
ライブ環境でテストする
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
C# PDF ライブラリ
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


このチュートリアルでは、どのようにするかを見ていきますテキストを抽出PDFから(ポータブルドキュメントフォーマット)C#で2つの異なるPDFライブラリを使用してドキュメントを作成します。
現代のウェブ時代において、PDFファイルからテキストや画像を抽出して解析や読み取りを行うことができるライブラリが数多く存在します。 今日は、2つの強力なPDFライブラリを使用します。IronPDF以下のコンテンツを日本語に翻訳してください:クエストPDF、PDFファイルからテキストを抽出するために。これら2つのライブラリが簡単なテキスト抽出タスクをどのように処理するかを比較することで、そのような高度なPDFタスクの処理にどちらがより適しているかを判断できます。 比較セクションに入る前に、それぞれのライブラリの簡単な紹介を見てみましょう。
QuestPDFは、特に.NET開発者向けに設計された先進的なオープンソースのPDF生成ライブラリです。 それは、ユーザーが高い柔軟性と精度を持って複雑なPDFレイアウトを定義および生成できるモダンな宣言的APIを利用します。 QuestPDFの主な焦点はテキスト抽出ではなくドキュメント生成にありますが、ゼロからドキュメントを作成し、ドキュメント内のさまざまな要素を操作するための、わかりやすく直感的なアプローチを提供します。 これは、カスタマイズされた動的なPDFコンテンツを必要とするアプリケーションに特に適しています。
IronPDFは、.NETおよびJava、Python、Node.jsでPDFを生成、編集、読み取るための強力なツールです。プログラマー向けに最適化されており、コードからPDFファイルの作成を容易に行うことができます。IronPDFは、HTML、CSS、JavaScript、および画像をPDFドキュメントに変換する能力を提供します。
IronPDFは様々なライセンスオプションがあり、Lite License、Plus License、Professional License、Unlimited Licenseが用意されています。
技術サポートや詳細については、Iron Softwareの公式サイトをご覧ください。
申し訳ありませんが、翻訳するコンテンツのテキストを提供してください。その後、英語から日本語に翻訳いたします。!-- 壊れた画像 Pixabayから追加、ファイルから選択、またはここに画像をドラッグアンドドロップします。 -->
