
ライブ環境でテストする
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
C# PDF ライブラリ
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


Parallel.ForEachは、コレクションまたはデータソースに対して並列イテレーションを実行できるC#のメソッドです。 コレクション内の各項目を順次処理する代わりに、並列ループは同時実行を可能にし、全体の実行時間を減らすことでパフォーマンスを大幅に向上させることができます。並列処理は、作業を複数のコアプロセッサに分配し、タスクを同時に実行することで機能します。 これは、互いに独立したタスクを処理する際に特に有用です。
通常のforeachループがアイテムを順番に処理するのに対し、並列アプローチは複数のスレッドを並行して利用することで、大規模なデータセットをより迅速に処理することができます。
IronPDFは、.NETでPDFを扱うための強力なライブラリです。HTMLをPDFに変換, PDFからのテキスト抽出, ドキュメントの結合と分割など。 大量のPDFタスクを処理する際には、Parallel.ForEachを使用して並列処理を行うことで実行時間を大幅に短縮できます。数百のPDFを生成する場合でも、複数のファイルから一度にデータを抽出する場合でも、IronPDFを活用してデータ並列性を利用することで、タスクをより迅速かつ効率的に完了することが可能です。
このガイドは、IronPDFとParallel.ForEachを使用してPDF処理タスクを最適化したい.NET開発者向けに作成されています。 C#の基本的な知識とIronPDFライブラリに関する馴染みは推奨されます。 このガイドの終わりまでに、複数のPDFタスクを同時に処理するための並列処理を実装できるようになり、パフォーマンスとスケーラビリティの両方が向上します。
使用するにはIronPDFプロジェクトでライブラリをインストールするには、NuGetを使用する必要があります。
IronPDFをインストールするには、次の手順に従ってください。
Visual Studioでプロジェクトを開きます。
ツール → NuGet パッケージ マネージャー → ソリューションの NuGet パッケージの管理 に進みます。
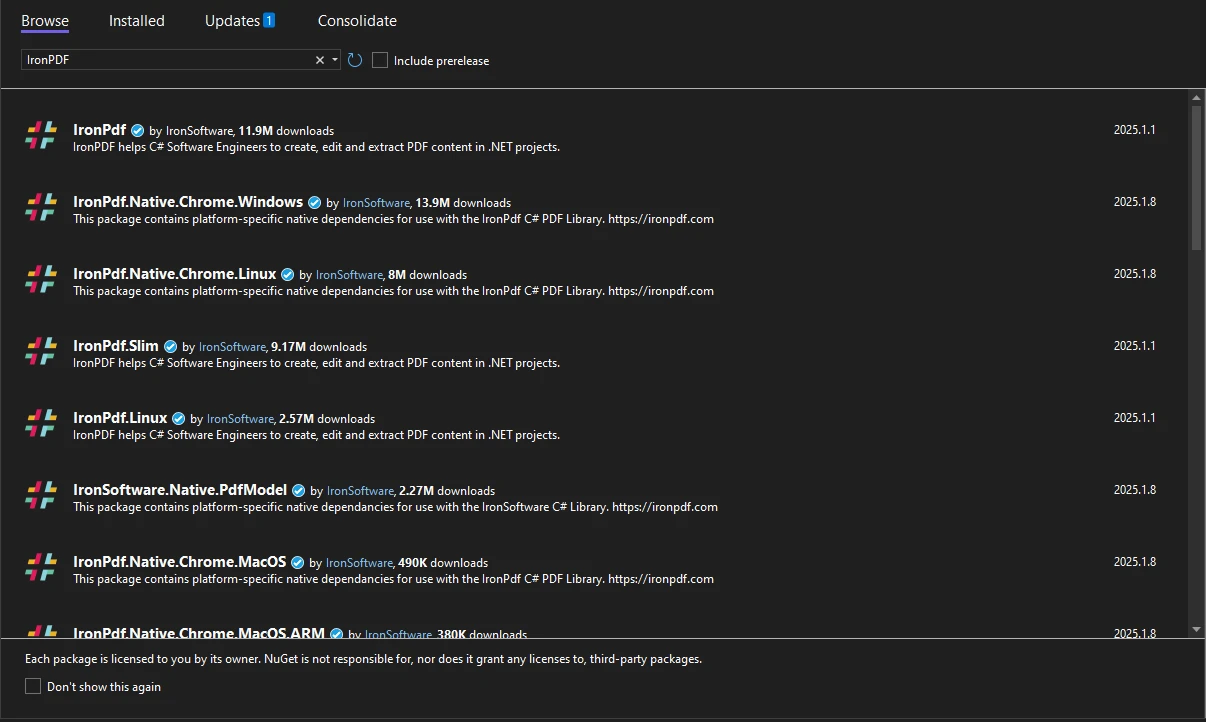
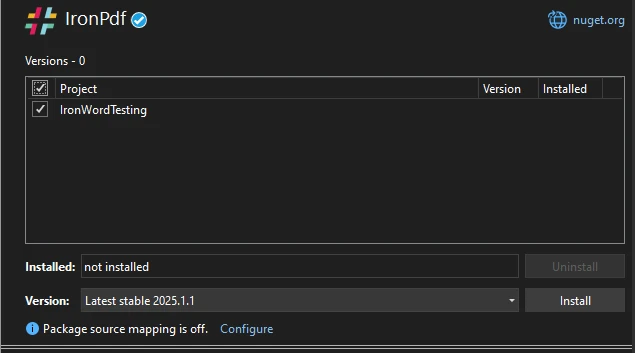
または、NuGet パッケージ マネージャー コンソールを介してインストールすることもできます。
Install-Package IronPdfInstall-Package IronPdf'INSTANT VB TODO TASK: The following line uses invalid syntax:
'Install-Package IronPdfIronPDFをインストールしたら、PDFの生成および操作タスクに使用する準備が整います。
