
ライブ環境でテストする
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
C# PDF ライブラリ
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


C#では文字列ユーザー入力、ファイル名からのデータ処理、またはレポート用の動的コンテンツの生成においても、操作は不可欠なスキルです。 一般的な作業の一つは、さらに処理するために文字列の特定の部分、例えば最後の文字を抽出することです。
ツールのようなもので作業する際にIronPDF文字列やHTMLデータからPDFを動的に生成できるため、文字列操作をマスターすることがさらに価値を増します。 この記事では、C#で文字列の最後の文字を抽出する方法を探り、その知識をIronPDFと組み合わせて強力で動的なPDFを作成する方法について説明します。
文字列操作は多くのプログラミング作業の中核を成す要素です。 以下は、文字列処理が重要となる一般的なシナリオのいくつかです:
バリデーションとフィルタリング: 文字列メソッドを使用して、入力を検証したり、パターンを抽出したり、データを分類したりすること。
たとえば、ユーザー名や製品コードのリストからレポートを生成しており、これらを末尾の文字に基づいてグループ化または分類する必要があるとします。 これは、文字列の最後の文字を抽出することが役立つ場面です。
C#では、文字列は文字のゼロインデックス配列です。つまり、最初の文字はインデックス0にあり、最後の文字はインデックスstring.Length - 1にあります。文字列の最後の文字を抽出するいくつかの方法を以下に示します。
サブストリング()メソッドは、インデックス位置に基づいて文字列の一部を抽出することを可能にします。 文字列の最後の文字変数を取得する方法は次のとおりです。
// original string
string mystring = "Example";
// Retrieving the letter 'e' from the above string example's ending character
char lastChar = mystring.Substring(input.Length - 1, 1)[0];
Console.WriteLine(lastChar); // new string/char: 'e'// original string
string mystring = "Example";
// Retrieving the letter 'e' from the above string example's ending character
char lastChar = mystring.Substring(input.Length - 1, 1)[0];
Console.WriteLine(lastChar); // new string/char: 'e'' original string
Dim mystring As String = "Example"
' Retrieving the letter 'e' from the above string example's ending character
Dim lastChar As Char = mystring.Substring(input.Length - 1, 1).Chars(0)
Console.WriteLine(lastChar) ' new string/char: 'e'
別のアプローチとして、配列インデックスを使用して直接指定された文字位置にアクセスする方法があります。
string input = "Example";
char outputChar = input[input.Length - 1];