IronPDFは、C#でのPDF操作をより簡単かつ効率的にするために設計された多用途のPDF処理ライブラリです。 QuestPDFとは異なり、IronPDFはPDFの生成と操作の両方に特化して構築されています。 提供する機能にはPDFが含まれています暗号化 (あんごうか)編集のための広範なサポート注釈付け既存のPDF、さまざまなドキュメントをPDF形式に変換、追加ヘッダーとフッター (ページ番号を表示するために使用できます)、ドキュメントメタデータの編集、マルチスレッドおよび非同期サポート、高度なPDF変換ツール。
豊富な機能セットに加え、IronPDFは.NET 5/6/7、.NET Core、.NET Frameworkをサポートすることにより、完全なクロスプラットフォームサポートを提供します。 また、Windows、macOS、Linux、およびAzureやAWSのようなクラウドプラットフォームとも完全に互換性があるため、クロスプラットフォームの.NETアプリケーションに最適な選択となります。
今日の例では、両方のライブラリを使用して、例の請求書PDFドキュメントからテキストを抽出します。
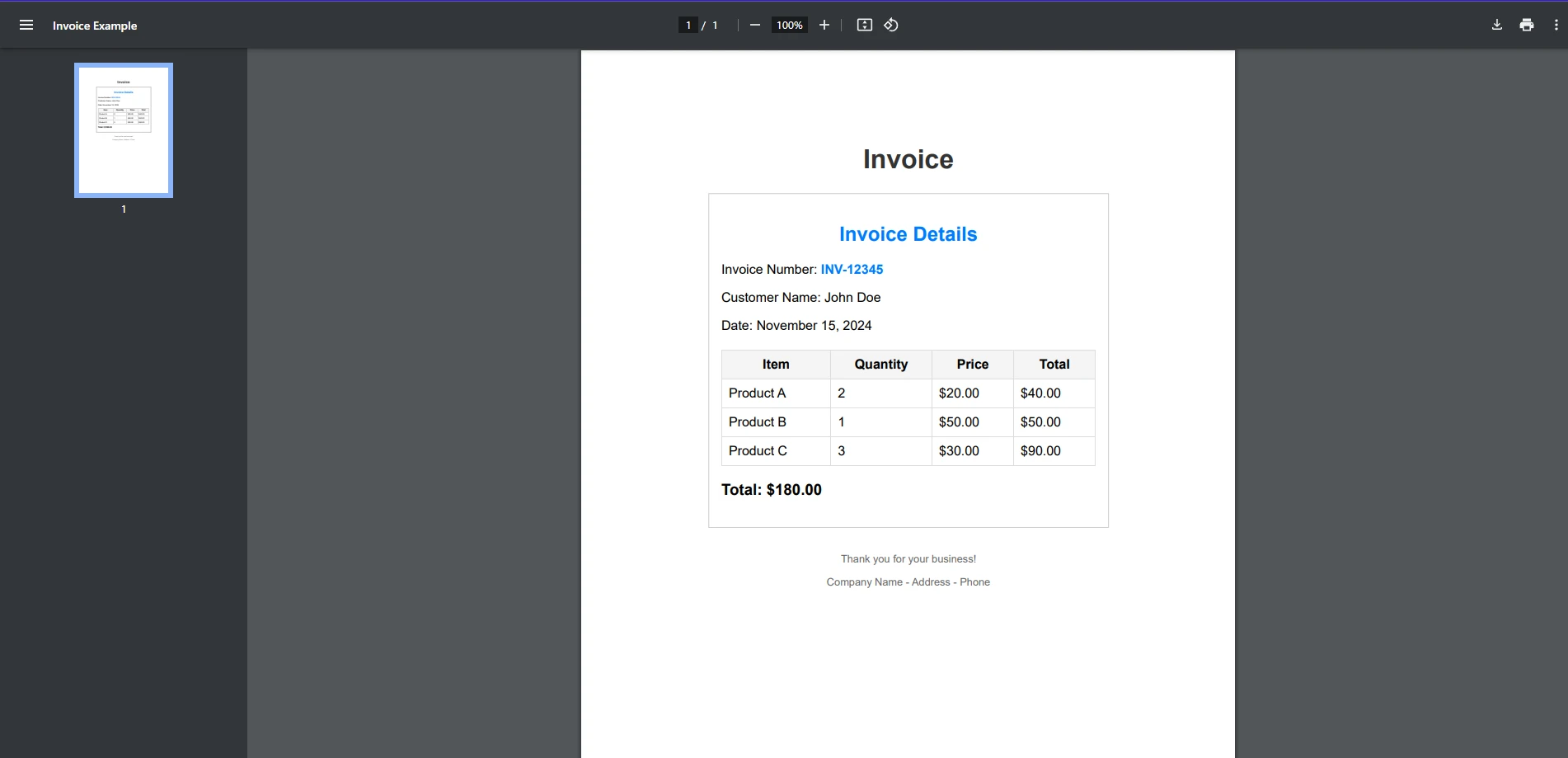
まず、QuestPDFがこのタスクを処理できるかどうかを見ていきます。
残念ながら、QuestPDFはPDF作成や特定のPDFタスクのパフォーマンスに優れていますが、テキスト抽出は現在提供されている機能に含まれていません。 QuestPDFは既存のPDFファイルからテキストを抽出するように設計されているわけではありませんが、PDFを扱うための基本的なツールを提供しており、追加のロジックやサードパーティの統合によってテキスト抽出を拡張することができます。 例えば、QuestPDFを使用して構造化されたコンテンツを持つPDFドキュメントを生成し、サードパーティのライブラリを使用してドキュメントの構造に基づいてコンテンツを抽出するためのカスタムソリューションを実装することができます。
テキスト抽出PDFの操作に関して、IronPDFが得意とするタスクの1つは、わずか数行のコードでPDFドキュメント全体からテキストを抽出できることです。 これは次のコードスニペットで見ることができます:
using IronPdf;
public class Program
{
public static void main(string[] args)
{
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
string text = pdf.ExtractAllText();
Console.WriteLine(text);
}
}using IronPdf;
public class Program
{
public static void main(string[] args)
{
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
string text = pdf.ExtractAllText();