Parallel.ForEach は System.Threading.Tasks 名前空間の一部であり、反復処理を並行して実行するためのシンプルで効果的な方法を提供します。 Parallel.ForEachの構文は次のとおりです。
Parallel.ForEach(collection, item =>
{
// Code to process each item
});Parallel.ForEach(collection, item =>
{
// Code to process each item
});Parallel.ForEach(collection, Sub(item)
' Code to process each item
End Sub)コレクション内の各項目は並行して処理され、システムが利用可能なスレッド間で作業負荷をどのように分散するかを決定します。 また、使用するスレッドの最大数など、並列度を制御するオプションを指定することもできます。
比較すると、従来のforeachループは各アイテムを順番に処理しますが、並列ループは複数のアイテムを同時に処理でき、大量のコレクションを扱う際のパフォーマンスを向上させます。
まず、はじめにガイドの「Getting Started」セクションに記載されているようにIronPDFがインストールされていることを確認してください。 その後、並列PDF処理ロジックの作成を開始できます。
string[] htmlPages = { "page1.html", "page2.html", "page3.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
});string[] htmlPages = { "page1.html", "page2.html", "page3.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
});Dim htmlPages() As String = { "page1.html", "page2.html", "page3.html" }
Parallel.ForEach(htmlFiles, Sub(htmlFile)
' Load the HTML content into IronPDF and convert it to PDF
Dim renederer As New ChromePdfRenderer()
Dim pdf As PdfDocument = renederer.RenderHtmlAsPdf(htmlFile)
' Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf")
End Sub)このコードは、複数のHTMLページを並列でPDFに変換する方法を示しています。
並行タスクを扱う際には、エラーハンドリングが重要です。 Parallel.ForEachループ内でtry-catchブロックを使用して、例外を管理します。
Parallel.ForEach(pdfFiles, pdfFile =>
{
try