Console.WriteLine(outputChar); // Character removed: 'e'string input = "Example";
char outputChar = input[input.Length - 1];
Console.WriteLine(outputChar); // Character removed: 'e'Dim input As String = "Example"
Dim outputChar As Char = input.Chars(input.Length - 1)
Console.WriteLine(outputChar) ' Character removed: 'e'
^ 演算子は、配列や文字列の末尾から要素にアクセスするためのより簡潔な方法を提供します。 ^1 は最後の文字を示します。
string input = "Example";
char lastChar = input[^1];
Console.WriteLine(lastChar); // Output: 'e'string input = "Example";
char lastChar = input[^1];
Console.WriteLine(lastChar); // Output: 'e'Dim input As String = "Example"
Dim lastChar As Char = input.Chars(^1)
Console.WriteLine(lastChar) ' Output: 'e'
この文字列操作を実際の状況で適用してみましょう。 商品コードのリストがあり、各コードから最後の文字を抽出してPDFレポートに使用したいとします。
List<string> productCodes = new List<string> { "ABC123", "DEF456", "GHI789" };
foreach (var code in productCodes)
{
char lastChar = code[^1];
Console.WriteLine($"Product code: {code}, Last character: {lastChar}");
}List<string> productCodes = new List<string> { "ABC123", "DEF456", "GHI789" };
foreach (var code in productCodes)
{
char lastChar = code[^1];
Console.WriteLine($"Product code: {code}, Last character: {lastChar}");
}Dim productCodes As New List(Of String) From {"ABC123", "DEF456", "GHI789"}
For Each code In productCodes
Dim lastChar As Char = code.Chars(^1)
Console.WriteLine($"Product code: {code}, Last character: {lastChar}")
Next code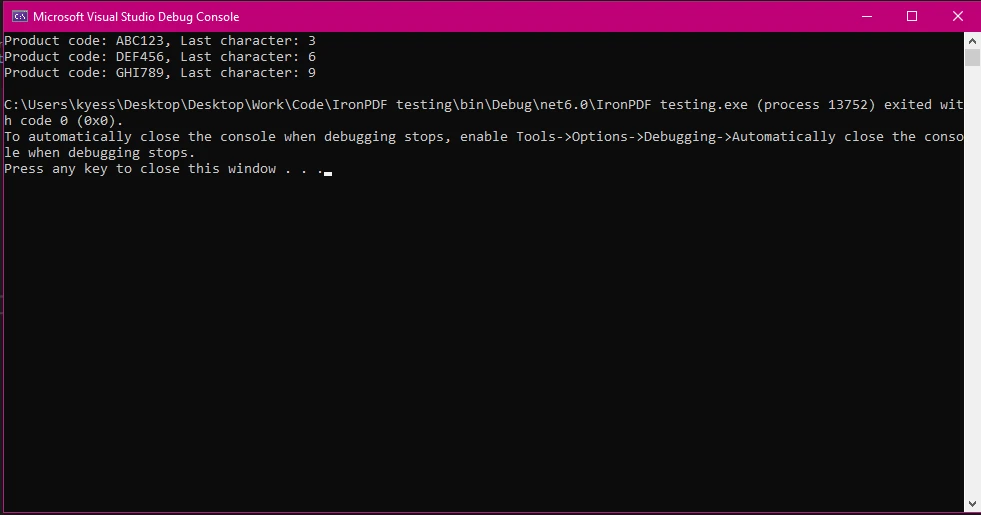
使用を開始するにはIronPDF、最初にそれをインストールする必要があります。 すでにインストールされている場合は、次のセクションに進むことができます。そうでない場合は、以下の手順がIronPDFライブラリのインストール方法を説明しています。
にIronPDF をインストールするNuGetパッケージマネージャーコンソールを使用して、Visual Studioを開き、パッケージマネージャーコンソールに移動します。 次に、以下のコマンドを実行します。
