
ライブ環境でテストする
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
C# PDF ライブラリ
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


現代の開発の世界では、ドキュメント、フォーム、レポートを扱う必要があるアプリケーションにおいて、PDFを扱うことは一般的な要件です。 eコマースプラットフォーム、ドキュメント管理システムを構築している場合や、請求書を処理する必要があるだけの場合でも、PDFからテキストを抽出し検索することは重要です。 この記事では、使用方法について説明します。C# string.Contains()と一緒にIronPDF.NETプロジェクトでPDFファイルからテキストを検索して抽出するために。
検索を行う際には、特定の文字列部分文字列の要件に基づいて文字列の比較を行う必要があるかもしれません。 そのような場合、C#はstring.Containsのようなオプションを提供します。()、最も単純な比較の形式の一つです。
ケース感度を無視するかどうかを指定する必要がある場合は、StringComparison列挙体を使用できます。 これにより、オーディナル比較や大文字小文字を区別しない比較など、希望する文字列比較の種類を選択できます。
文字列内の特定の位置、例えば最初の文字位置や最後の文字位置で作業したい場合は、常にSubstringを使用して文字列の特定の部分を抽出し、さらなる処理を行うことができます。
空の文字列チェックやその他のエッジケースを探している場合は、これらのシナリオをロジック内で確実に処理してください。
大規模なドキュメントを扱う場合、テキスト抽出の開始位置を最適化し、ドキュメント全体ではなく関連する部分のみを抽出することが有効です。 これは、メモリおよび処理時間の過負荷を回避しようとする場合に特に役立ちます。
比較ルールの最適なアプローチがわからない場合は、特定のメソッドの性能と、異なるシナリオで検索がどのように動作することを望んでいるかを考慮してください。(例: 複数の用語の照合、スペースの処理など。).
必要条件が単純な部分文字列のチェックを超え、より高度なパターンマッチングを必要とする場合は、正規表現を使用することを検討してください。これは、PDFを扱う際に大きな柔軟性を提供します。
まだ試していない場合は、IronPDFをお試しください。無料試用その機能を調査し、PDF処理タスクをどのように効率化できるかを確認するために、今日から始めましょう。 ドキュメント管理システムの構築や請求書の処理、またはPDFからデータを抽出する必要がある場合、IronPDFはその仕事に最適なツールです。
IronPDFは、.NETエコシステムでPDFを扱う開発者を支援するために設計された強力なライブラリです。 これは、外部ツールや複雑な構成に頼ることなく、PDFファイルを簡単に作成、読み取り、編集、および操作することを可能にします。
IronPDFは、C#アプリケーションでPDFを操作するための幅広い機能を提供します。 主な特徴は以下の通り:
フォーム処理: インタラクティブなPDFフォームでフォームフィールドを抽出または入力します。
IronPDFはシンプルに使えるように設計されていますが、PDFを含む複雑なシナリオにも対応できる柔軟性も備えています。 それは、.NET Coreおよび.NET Frameworkとシームレスに連携し、あらゆる.NETベースのプロジェクトに最適です。
使用するにはIronPDFNuGet パッケージ マネージャーを使用して Visual Studio にインストールします。
Install-Package IronPdfInstall-Package IronPdf'INSTANT VB TODO TASK: The following line uses invalid syntax:
'Install-Package IronPdfPDFの検索に入る前に、まずIronPDFを使用してPDFからテキストを抽出する方法を理解しましょう。
IronPDFは、PDFドキュメントからテキストを抽出するためのシンプルなAPIを提供します。 これにより、PDF内の特定のコンテンツを簡単に検索できます。
次の例は、IronPDFを使用してPDFからテキストを抽出する方法を示しています。
using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
PdfDocument pdf = PdfDocument.FromFile("invoice.pdf");
string str = pdf.ExtractAllText();
}
}using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
PdfDocument pdf = PdfDocument.FromFile("invoice.pdf");
string str = pdf.ExtractAllText();
}
}Imports IronPdf
Imports System