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractAllText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {pdfFile}: {ex.Message}");
}
});Parallel.ForEach(pdfFiles, pdfFile =>
{
try
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractAllText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {pdfFile}: {ex.Message}");
}
});Parallel.ForEach(pdfFiles, Sub(pdfFile)
Try
Dim pdf = IronPdf.PdfDocument.FromFile(pdfFile)
Dim text As String = pdf.ExtractAllText()
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text)
Catch ex As Exception
Console.WriteLine($"Error processing {pdfFile}: {ex.Message}")
End Try
End Sub)並列処理の別の使用例として、複数のPDFからのテキスト抽出があります。 複数のPDFファイルを扱う際、テキスト抽出を同時に実行することで多くの時間を節約できます。以下の例はその方法を示しています。
using IronPdf;
using System.Linq;
using System.Threading.Tasks;
class Program
{
static void Main(string[] args)
{
string[] pdfFiles = { "doc1.pdf", "doc2.pdf", "doc3.pdf" };
Parallel.ForEach(pdfFiles, pdfFile =>
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
});
}
}using IronPdf;
using System.Linq;
using System.Threading.Tasks;
class Program
{
static void Main(string[] args)
{
string[] pdfFiles = { "doc1.pdf", "doc2.pdf", "doc3.pdf" };
Parallel.ForEach(pdfFiles, pdfFile =>
{
var pdf = IronPdf.PdfDocument.FromFile(pdfFile);
string text = pdf.ExtractText();
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text);
});
}
}Imports IronPdf