Install-Package IronPdfInstall-Package IronPdf'INSTANT VB TODO TASK: The following line uses invalid syntax:
'Install-Package IronPdfVisual Studioを開き、「ツール -> NuGet パッケージマネージャー -> ソリューションのNuGetパッケージを管理」に移動し、IronPDFを検索します。 ここからは、プロジェクトを選択して「インストール」をクリックするだけで、IronPDF がプロジェクトに追加されます。
IronPDFをインストールしたら、IronPDFを使用するために必要なのはコードの先頭に正しいusingステートメントを追加することだけです。
using IronPdf;using IronPdf;Imports IronPdf各製品コードから最後の文字を抽出したので、これらの文字を含むPDFレポートを作成しましょう。 基本的な例を示します:
using IronPdf;
List<string> productCodes = new List<string> { "ABC123", "DEF456", "GHI789" };
ChromePdfRenderer renderer = new ChromePdfRenderer();
string htmlContent = "<h1>Product Report</h1><ul>";
foreach (var code in productCodes)
{
char lastChar = code[^1];
htmlContent += $"<li>Product code: {code}, Last character: {lastChar}</li>";
}
htmlContent += "</ul>";
PdfDocument pdf = renderer.RenderHtmlAsPdf(htmlContent);
pdf.SaveAs("ProductReport.pdf");using IronPdf;
List<string> productCodes = new List<string> { "ABC123", "DEF456", "GHI789" };
ChromePdfRenderer renderer = new ChromePdfRenderer();
string htmlContent = "<h1>Product Report</h1><ul>";
foreach (var code in productCodes)
{
char lastChar = code[^1];
htmlContent += $"<li>Product code: {code}, Last character: {lastChar}</li>";
}
htmlContent += "</ul>";
PdfDocument pdf = renderer.RenderHtmlAsPdf(htmlContent);
pdf.SaveAs("ProductReport.pdf");Imports IronPdf
Private productCodes As New List(Of String) From {"ABC123", "DEF456", "GHI789"}
Private renderer As New ChromePdfRenderer()
Private htmlContent As String = "<h1>Product Report</h1><ul>"
For Each code In productCodes
Dim lastChar As Char = code.Chars(^1)
htmlContent &= $"<li>Product code: {code}, Last character: {lastChar}</li>"
Next code
htmlContent &= "</ul>"