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim pdf As PdfDocument = PdfDocument.FromFile("invoice.pdf")
Dim str As String = pdf.ExtractAllText()
End Sub
End Classこの例では、ExtractAllText()メソッドは、PDFドキュメントからすべてのテキストを抽出します。 このテキストはその後、特定のキーワードやフレーズを検索するために処理されます。
PDFからテキストを抽出したら、C#の組み込み関数であるstring.Containsを使用することができます。()特定の単語やフレーズを検索する方法。
文字列.Contains()** メソッドは、指定された文字列が文字列内に存在するかどうかを示すブール値を返します。 これは基本的なテキスト検索に特に有用です。
以下は、string.Containsを使用する方法です。()抽出されたテキスト内でキーワードを検索する:
bool isFound = text.Contains("search term", StringComparison.OrdinalIgnoreCase);bool isFound = text.Contains("search term", StringComparison.OrdinalIgnoreCase);Dim isFound As Boolean = text.Contains("search term", StringComparison.OrdinalIgnoreCase)実用的な例でさらに分解してみましょう。 特定の請求書番号がPDF請求書ドキュメントに存在するかどうかを見つけたいとします。
以下に、これを実装する方法の完全な例を示します。
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string searchTerm = "INV-12345";
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
string text = pdf.ExtractAllText();
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
if (isFound)
{
Console.WriteLine($"Invoice number: {searchTerm} found in the document");
}
else
{
Console.WriteLine($"Invoice number {searchTerm} not found in the document");
}
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string searchTerm = "INV-12345";
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
string text = pdf.ExtractAllText();
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
if (isFound)
{
Console.WriteLine($"Invoice number: {searchTerm} found in the document");
}
else
{
Console.WriteLine($"Invoice number {searchTerm} not found in the document");
}
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim searchTerm As String = "INV-12345"
Dim pdf As PdfDocument = PdfDocument.FromFile("exampleInvoice.pdf")
Dim text As String = pdf.ExtractAllText()
Dim isFound As Boolean = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase)
If isFound Then
Console.WriteLine($"Invoice number: {searchTerm} found in the document")
Else
Console.WriteLine($"Invoice number {searchTerm} not found in the document")
End If
End Sub
End Class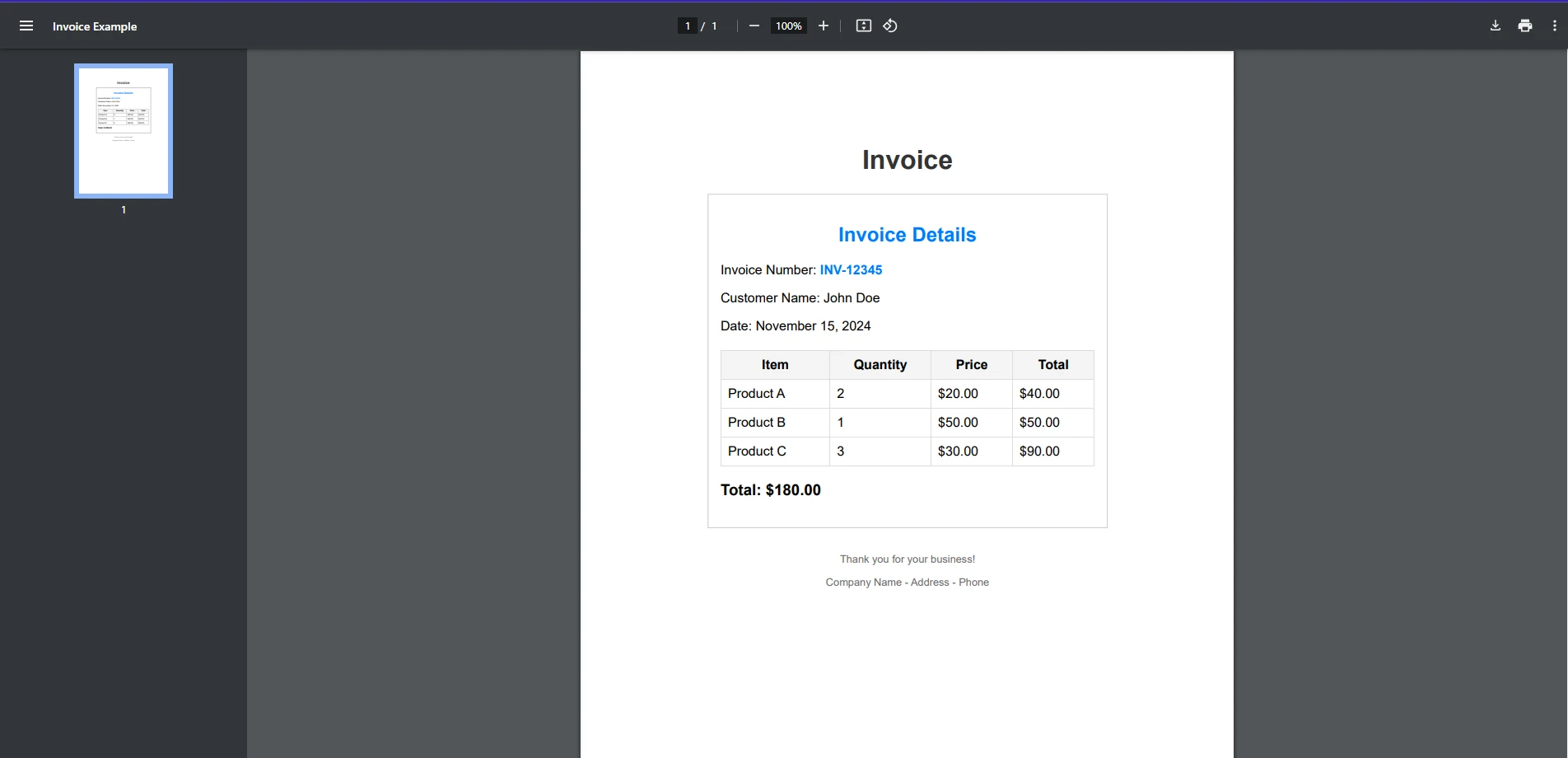
この例では:
string.Contains を使用する際()単純な部分文字列の検索には適していますが、パターンや一連のキーワードを見つけるなど、より複雑な検索を行いたい場合があります。 これには、正規表現を使用できます。
PDFテキスト内の有効な請求書番号形式を検索するための正規表現を使用した例を次に示します。