Imports System.Linq
Imports System.Threading.Tasks
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim pdfFiles() As String = { "doc1.pdf", "doc2.pdf", "doc3.pdf" }
Parallel.ForEach(pdfFiles, Sub(pdfFile)
Dim pdf = IronPdf.PdfDocument.FromFile(pdfFile)
Dim text As String = pdf.ExtractText()
System.IO.File.WriteAllText($"extracted_{pdfFile}.txt", text)
End Sub)
End Sub
End Class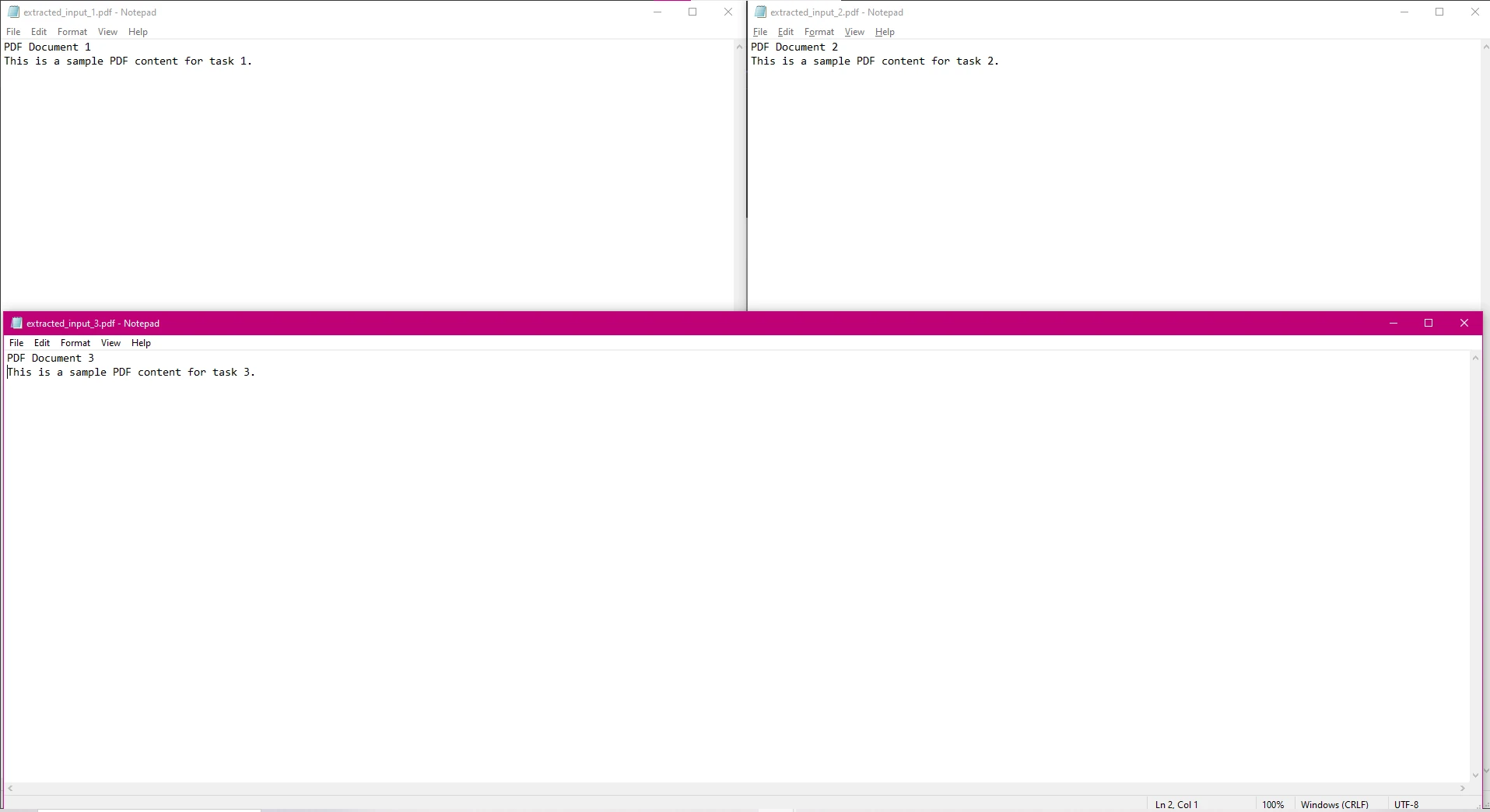
このコードでは、各PDFファイルが並行して処理され、テキストが抽出され、抽出されたテキストは個別のテキストファイルに保存されます。
この例では、複数のHTMLファイルのリストから並行して複数のPDFを生成します。これは、複数の動的HTMLページをPDF文書に変換する必要がある一般的なシナリオです。
using IronPdf;
string[] htmlFiles = { "example.html", "example_1.html", "example_2.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
try
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlFileAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
Console.WriteLine($"PDF created for {htmlFile}");
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {htmlFile}: {ex.Message}");
}
});using IronPdf;
string[] htmlFiles = { "example.html", "example_1.html", "example_2.html" };
Parallel.ForEach(htmlFiles, htmlFile =>
{
try
{
// Load the HTML content into IronPDF and convert it to PDF
ChromePdfRenderer renederer = new ChromePdfRenderer();
PdfDocument pdf = renederer.RenderHtmlFileAsPdf(htmlFile);
// Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf");
Console.WriteLine($"PDF created for {htmlFile}");