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdf(htmlContent)
pdf.SaveAs("ProductReport.pdf")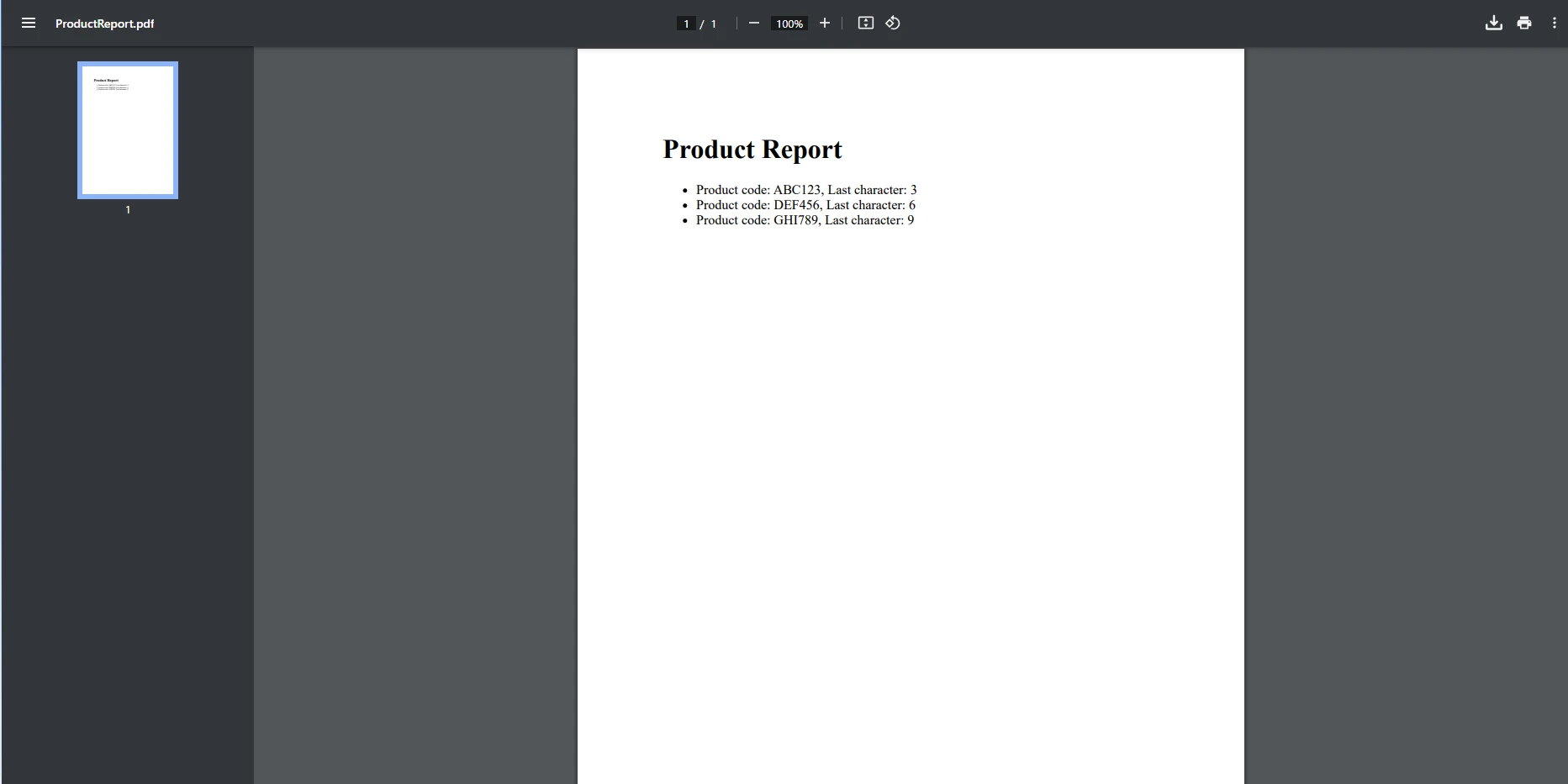
このコードは、各商品コードとその最終文字を一覧にしたPDFレポートを生成し、分類や分析を容易にします。 それを利用しますChromePdfRenderer以下のコンテンツを日本語に翻訳してください:PdfDocumentHTMLコンテンツをPDFドキュメントにレンダリングするクラス。 このHTMLコンテンツは、リストに保存されたデータを使用して動的に作成されました。
特定の基準に基づいてパターンを見つけたりデータをフィルタリングしたりするなど、より複雑な文字列操作については、正規表現を使用します。(正規表現)役に立つ。 たとえば、数字で終わるすべての製品コードを見つけたい場合があります。
using IronPdf;
class Program
{
public static void Main(string[] args)
{
List<string> productCodes = new List<string> { "ABC123", "DEF456", "GHI789", "GJM88J" };
Regex regex = new Regex(@"\d$");
foreach (var code in productCodes)
{
if (regex.IsMatch(code))
{
string htmlContent = $@"
<h1>Stock Code {code}</h1>
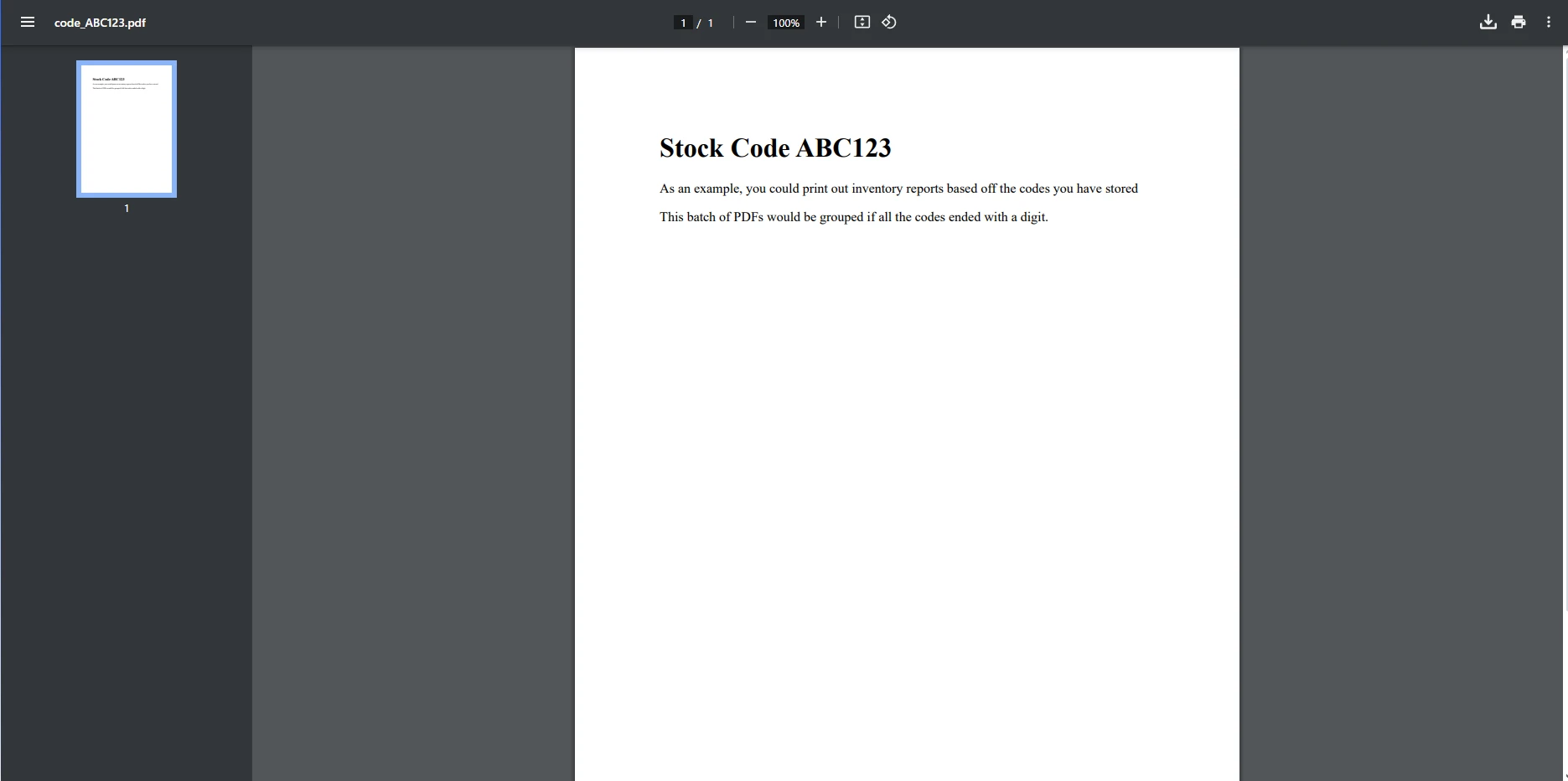
<p>As an example, you could print out inventory reports based off the codes you have stored</p>
<p>This batch of PDFs would be grouped if all the codes ended with a digit.</p>
";
ChromePdfRenderer renderer = new ChromePdfRenderer();
PdfDocument pdf = renderer.RenderHtmlAsPdf(htmlContent);
pdf.SaveAs($"code_{code}.pdf");
Console.WriteLine($"Product code: {code} ends with a digit.");
}
}
}
}using IronPdf;
class Program
{
public static void Main(string[] args)
{
List<string> productCodes = new List<string> { "ABC123", "DEF456", "GHI789", "GJM88J" };
Regex regex = new Regex(@"\d$");
foreach (var code in productCodes)
{
if (regex.IsMatch(code))
{
string htmlContent = $@"
<h1>Stock Code {code}</h1>
<p>As an example, you could print out inventory reports based off the codes you have stored</p>
<p>This batch of PDFs would be grouped if all the codes ended with a digit.</p>
";
ChromePdfRenderer renderer = new ChromePdfRenderer();