using IronPdf;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Define a regex pattern for a typical invoice number format (e.g., INV-12345)
string pattern = @"INV-\d{5}";
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
string text = pdf.ExtractAllText();
// Perform the regex search
Match match = Regex.Match(text, pattern);
}
}using IronPdf;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Define a regex pattern for a typical invoice number format (e.g., INV-12345)
string pattern = @"INV-\d{5}";
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
string text = pdf.ExtractAllText();
// Perform the regex search
Match match = Regex.Match(text, pattern);
}
}Imports IronPdf
Imports System.Text.RegularExpressions
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Define a regex pattern for a typical invoice number format (e.g., INV-12345)
Dim pattern As String = "INV-\d{5}"
Dim pdf As PdfDocument = PdfDocument.FromFile("exampleInvoice.pdf")
Dim text As String = pdf.ExtractAllText()
' Perform the regex search
Dim match As Match = Regex.Match(text, pattern)
End Sub
End Classこのコードは、INV-XXXXXというパターンに従う請求書番号を検索します。ここで、XXXXXは数字の並びです。
PDFを扱う際、特に大きなまたは複雑なドキュメントの場合、いくつかのベストプラクティスを心に留めておく必要があります。
IronPDFは.NETプロジェクトに簡単に統合できます。 NuGetを介してIronPDFライブラリをダウンロードおよびインストールした後、上記の例に示されているように、単にそれをC#コードベースにインポートします。
IronPDFの柔軟性により、以下のような高度なドキュメント処理ワークフローを構築できます。
IronPDFPDFの作業を簡単かつ効率的に行うことができ、特にPDF内のテキストを抽出して検索する必要がある場合に便利です。 C#のstring.Containsを組み合わせることによって()IronPDFのテキスト抽出機能を使用することで、.NETアプリケーション内でPDFを迅速に検索および処理できます。
まだ試していない場合は、今日中にIronPDFの無料トライアルをお試しください。その機能を探索し、PDF処理の作業をどのように効率化できるかをご確認ください。 ドキュメント管理システムの構築や請求書の処理、またはPDFからデータを抽出する必要がある場合、IronPDFはその仕事に最適なツールです。
IronPDFの使用を開始するには、ダウンロードしてください。無料試用その強力なPDF操作機能を直接体験してください。 訪問するIronPDFのウェブサイト今日から始めましょう。
Install-Package IronPdf
クレジットカードは不要です
試用キーはメールに送信されるはずです。![]() 試用版申し込みフォームが
試用版申し込みフォームが
正常に送信されました。
もし届かない場合は、
support@ironsoftware.comにお問い合わせください。
無料で始めましょう
クレジットカードは不要です
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
30日間、完全に機能する製品をご利用いただけます。
数分で稼働させることができます。
製品トライアル期間中にサポートエンジニアリングチームへの完全アクセス





![]() クレジットカードやアカウント作成は不要です。
クレジットカードやアカウント作成は不要です。
試用キーはメールにあるはずです。
もしない場合は、
support@ironsoftware.comまでご連絡ください。
30分の個別デモを予約する。
契約なし、カード情報不要、義務なし。


10 .NET API製品オフィスドキュメントのために