTrim()メソッドは特定のUnicode空白文字(例: \u2003)を処理しません。 これに対処するために、それらを明示的にトリムパラメータに含めます。
複雑なパターンの場合、Trim()を正規表現と組み合わせて使用します。 たとえば、複数のスペースを置き換えるためには:
string cleanedText = Regex.Replace(text, @"^\s+
\s+$", ""); string cleanedText = Regex.Replace(text, @"^\s+
\s+$", ""); Dim cleanedText As String = Regex.Replace(text, "^\s+
\s+$", "")大きなテキストを処理する際は、繰り返しのトリミング操作を避けてください。 StringBuilderを前処理に使用する:
var sb = new StringBuilder(text);
sb.Trim(); // Custom extension method to trim once var sb = new StringBuilder(text);
sb.Trim(); // Custom extension method to trim once Dim sb = New StringBuilder(text)
sb.Trim() ' Custom extension method to trim onceTrim() はカルチャに依存しませんが、稀なケースでロケールに依存したトリミングを行うには、CultureInfo を使用できます。
PDFからテキストを抽出する際、先行および後続の特殊文字、不要なスペース、またはフォーマットの不具合のような文字に遭遇することがよくあります。 例えば:
OCR生成コンテンツでは、先頭と末尾にシンボル(例:*、-)が出現することがよくあります。
Trim() を使用すると、現在の文字列オブジェクトを整理し、さらなる操作の準備をすることができます。
IronPDF は、PDFファイルを簡単に操作できるように設計された、.NET用の強力なPDF操作ライブラリです。 それは最小限のセットアップとコーディングの努力で、PDFからコンテンツを生成、編集、抽出する機能を提供します。 以下にIronPDFの主な機能をいくつか紹介します。
IronPDFは、非構造化PDFデータの処理に優れ、テキストを効率的に抽出、整形、処理することを容易にします。 ユースケースには以下が含まれます。
まず、NuGetを通じてIronPDFをインストールします。
Visual Studioでプロジェクトを開きます。
Install-Package IronPDFInstall-Package IronPDF'INSTANT VB TODO TASK: The following line uses invalid syntax:
'Install-Package IronPDF以下は、PDFからテキストを抽出し、指定した文字を削除するために Trim() を使用してテキストをクリーンアップする完全な例です。
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("trimSample.pdf");
// Extract text from the PDF
string extractedText = pdf.ExtractAllText();
// Trim whitespace and unwanted characters
string trimmedText = extractedText.Trim('*');
// Display the cleaned text
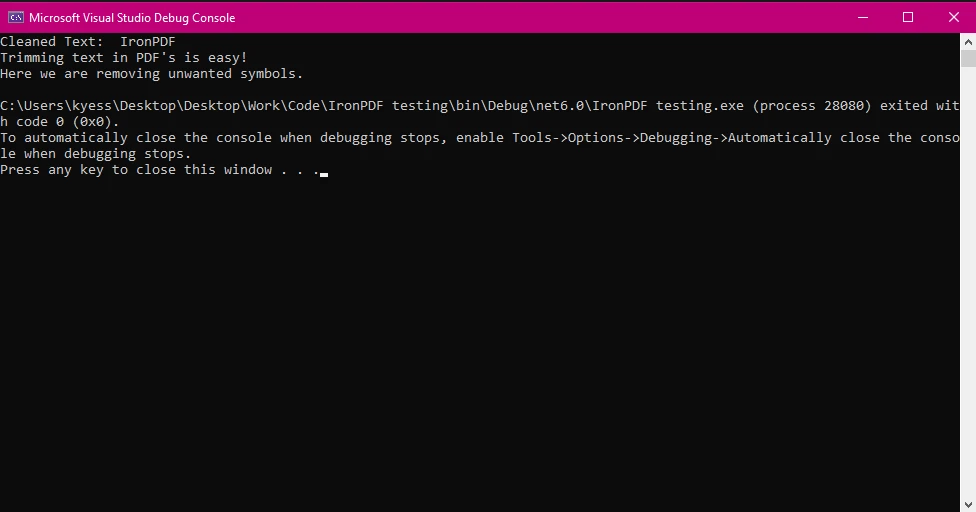
Console.WriteLine($"Cleaned Text: {trimmedText}");
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("trimSample.pdf");
// Extract text from the PDF
string extractedText = pdf.ExtractAllText();