PdfDocument pdf = renderer.RenderHtmlAsPdf(htmlContent);
pdf.SaveAs($"code_{code}.pdf");
Console.WriteLine($"Product code: {code} ends with a digit.");
}
}
}
}Imports IronPdf
Friend Class Program
Public Shared Sub Main(ByVal args() As String)
Dim productCodes As New List(Of String) From {"ABC123", "DEF456", "GHI789", "GJM88J"}
Dim regex As New Regex("\d$")
For Each code In productCodes
If regex.IsMatch(code) Then
Dim htmlContent As String = $"
<h1>Stock Code {code}</h1>
<p>As an example, you could print out inventory reports based off the codes you have stored</p>
<p>This batch of PDFs would be grouped if all the codes ended with a digit.</p>
"
Dim renderer As New ChromePdfRenderer()
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdf(htmlContent)
pdf.SaveAs($"code_{code}.pdf")
Console.WriteLine($"Product code: {code} ends with a digit.")
End If
Next code
End Sub
End Class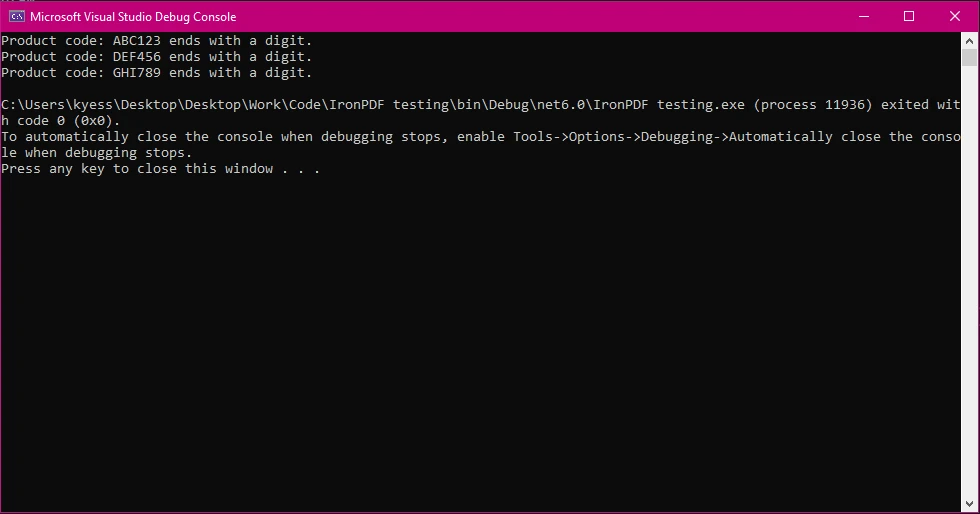
このコード例では、まず商品コードのリストを作成し、サンプルの文字列値で初期化します。("ABC123"、"DEF456"、など。). 目標は、各製品コードを評価し、数字で終わるものに対してPDFを生成することです。 正規表現(正規表現)数字で終わる文字列にマッチするように定義されています。 パターン \d$ の説明は以下の通りです。
$ は、数字が文字列の末尾にある必要があることを主張します。
foreachループは、productCodesリスト内の各製品コードを反復処理します。各コードに対して、**IsMatch()メソッドは、製品コードが数字で終わっているかどうかを確認します。(正規表現パターンに基づく). 条件が真である場合、ifブロック内のコードが実行されます。
使用ChromePdfRendererの RenderHtmlAsPdf().メソッドで、数字で終わるコードのPDFレポートを生成します。 これらの新しいPDFは、に保存されています。PdfDocument作成したオブジェクト。 それぞれが保存されますPdf.SaveAs(). それぞれのドキュメントが上書き保存されるのを防ぐために、コードネームを使用して異なる名前を作成しました。
PDFに文字列データを含める前に、それをフォーマットすることをお勧めします。 たとえば、空白をトリムしたり、文字を大文字に変換したり、またはそれらをキャピタライズすることができます。
string str= " example ";
string formatted = str.Trim().ToUpper(); // string result: "EXAMPLE"string str= " example ";