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {htmlFile}: {ex.Message}");
}
});Imports IronPdf
Private htmlFiles() As String = { "example.html", "example_1.html", "example_2.html" }
Parallel.ForEach(htmlFiles, Sub(htmlFile)
Try
' Load the HTML content into IronPDF and convert it to PDF
Dim renederer As New ChromePdfRenderer()
Dim pdf As PdfDocument = renederer.RenderHtmlFileAsPdf(htmlFile)
' Save the generated PDF to the output folder
pdf.SaveAs($"output_{htmlFile}.pdf")
Console.WriteLine($"PDF created for {htmlFile}")
Catch ex As Exception
Console.WriteLine($"Error processing {htmlFile}: {ex.Message}")
End Try
End Sub)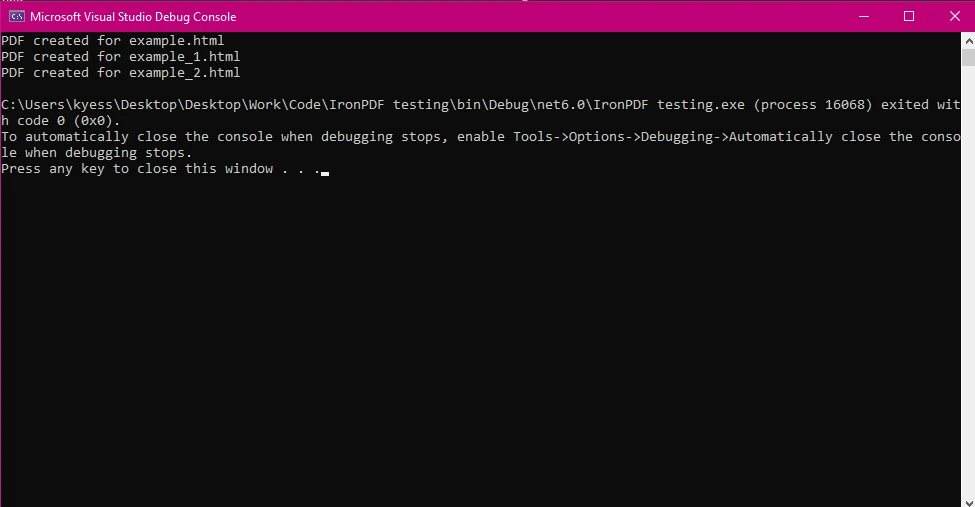
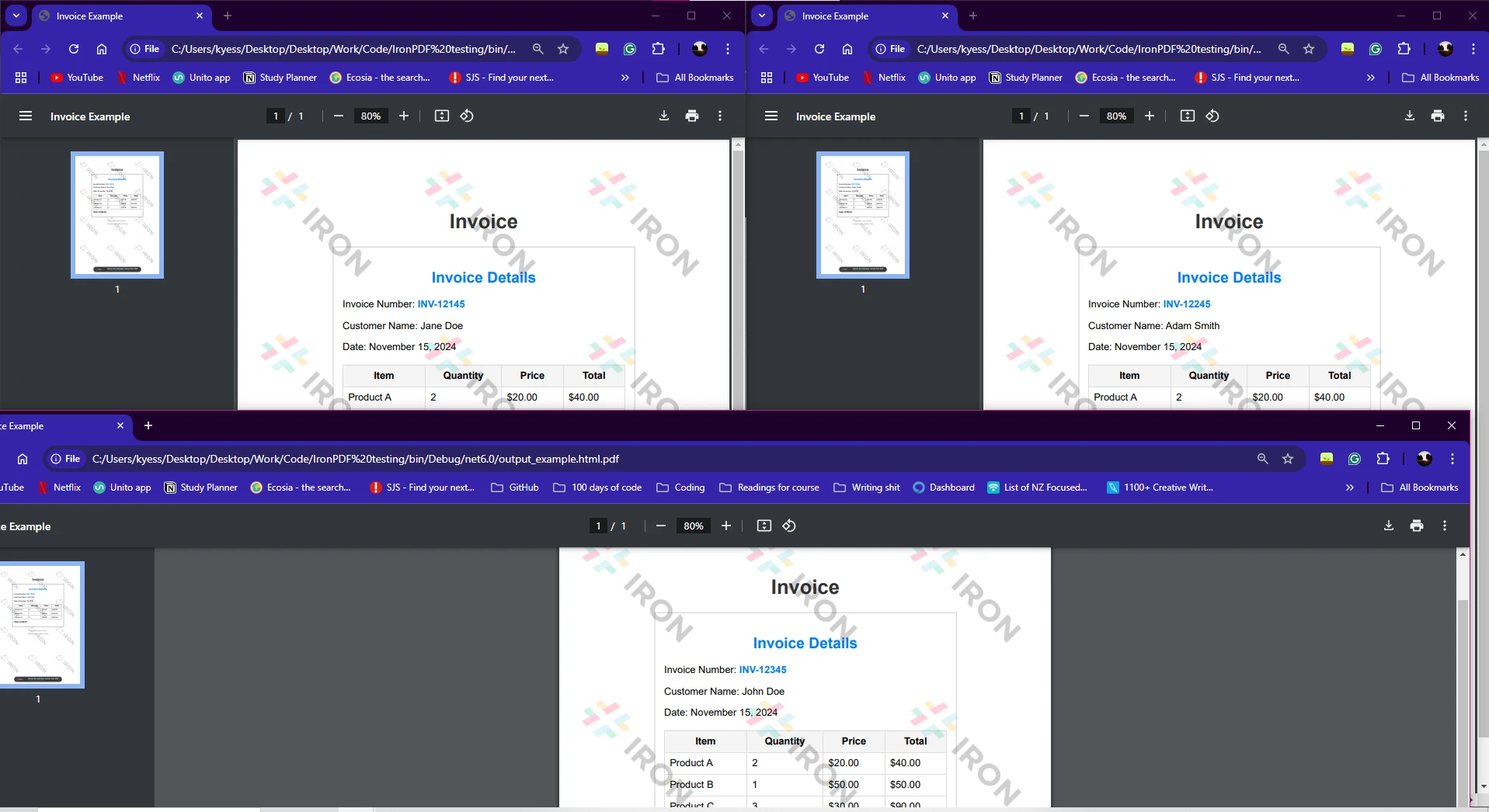
HTMLファイル: 配列htmlFilesには、PDFに変換したい複数のHTMLファイルへのパスが含まれています。
Parallel.ForEach(htmlFiles, htmlFile => {...}) は各HTMLファイルを同時に処理するため、複数のファイルを扱う際の操作が高速化されます。
PDFの保存: PDFを生成した後、pdf.SaveAsメソッドを使用して保存され、出力ファイル名に元のHTMLファイル名が追加されます。
IronPDFは、ほとんどの操作でスレッドセーフです。 しかし、同じファイルに並行して書き込むような操作は、問題を引き起こす可能性があります。 各並列タスクが別々の出力ファイルまたはリソースで動作するように常に確保してください。
パフォーマンスを最適化するために、並列度を制御することを検討してください。 大規模データセットの場合、システムの過負荷を防ぐために同時実行スレッド数を制限することを検討してください。
var options = new ExecutionDataflowBlockOptions
{
MaxDegreeOfParallelism = 4
};var options = new ExecutionDataflowBlockOptions
{
MaxDegreeOfParallelism = 4