// Trim whitespace and unwanted characters
string trimmedText = extractedText.Trim('*');
// Display the cleaned text
Console.WriteLine($"Cleaned Text: {trimmedText}");
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile("trimSample.pdf")
' Extract text from the PDF
Dim extractedText As String = pdf.ExtractAllText()
' Trim whitespace and unwanted characters
Dim trimmedText As String = extractedText.Trim("*"c)
' Display the cleaned text
Console.WriteLine($"Cleaned Text: {trimmedText}")
End Sub
End Class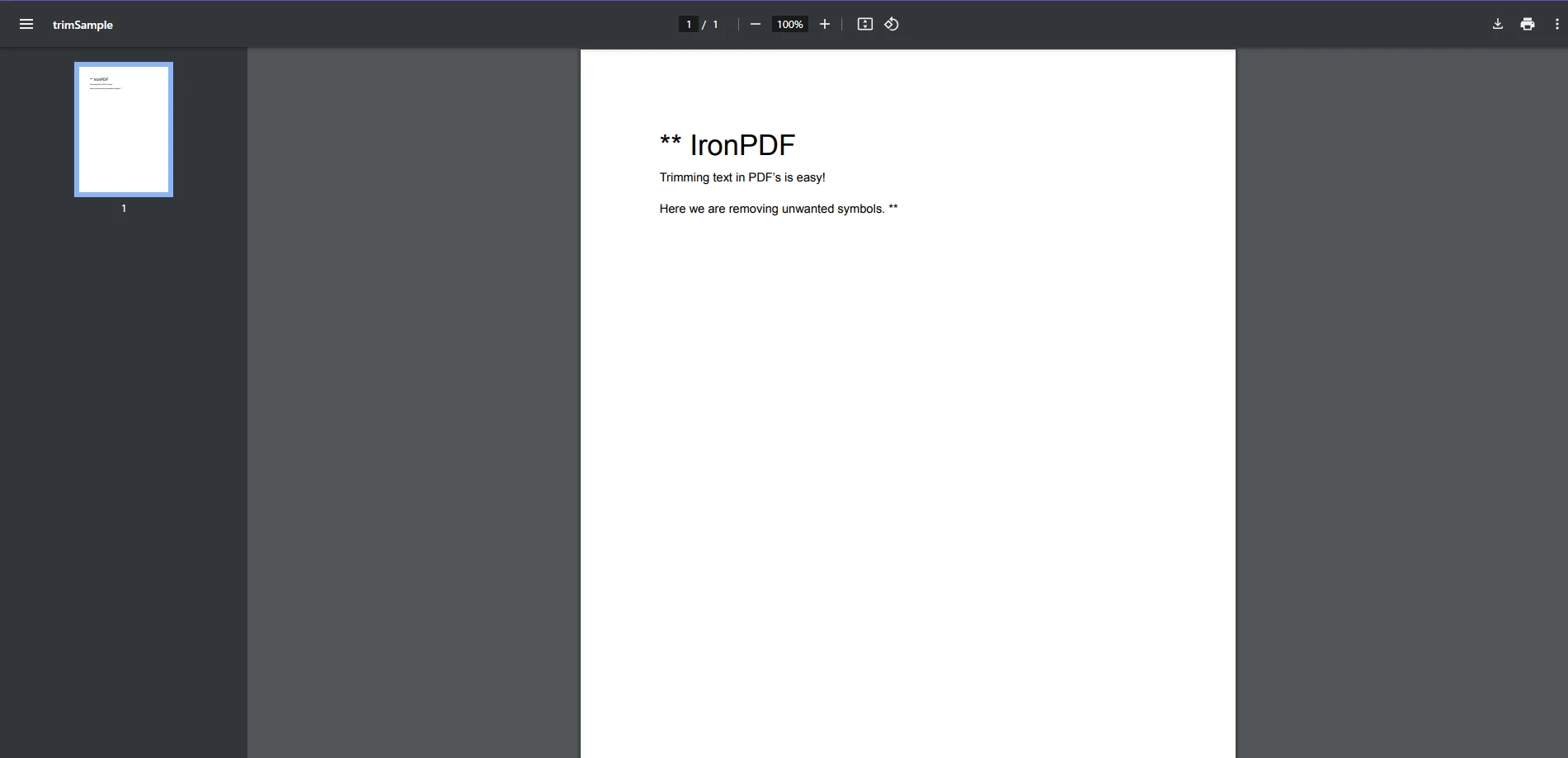
PDF請求書からテキストを抽出し、不要なコンテンツをトリミングして、合計や請求書IDのような重要な詳細を解析します。 例:
光学文字認識(OCR)はしばしばノイズの多いテキストを生成します。 IronPDFのテキスト抽出とC#トリミング機能を使用することで、さらなる処理や分析のために出力を整理することができます。
効率的なテキスト処理は、特にPDFからの非構造化データを扱う際に、.NET開発者にとって重要なスキルです。 Trim() メソッド、特に public string Trim は、IronPDF の機能と組み合わせることで、先頭と末尾の空白、指定された文字、および Unicode 文字を削除してテキストをクリーンアップし処理するための信頼性の高い方法を提供します。
TrimEnd() のようなメソッドを適用して末尾の文字を削除したり、末尾のトリム操作を行ったりすることで、ノイズの多いテキストを、レポート、オートメーション、分析に使用できるコンテンツに変換することができます。 上記の方法により、開発者は既存の文字列を正確にクリーンアップし、PDFを含むワークフローを強化することができます。
IronPDFの強力なPDF操作機能とC#の多用途なTrim()メソッドを組み合わせることで、正確なテキストフォーマットを必要とするソリューションの開発において時間と労力を節約できます。 かつて時間がかかっていたタスク、例えば不要な空白の削除、OCR生成テキストの整理、抽出データの標準化などが、今では数分で完了できます。
今日、あなたのPDF処理能力を次のレベルに引き上げましょう—無料のIronPDFトライアルをダウンロードし、.NET開発体験がどのように変わるかを直接ご確認ください。 初心者でも経験豊富な開発者でも、IronPDFは、よりスマートで、迅速かつ効率的なソリューションを構築するためのパートナーです。
Install-Package IronPdf
クレジットカードは不要です
試用キーはメールに送信されるはずです。![]() 試用版申し込みフォームが
試用版申し込みフォームが
正常に送信されました。
もし届かない場合は、
support@ironsoftware.comにお問い合わせください。
無料で始めましょう
クレジットカードは不要です
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
30日間、完全に機能する製品をご利用いただけます。
数分で稼働させることができます。
製品トライアル期間中にサポートエンジニアリングチームへの完全アクセス





![]() クレジットカードやアカウント作成は不要です。
クレジットカードやアカウント作成は不要です。
試用キーはメールにあるはずです。
もしない場合は、
support@ironsoftware.comまでご連絡ください。
30分の個別デモを予約する。
契約なし、カード情報不要、義務なし。


10 .NET API製品オフィスドキュメントのために