string formatted = str.Trim().ToUpper(); // string result: "EXAMPLE"Dim str As String= " example "
Dim formatted As String = str.Trim().ToUpper() ' string result: "EXAMPLE"
IronPDFは、PDFを楽に扱える強力な.NET PDFライブラリです。 簡単なインストールと多様な統合オプションのおかげで、あっという間にニーズに合ったPDFドキュメントを作成および編集することができます。
IronPDFは、文字列およびHTMLコンテンツからPDFを作成するプロセスをいくつかの方法で簡素化します。
Text Editing: IronPDFを使用して指定されたテキストを数行のコードで赤くします。
IronPDFの実際の動作をもっと見たいですか? 必ず詳しい情報を確認してください。ハウツーガイド以下のコンテンツを日本語に翻訳してください:コード例この強力なライブラリ用。
IronPDFは.NETおよびC#とシームレスに統合されており、既存のプロジェクトと一緒に、その強力なPDF生成機能を活用できます。 非同期操作をサポートしており、大規模またはパフォーマンスが重要なアプリケーションに理想的です。
文字列操作は、基本的なデータ処理から動的なPDFの生成のような高度なタスクに至るまで、多くのC#アプリケーションで重要な役割を果たす基本的なスキルです。 この記事では、データの分類、入力の検証、レポート用コンテンツの準備などのシナリオで頻繁に発生する、任意のローカルまたはパブリック文字列から最後の文字を抽出するいくつかの方法を探求しました。 また、IronPDFを使用して動的なPDFドキュメントを作成する方法についても探りました。 サブストリングを使用したかどうか()、配列のインデックス指定、またはC# 8.0で導入されたモダンな^1演算子を使用して、プロのようにC#で文字列を操作できるようになります。
IronPDFは、その使いやすさと多様性で際立っており、.NET環境でPDFを扱う開発者にとって最適なツールです。 大量のデータを処理することから非同期操作をサポートすることまで、IronPDFはプロジェクトのニーズに合わせて拡張でき、テキスト抽出、透かし、カスタムヘッダーとフッターなどを処理するための豊富な機能セットを提供します。
文字列操作とPDF生成がどのように一緒に使用できるかを見たので、自分自身で試してみましょう。! ダウンロード無料試用IronPDFを使用して、文字列データを美しくフォーマットされたPDFに変換し始めましょう。 レポート、請求書、またはカタログを作成する際に、IronPDFはドキュメント生成プロセスを向上させるのに必要な柔軟性と力を提供します。
Install-Package IronPdf
クレジットカードは不要です
試用キーはメールに送信されるはずです。![]() 試用版申し込みフォームが
試用版申し込みフォームが
正常に送信されました。
もし届かない場合は、
support@ironsoftware.comにお問い合わせください。
無料で始めましょう
クレジットカードは不要です
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
30日間、完全に機能する製品をご利用いただけます。
数分で稼働させることができます。
製品トライアル期間中にサポートエンジニアリングチームへの完全アクセス





![]() クレジットカードやアカウント作成は不要です。
クレジットカードやアカウント作成は不要です。
試用キーはメールにあるはずです。
もしない場合は、
support@ironsoftware.comまでご連絡ください。
30分の個別デモを予約する。
契約なし、カード情報不要、義務なし。


10 .NET API製品オフィスドキュメントのために