Console.WriteLine(text);
}
}Imports IronPdf
Public Class Program
Public Shared Sub main(ByVal args() As String)
Dim pdf As PdfDocument = PdfDocument.FromFile("exampleInvoice.pdf")
Dim text As String = pdf.ExtractAllText()
Console.WriteLine(text)
End Sub
End Class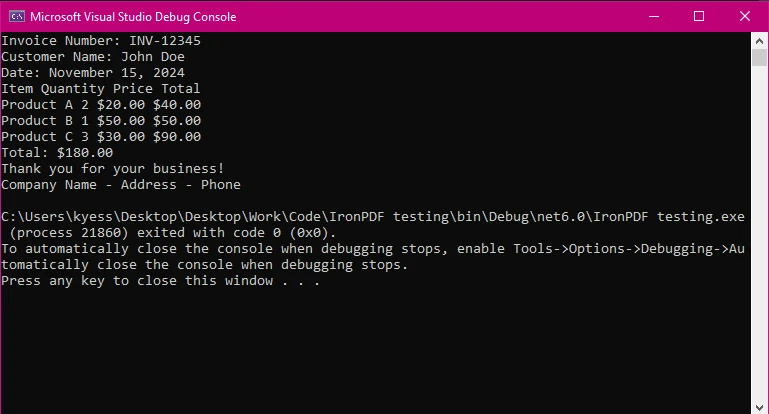
IronPDFはテキストを抽出するためのシンプルなAPIを提供しており、効率を重視する開発者にとって理想的です。 わずか3行で、PDFドキュメント内のテキストコンテンツを抽出して表示し、読むことができました。 ここから、抽出されたテキストを簡単に保存して、さらに使用したり操作したりできます。
一方、QuestPDFは、IronPDFのようなライブラリに比べて機能が限られているため、テキスト抽出のようなタスクを処理することができませんでした。 PDFの生成や基本的な操作など他のタスクを処理できますが、テキストを抽出するためには外部ライブラリを実装する必要があります。
に関してはテキストの抽出. QuestPDFは、プライベートプロジェクトに対してそのコミュニティライセンスを使用することで無料ですが、商用ライセンス.
どちらのライブラリも正確で信頼性がありますが、最終的にはプロジェクトの要件に依存します。
これらのライブラリのより詳細な比較については、ブログ全体をチェックしてください。IronPDF対QuestPDF.
Install-Package IronPdf
クレジットカードは不要です
試用キーはメールに送信されるはずです。![]() 試用版申し込みフォームが
試用版申し込みフォームが
正常に送信されました。
もし届かない場合は、
support@ironsoftware.comにお問い合わせください。
無料で始めましょう
クレジットカードは不要です
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
30日間、完全に機能する製品をご利用いただけます。
数分で稼働させることができます。
製品トライアル期間中にサポートエンジニアリングチームへの完全アクセス





![]() クレジットカードやアカウント作成は不要です。
クレジットカードやアカウント作成は不要です。
試用キーはメールにあるはずです。
もしない場合は、
support@ironsoftware.comまでご連絡ください。
30分の個別デモを予約する。
契約なし、カード情報不要、義務なし。


10 .NET API製品オフィスドキュメントのために