};Dim options = New ExecutionDataflowBlockOptions With {.MaxDegreeOfParallelism = 4}多数のPDFを処理する際は、メモリ使用量に注意してください。 PdfDocumentオブジェクトなどのリソースは、不要になったらできるだけ早く解放するようにしてください。
拡張メソッドは、既存の型のソースコードを変更せずに新しい機能を追加できる特別な種類の静的メソッドです。 これは、IronPDFのようなライブラリを使用する場合に役立ちます。特に、PDFの処理をより便利にするためにカスタム処理メソッドを追加したり、並列処理のシナリオでその機能を拡張したりする場合に有用です。
拡張メソッドを使用することで、並列ループのロジックを簡素化し、簡潔で再利用可能なコードを作成できます。 このアプローチは重複を減らすだけでなく、特に複雑なPDFワークフローやデータの並列処理を扱う際に、クリーンなコードベースを維持するのにも役立ちます。
以下を使用した並列ループParallel.ForEachIronPDF大容量のPDFを処理する際に、著しいパフォーマンス向上を提供します。 HTMLをPDFに変換する場合、テキストを抽出する場合、またはドキュメントを操作する場合、データ並列性により、タスクを同時に実行することでより速い実行が可能になります。 並列アプローチは、操作が複数のコアプロセッサーにわたって実行できることを保証し、それによって全体の実行時間を短縮し、バッチ処理タスクのパフォーマンスを向上させます。
並列処理はタスクの速度を上げますが、スレッドの安全性とリソース管理に注意してください。 IronPDFはほとんどの操作でスレッドセーフですが、共有リソースにアクセスする際の潜在的な競合に対処することが重要です。 アプリケーションがスケールする際に、特に安定性を確保するためにエラーハンドリングとメモリ管理を検討してください。
IronPDFの詳細と高度な機能を探索する準備ができたら、公式ドキュメント購入を決定する前に、自分のプロジェクトでライブラリをテストすることができます。
Install-Package IronPdf
クレジットカードは不要です
試用キーはメールに送信されるはずです。![]() 試用版申し込みフォームが
試用版申し込みフォームが
正常に送信されました。
もし届かない場合は、
support@ironsoftware.comにお問い合わせください。
無料で始めましょう
クレジットカードは不要です
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
30日間、完全に機能する製品をご利用いただけます。
数分で稼働させることができます。
製品トライアル期間中にサポートエンジニアリングチームへの完全アクセス





![]() クレジットカードやアカウント作成は不要です。
クレジットカードやアカウント作成は不要です。
試用キーはメールにあるはずです。
もしない場合は、
support@ironsoftware.comまでご連絡ください。
30分の個別デモを予約する。
契約なし、カード情報不要、義務なし。


10 .NET API製品オフィスドキュメントのために